


February 19, 2013
Apache Hadoop 2.0.3-Alpha Released With Future Outlook
It’s been a few months since the last version of Apache Hadoop stormed the shores. This month, a new wave of enhancements crashed in as the Apache Software Foundation released version 2.0.3-alpha of Apache Hadoop open-source software framework, bringing in the next major milestone for the Apache Hadoop community.
![]() “This release delivers significant major enhancements and stability over previous releases in Hadoop-2.x series,” commented Arun Murthy, Release Manager for the Hadoop-2.x and founder of distro vendor, Hortonworks, in a recent article.
“This release delivers significant major enhancements and stability over previous releases in Hadoop-2.x series,” commented Arun Murthy, Release Manager for the Hadoop-2.x and founder of distro vendor, Hortonworks, in a recent article.
Murthy comments that the release notably includes the following enhancements, which are woven with a good bit of YARN:
- QJM for HDFS HA for NameNode (HDFS-3077) and related stability fixes to HDFS HA
- Multi-resource scheduling (CPU and memory) for YARN (YARN-2, YARN-3 & friends)
- YARN ResourceManager Restart (YARN-230)
- Significant stability at scale for YARN (over 30,000 nodes and 14 million applications so far, at time of release)
Apache notes that Hadoop 2.0.3-alpha consists of significant improvements over the previous stable release(Hadoop-1.x), including HDFS Federation, which allows users to scale the name server horizontally, providing scalability and performance benefits.
It’s worth noting that the updates in the 2.0.3 release aren’t unfamiliar to many users who use Cloudera or MapR’s distribution. They have been basing their platforms off the untested 2.0 for several months, but according to Hortonworks’ Ari Zilka in an interview with us last year, there were still a great many bugs to work out, specifically on the reliability front.
“The prior HDFS architecture allows only a single namespace for the entire cluster,” notes Apache on a page outlining HDFS Federation. “A single Namenode manages this namespace. HDFS Federation addresses limitation of the prior architecture by adding support multiple Namenodes/namespaces to HDFS file system.”
Also in the release is the introduction of the much anticipated MapReduce NextGen (aka YARN, aka MRv2), which divides the two major functions of the JobTracker: resources management and job life-cycle management into separate components. “The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.”
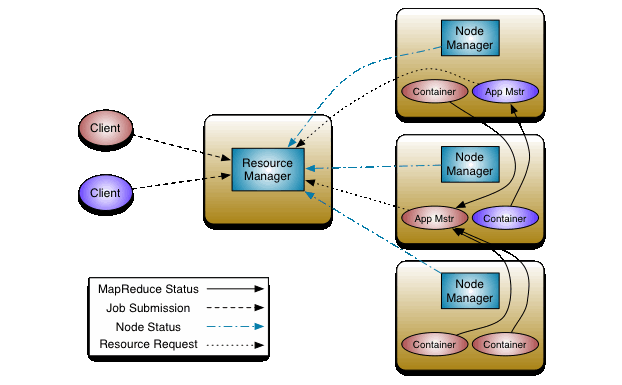
A stable 2.x release date has not yet been set, says Murthy, citing that some of the APIs, particularly the HDFS & YARN based protobuf-based protocols aren’t fully baked, but Murthy comments that a beta release for Hadoop-2.0.4 is imminent with a release in planning.
“We are converging fast on ironing out the API issues (both in HDFS & YARN/MapReduce) and, currently, plan to cut a Hadoop-2.0.4-beta release in the next couple of months after this effort,” comments Murthy, pointing towards the next major Hadoop milestone.
In his note about the release, Murthy gave a shout-out to Hadoop benefactor, Yahoo!, for their role in helping to test out the Hadoop-2 HDFS HA advancements over the course of the coming months. Yahoo! claims to have run over 14 million jobs on YARN (Nextgen MapReduce for Apache Hadoop) and average more than 80,000 jobs on a single cluster per day on Hadoop. 0.23, and says that they have recently built a near real0time scalable processing and storage infrastructure with MapReduce/YARN, HBase, ZooKeeper, and Storm clusters to enable Yahoo!’s next generation of personalization and targeting services.
“It helps to have a major presence like Yahoo! test out the Hadoop-2 HDFS HA,” says Murthy.
Related Stories:
A Cutting Preview of Hadoop in 2013
Hortonworks Webinar Offers Vision of 2013 Hadoop
Hortonworks Dishes on Distro Differences
Technologies:
Frameworks
Vendors:
Hortonworks
Leading Solution Providers
















