


October 8, 2013
Teradata Adds Graph Engine to the Data Discovery Mix with Aster 6
It’s not enough today to have a single view of one’s data. To that end, Teradata announced that it’s added a graph engine to its Aster data discovery platform, giving customers the capability to explore their data using a combination of graph, MapReduce, and SQL interfaces.
![]()
Teradata’s new SQL-GR graph engine is based on the Bulk Synchronous Parallel (BSP) technology that originated at Google. Like other graphing engines, SQL-GR is designed to allow customers to establish connections among various entities stored in the database, which could represent anything from a particular customer to a bank account to a fine French Bordeaux, and are often stored in unstructured or semi-structured formats.
Graphing engines in general have become popular because they provide another way to make sense out of massive amounts of unstructured and semi-structured data, like emails, Web logs, machine data, and sensor data. Graphing engines are good at identifying patterns in the data that might otherwise be difficult to spot using traditional SQL or even MapReduce.
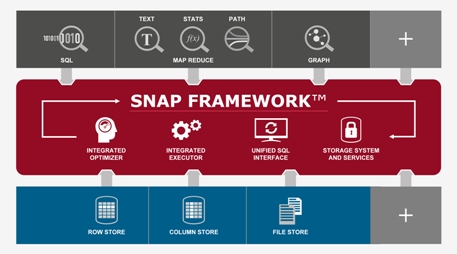
What makes SQL-GR special is the way in which it’s been integrated into the Aster platform. The company calls this its SNAP framework. Just like the other analytical engines in Aster–namely, MapReduce and SQL–the SQL-GR graphing engine can be accessed through good old SQL, according to Manan Goel, senior director of product marketing at Teradata Aster.
According to Goel, the SNAP framework, enables multiple data analytic engines and data stores to work seamlessly in an integrated manner through a unified SQL interface “Even if a business or data analyst just knows SQL, he can leverage these new analytic techniques like MapReduce and graph do much more interesting analytics and derive much richer and more powerful insights from the data,” explains Goel.
Prior to this release, Aster had a purely relational data store. With version 6, it added a new file-based data store to keep the semi-structured and unstructured data. “The intent is to quickly ingest multi-structured data–like email, JSON, or Web log–into the platform and then start doing discovery and analytics on top of that data, thru the engines we have in the platform like SQL, MapReduce, and graph,” Goel says.
It’s estimated that 80 percent of an organization’s data lives in email, Goel says. Using Aster 6, customers today can analyze that email-based data through the comfort of SQL. However, the capabilities will be improved with coming releases. “Our vision is to build more data-type specific stores, so data can be captured quickly in its native form,” he says. “In the future we’ll go out and build more stores like email or JSON, so data can be quickly ingested into the platform and analysis can be done on it.”
The combination of graphing and MapReduce will allow Aster customers to explore their data and discover new connections and insights much faster than if they were hand-coding their MapReduce, graphing, and statistical algorithms, Goel says.
One potential use of this functionality is identifying churn patterns in the telecommunications industry. The graphing function can be applied against call records to create a social graph of who’s calling who. Then the company can perform statistical analysis to pull up messaging statistics, and see how active they are. Then they can pass the results over to a MapReduce function, to perform sentiment analysis to see whether any of the people have been calling into the call center to complain about bad service.
“In telecommunications, it’s fairly well known that any time a key subscriber churns, anybody connected to him is six times more likely to churn. So if you’re going to do that sort of analysis, essentially from an analytical perspective, you need to combine these multiple analytic technologies,” Goel says. “By combining these techniques together, you can identify a list of churners that is more refined and impactful.”
There are many potential uses. For example, in a grocery store setting, it’s fairly common to have wine and meat (and wine and cheese) pairings that go together. But what about salad and condiments? Does a certain selection of wine determine whether a customer is more likely to choose a certain crouton? The graphing engine could help a grocery store direct certain types of users to higher margin products.
These types of challenge and solutions are fairly common in the big data analytics world. The advantage that Teradata provides with its Aster platform is the capability to access these rich analytics from plain old SQL.
“The analyst is using SQL to write these blended queries which can have graph in it, which can have MapReduce in it, which can tech sentiment in it, and solve these use cases, like the telco churn example, which are really difficult to solve,” Goel says. “It takes organizations today multiple tools, an army of data scientists, and many many months to solve. With Aster they’ll be able to solve it by writing one SQL query.”
While that single SQL query may start out looking ordinary, Aster soon transforms it into a multi-pronged piece of power code. The secret sauce in Aster’s approach is the code optimizers that transform rudimentary SQL into native graphing or MapReduce code, and the executors that handle the scheduling.
“Analysts are writing plain vanilla SQL. We provide a lot of out-of-the-box functions that these analysts can nest with their SQL queries to get their results,” Goel says. “An end-user will write a blended SQL query… and this optimizer then takes the query and depending on the shape of the query, it splits the query to pass on to these execution engines. Part of the query goes to MapReduce, part to SQL, and part to graph.”
Then the executor manages the orchestration of query execution across the multiple engines. “So it’ll take results once the SQL engine is finished executing, take the results and feed it into the MapReduce engine. The MapReduce engine does its thing and the executor then takes the result and puts it into graph engine. This is all happening very transparent to the user, through the SNAP architecture.” For those with big data skills, Aster also provides an API for developers to implement their own analytic routines.
In addition to the SQL-GR graphing engine, the new file-based data store, and the SNAP architecture, Aster 6 brings about 600 new statistical functions, courtesy of Teradata’s partnership with FuzzyLogix.
Aster 6 will be entering beta later this year, with GA expected in 2014. The software will be available for customers who run Aster on Teradata’s appliances (which 95 percent of Teradata’s customers choose), or running on their own hardware. Aster can run on the same cluster where the Teradata data warehouse (and Hadoop) reside. Aster and Teradata can co-exist on any number of nodes in the cluster, up to a maximum of 18 nodes–making for a very rich, very powerful big data offering.
Related Items:
Teradata to Hold Online Hadoop Developer Conference
Teradata Delivers Industry’s First Flexible, Comprehensive Hadoop Portfolio
Leading Solution Providers
















