


September 25, 2013
MapR Gooses HBase Performance in Pursuit of Lightweight OLTP
MapR Technologies claimed this week that the latest update to its high-end Hadoop distribution can run HBase database applications up to 700 percent faster than before, which will pave the way for customers to implement more real-time, transaction-oriented applications in their Hadoop environments.
Hadoop is best known as a batch-oriented storage and analysis platform that allows users to ingest, store, and process huge data sets that would stop any other cluster dead in its tracks. The revolutionary approach to big data handling is having a ripple effect (some would say tsunami) across the global $4-trillion IT industry.
One of the trade-offs to implementing Hadoop is that data processing is typically batch-oriented in nature. You can now ask questions of ridiculously large data sets (as opposed to analyzing just a small sample), but it’s going to take a bit of time, not only to get the freshest data into the cluster, but to process it as well. People put up with this because Hadoop does things that simply aren’t possible elsewhere.
As one of the major distributors of the open source Hadoop framework, MapR Technologies has worked to eliminate some of the technical barriers that keep Hadoop confined primarily to batch workloads. It has also implemented features that are aimed at increasing the scalability and reliability of Hadoop.
Probably the biggest change that MapR makes is the re-architected storage system that it ships with its high-end M7 distribution, which is based on NFS instead of the Hadoop Distributed File System (HDFS). That re-architecting also involving eliminating the reliance on the Linux file system and Java API, eliminating single point of failure in with single name nodes, and enabling random read-write access to data, says Jack Norris, the company’s chief marketing officer.
“One of the reason there’s such a reputation in Hadoop for batch orientation is that the Hadoop Distributed File System is a write-once storage layer,” Norris says. “It works like a CD-ROM. You can write data into it, but if you have to update it…you have to physically close the file. So administrators usually set up some regular time period to close files and constitute the batch upload.
“With MapR,” he continues, “because we rewrote the storage layer, we support random read-write, so you can mount the MapR cluster and continue to stream data in, which means there’s no batch cadence, if you will, that’s required.”
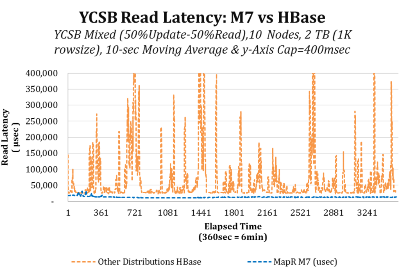
MapR has not been shy about touting the performance aspects of its Hadoop distribution, including taking the top honors on the Yahoo Cloud Services Benchmark (YCSB) earlier this year. That tune is not changing with the new version 3.01 release of the M7 distribution that it unveiled this week. To that end, the company says that performance tweaks in the new release allows it to run Hbase database workloads 400 to 700 percent faster than previous release.
MapR says it has condensed and simplified the entire stack that connects Hadoop and HBase. “You can imagine different layers being written as you continue to write and update, and then periodically they have to be collapsed and rewritten and entered into the Hadoop file system,” Norris says. “With MapR, we’ve eliminated all these associated layers and made it direct random read-write. That results in much faster performance.”
The performance boost–combined with latencies that are consistently below 20 milliseconds–will allow developers to build new types of applications with MapR that would have been inadvisable to attempt to build using other Hadoop distributions, Norris says.
“It’s about supporting what I call lightweight OLTP, lightweight transactions,” Norris says. “It’s not like you’re going to take HBase and all of a sudden run an ERP on it. But you can do some pretty interesting database operations now integrated with Hadoop with HBase, and do them to support an online environment.”
Improving shopping recommendations in an online retail setting is one example of how the new performance capabilities can be utilized. Some online retailers are using MapR’s Hadoop distribution to analyze a shopper’s store-browsing or purchase history and make recommendations based on that. Making three really good recommendations to present to the shopper in a short amount of time can be a real challenge, Norris says, and the new Hbase performance capabilities can help.
The higher Hadoop-HBase performance can also come into play in the social media arena, including pushing ads to mobile devices. According to Norris, it will improve an organization’s capability to rapidly process clickstream feeds for the purpose of publishing targeted ads.
Other potential applications that could take advantage of the scalability advantages that MapR purports to possess include processing billing records in a telecom environment, and gathering and processing billing and usage data in a healthcare setting.
Minimizing lag times, or latency, in Hadoop and HBase apps is the key to taking advantage of the analytic processing capacity, Norris says. “If you get latencies that are 10 to 50 times slower, and you have these giant peaks and valleys, it’s difficult for a developer to roll out an application they are happy with happy,” he says. “Latency can impact not only application but user behavior.”
The version 3.01 release of MapR M7 Edition is available now. The software can be utilized in an on-premise manner, or deployed via Amazon Elastic Map Reduce (EMR) or the Google Cloud Platform.
Related Items:
Hadoop Sharks Smell Blood; Take Aim at Status Quo
MapR Technologies Closes $30 Million in New Funding
Vendors:
MapR
Leading Solution Providers
















