


May 15, 2014
Three Key Data Types for Hadoop Analytics

One of the great things about Hadoop is the openness and flexibility of HDFS. You can store practically any type of data that you want in Hadoop, which has forever changed the economics of data storage. But when it comes to running commercial analytic workloads in Hadoop, some data types are proving more popular and profitable than others, according to analytic software developer Platfora.
The folks at Platfora have a front-row seat to view how companies are using real-world Hadoop clusters. The San Mateo, California company has been selling its business analytic product for just over a year, but already has scored some big customer wins, including Citi, Autotrader, Disney, Comcast, American Express, DirecTV, and the Washington Post.
Platfora has noticed a pattern emerging across many of its customer engagements in terms of the type of data they’re analyzing. According to Platfora vice president of product Peter Schlampp, the three main data types occupying customers’ clusters are transactional data, customer interaction (or clickstream) data, and machine data from the Internet of Things (IoT).
- Transactional Data. This highly normalized data type normally isn’t associated with “big data” storage problems, but without the data of record from an e-commerce or ERP application, it’s tough to know where to start.
- Customer Interaction Data. “The data set we see that’s the poster child is Web click data,” Schlampp says. “People have been generating that data for some time but it’s normally stored in proprietary custom Web analytics solutions and not necessarily tried to mix with the data warehouse with the transactional data.”
- Machine Data. Data generated by machines–such as Web server logs, call detail records (CDRs), securities trading, and security device logs–is increasingly finding its way into Hadoop clusters.
“You have these three classes of data people are trying to bring together and analyze,” Schlampp says. “Platfora’s ability to use the multi-dimensional model on these data sets and combine these three different worlds—transactions, customer interactions, and machine data–that’s our sweet spot.”
Traditional approaches to utilizing these data types would have involved large enterprise data warehouses, business intelligence and visualization tools, and armies of IT specialists. However, that approach was slow, expensive, and limiting, in that only the tip of the iceberg of actual data was used, Schlampp says. But given the speed of the data being generated and the variety, there’s a real need to go to the bottom of the iceberg.
Hadoop is proving itself very useful in allowing users to analyze the entire iceberg of data. Platfora is one of a handful of companies selling end-to-end analytic tools that plug into Apache Hadoop and allow business analysts to explore their entire data iceberg without having advanced programming and statistical skills.
The Platfora product presents a drag-and-drop interface where analysts can select the data they want to analyze. From these definitions, the software automatically generates MapReduce jobs that create so-called data “lenses” that allow users to spot patterns and connections in their Hadoop-resident various data. The in-memory product also includes “vizboards” that are interactive visualizations that allow customers to explore their data.
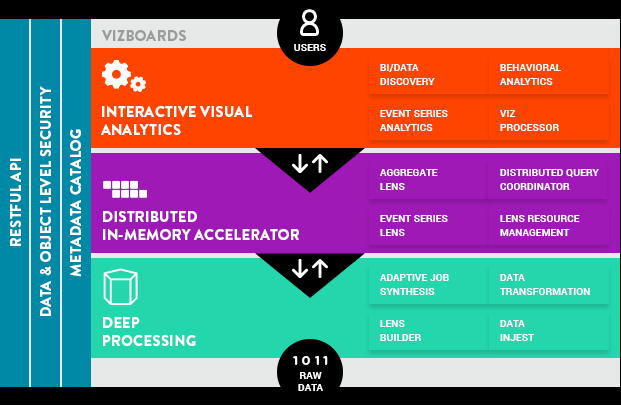
The Platfora product stack
Customers tend to build three main types of analytic apps with Platfora, including customer analytic solutions, network security solutions, and IoT solutions. One common use of the tool is generating big-picture ROI reports on individual customers that combine transactional data, Web log data, and advertising data.
“The only way to do that is to combine data that data into a single place,” Schlampp says. “To do that with [enterprise data warehouses and BI tools] is a $10-million project. But to do it in Hadoop and Platfora, it’s much faster and considerably less expensive, and the next question you have after that is much easier to answer as well.”
The growth in use of non-transactional data types–such as customer interactions and machine data –in customer applications surprised the folks at Platfora. In response, Platfora added several new capabilities with version 3.5 aimed at addressing the variety-of-data-types problem.
For starters, it made some of the data transformation features in the product easier to use. “Eighty percent of the problem is getting the data into shape to actually use it,” Schlampp says. “It’s a complex task and being able to work with raw data is difficult.”
The company isn’t trying to replicate the kind of automated data transformation capabilities that are offered by other companies, like Trifacta. In fact, many of Platfora’s customers are looking to use Trifacta’s Hadoop-resident data cleansing tool with their Platfora implementations, which reside next to Hadoop clusters in memory-optimized servers, Schlampp says.
Platfora also added a programmatic query interface that allows users to expose data using REST Web service calls and SQL-like syntax. This will be useful for customers who want to analyze their data using other tools, such as the R language or statistical tools from SAS. “We bring the data out of Hadoop into in our in-memory lenses. And now you’ll able to write queries directly against those lenses and get sub-second interactivity against then,” Schlampp says.
In other news, Platfora is researching the feasibility of using the in-memory Apache Spark framework as its underlying data engine in Hadoop. “We’re very much in support in Spark and we see a path to be able to run Platfora on top of Spark and not use MapReduce,” Schlampp says. “I think there’s maturity to come with the project. We’re still finding bugs and issues in Spark that we’re driving back to the community to have addressed. But it is something we’re actively pursuing.”
Related Items:
Five Steps to Drive Big Data Agility
Standing on the Shoulders of (Hadoop) Giants
Your Refrigerator is Full…of Big Data
Technologies:
Middleware
Vendors:
Platfora
Leading Solution Providers
















