


February 11, 2014
MapR Embraces Co-Existence with Hadoop Update
MapR Technologies today unveiled new products based on the Hadoop version 2 codebase that it says will allow customers to continue to run MapReduce version 1 applications while also reaping the rewards of a post-YARN Hadoop world. The company also announced the capability to run the HP Vertica columnar analytic database directly on its Hadoop stack.
![]() MapR has been working since the October release of Hadoop version 2 to mesh the extensive modifications it has made to Hadoop’s core with the new world order as defined by YARN. That work is now done and is being released as a regular monthly update across its product lineup, which includes M3, M5, and M7.
MapR has been working since the October release of Hadoop version 2 to mesh the extensive modifications it has made to Hadoop’s core with the new world order as defined by YARN. That work is now done and is being released as a regular monthly update across its product lineup, which includes M3, M5, and M7.
The company says its latest Hadoop distribution will continue to run the first generation of Hadoop apps right alongside the newer apps developed for YARN. It also claims that it’s the only Hadoop distribution that pairs a general purpose storage platform–enabled through its support for the Unix-like Network File System (NFS)–with YARN.
“We understand the people using Hadoop today have a lot of investment in MapReduce 1.0,” MapR’s chief marketing officer Jack Norris tells Datanami. “Instead of doing just a cold change with MapR, they can run both simultaneously on the same platform. So you can run your existing MapReduce jobs as well as YARN jobs, on the same nodes in the cluster, and do that simultaneously.”
That backward compatibility will be welcomed by organizations that are slowly adopting the new Hadoop 2 and YARN paradigm, but who don’t want to be forced to extensive modifications to their older Hadoop applications to get them to run on the newer Hadoop 2/YARN platform.
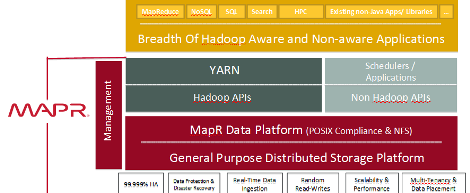 In addition to running older MapReduce code on the same platform as newer YARN-compatible code, MapR touts the capability to inherit all of the benefits that are derived from the modifications that MapR made to Hadoop. MapR, you will remember, rewrote much of the technical underpinnings of Hadoop with the goal of eliminating some of the technical dependencies and performance limitations that Hadoop impinged on applications. It also added its own layer of data replication, security, and compliance capabilities.
In addition to running older MapReduce code on the same platform as newer YARN-compatible code, MapR touts the capability to inherit all of the benefits that are derived from the modifications that MapR made to Hadoop. MapR, you will remember, rewrote much of the technical underpinnings of Hadoop with the goal of eliminating some of the technical dependencies and performance limitations that Hadoop impinged on applications. It also added its own layer of data replication, security, and compliance capabilities.
Those modifications provide MapR’s distribution with the capability to perform random reads and writes to NFS, as opposed to Hadoop’s standard appending of HDFS, which Norris likened to a CD-ROM. And MapR’s C and C++ retrofit also brought about POSIX compliance, giving customers the ability to run applications originally written in Microsoft’s C/C++ or Python for Unix servers directly on their MapR Hadoop platforms. The company also cut out much of the back-and-forth that occurs with table lookups, enabling HBase to run in a continuous manner.
MapR also used Strata to announce that HP’s Vertica database can now run inside MapR’s Hadoop distribution. “Organizations embracing Hadoop have been struggling to empower large groups of business analysts who require sophisticated SQL and BI tools to do their jobs, but feel hand-cuffed when using incomplete, SQL-like approaches,” MapR CEO and co-founder John Schroeder says in a statement.
The reference to “SQL-like” is a clear dig at MapR’s competitors, notably Cloudera and Hortonworks, who have expended lots of resources to enable SQL access to data stored in their Hadoop distributions–Cloudera through its Impala offering and Hortonworks through its Hive project to improve native Hive function. Vertica will be available on MapR next month.
Lastly, the company unveiled the MapR Sandbox, which is a free, downloadable instance of MapR’s Hadoop distribution that a customer can install in a virtual machine on their laptop or desktop. Users can drag and drop any files into the MapR Sandbox, which the company says is useful for training, development, and testing purposes.
Related Items:
MapR CEO Predicts Major Developments That Will Drive Big Data and Hadoop in 2014
Reaping the Fruits of Hadoop Labor in 2014
MapR Unveils Strong Authentication for Hadoop
Applications:
Data Mining
Vendors:
MapR
Leading Solution Providers
















