


June 15, 2012
This Week’s Big Data Big Seven
We’re rounding out another news-heavy week in the world of data-intensive computing with the closing bell sounding on the Hortonworks Hadoop Summit in San Jose, which brought forth a number of Hadoop-related announcements.
 We are also looking ahead to next week where the International Supercomputing Conference (ISC) will be taking place in Germany, producing a new string of Graph500 winners and some hardware-related news items.
We are also looking ahead to next week where the International Supercomputing Conference (ISC) will be taking place in Germany, producing a new string of Graph500 winners and some hardware-related news items.
For now, let’s recap on the week that’s just ending with news about a new high performance, data-intensive supercomputer from SGI, new Hadoop announcements, including those from Hortonworks, Datameer, and Karmasphere, some software enhancements for big data infrastructure from ScaleOut and some other startup goodness.
Let’s get started with news from the host of this past week’s Hadoop Summit, Hortonworks
Hortonworks Rolls Out Data Platform
This has been a big week for Hadoop distro vendor, Hortonworks. A number of new partnerships and news items have emerged out of its annual Hadoop Summit, which just wrapped up in San Jose.
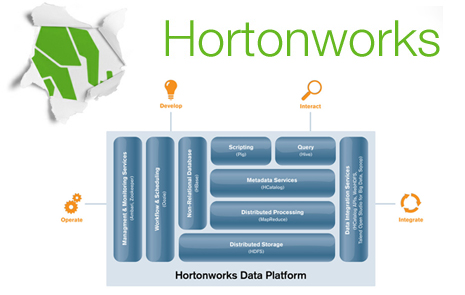
The company used the venue and attention to roll out the supported Hortonworks Data Platform, which they call a pure open source platform (built on the stable release of Apache’s Hadoop 1.0) that’s ready for mission critical, enterprise environments.
Among the core platform features are the following:
Cluster provisioning and setup (Apache Ambari): HDP aims to simplify cluster provisioning with an interface that they say guides the user through a seven-step provisioning process by surveying the nodes for the target cluster and automatically recommending the optimal software configuration. Once the configuration is confirmed, one click will provision and start the entire cluster.
Management and monitoring services (Apache Ambari): This allows users to view health of the cluster as well as centralized access to HDP’s built-in management functionality. Since these capabilities are implemented as 100-percent open source, Hortonworks says there will be inherent integration with existing management and monitoring solutions.
Metadata services (Apache HCatalog): HDP enables users to define the structure and location of data within Hadoop for easy and consistent access from any program. This capability makes it easier to create and maintain applications running on Hadoop. Simply put, sharing data within Hadoop via standard table formats expected by relational databases, enterprise data warehouses and other structured data systems makes it easier to integrate data management systems with Hadoop.
Data integration services (Talend Open Studio): HDP provides users with graphical interfaces for connecting to data sources and building complex transformation logic all without writing a line of code. In addition, core platform services enable scheduling of data integration, transformation and data refinement within the platform.
As Rob Bearden, CEO of Hortonworks said that,“Unlike alternative Hadoop offerings, HDP is 100-percent open source with no proprietary code, eliminating vendor lock-in and expensive proprietary add-ons. We are excited to deliver a comprehensive, Apache Hadoop-based enterprise data platform that provides the easiest way for the enterprise ecosystem to optimize and integrate their service with Hadoop.”
Next — SGI Shines Light on New UV >>
SGI Shines Light on New UV
Next week at the International Supercomputing Conference in Germany, SGI will officially unveil the newest in its line of UV supercomputers. This one, however, is targeted at the types of data-intensive problems that require specialized hardware that’s fine-tuned for both big data and big performance.
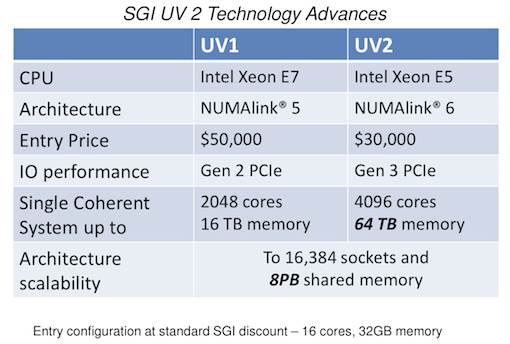
The UV 2 will double the number of cores and offer 4 times the memory that can be supported on one system when compared to its predecessor. As Michael Feldman over at HPCwire reports, this line of supers’ claim to fame is their ability to support multi-terabyte, “big memory” applications.
As he states, Since the architecture supports large amounts of global shared memory, applications don’t have to slice their data into chunks to be distributed and processed across multiple server nodes, as would be the case for compute clusters. Thanks to the SGI’s NUMAlink interconnect, UV is able to glue together hundreds of CPUs and make them behave as a single manycore system with gobs of memory. Essentially, you can treat the machine as an ultra-scale Linux PC.”
“The technological advancement demonstrated in this next-generation SGI UV platform is not simply focused on increasing our lead in coherent memory size and corresponding core count. We have been able to deliver all of this additional capability while driving down the cost of the system,” said Dr. Eng Lim Goh, chief technology officer, SGI. “In fact the entry level configuration of SGI UV 2 is 40% less expensive than SGI UV 1. This creates a new level of accessibility for large shared memory systems for researchers and the ‘missing middle’, providing an effective lower overall TCO alternative to clusters.”
Next — Hadoop Hits the Desktop >>
Datameer Puts Hadoop on the Desktop
This week Datameer made an announcement that combines data integration, analytics and visualization and targets all data types, size, or source, in one application with the Datameer 2.0 release.
The company garnered headlines this week with their assertion that this release, “brings the power of Apache Hadoop directly to the desktop, with Hadoop natively embedded in two of three new editions of the application.” Datameer Personal runs on a single desktop, while Datameer Workgroup runs on a single server. Datameer Enterprise scales to thousands of nodes and runs on any Hadoop distribution.
Additional features found in all three Editions of Datameer 2.0 include the company’s Business Infographics Designer, an enhanced user interface, support for more data sources, and extended OS and device support.
According to Datameer, with 2.0 they have “combines a simple spreadsheet interface with the unlimited data storage and compute powers of Hadoop, enabling business users to improve company performance, better understand customer behavior, and optimize business processes.”
As the company’s CEO, Stefan Groschupf, explained, “By bypassing the traditional, slow, multi-step process of creating static schemas, we enable users to get right to analyzing and visualizing data without needing to rely on IT.”
Business Infographics on Any Device, Expanded Data Sources
With the introduction of the Business Infographics Designer, Datameer 2.0 breaks traditional box after box style of dashboards by giving users complete graphics and visualization design control. The vector-based WYSIWYG designer enables users to choose exactly how they want to visualize their data, whether its stunning infographics or more traditional reports, maps, graphs and dashboards.
Built on HTML5, Datameer 2.0 runs on any device, letting users work with and visualize their data on smart phones, tablets, desktop and laptop computers. Datameer supports all of the popular operating systems including Windows and Mac OS as well as Linux and VMWare.
Datameer 2.0 also supports more data sources than ever, adding to an already extensive list and easy-to-use API for custom integration. New sources in 2.0 include Twitter and Facebook, Netezza and COBOL as well as Teradata export. Datameer also offers improved HIVE integration, including the ability to export to HIVE as well as the previously supported HIVE data import.
Next — ScaleOut Targets Big Data Clouds >>
ScaleOut Targets Big Data Clouds
This week, ScaleOut Software, a vendor the in-memory data grid (IMDG) space, announced enhancements to its ScaleOut StateServer that they saw lead to better scalability and support for public cloud use.
Released in beta earlier this year, StateServer Version 5 also integrates expanded analysis capabilities with property-based parallel query and includes global data integration.
The company says that the need for scalability to hundreds of servers has emerged as a requirement to handle increased workloads and to enable the use of IMDGs for real-time data analytics. They claim that this update lets users deploy very large in-memory data grids holding terabytes of data that provide some fine-tuned operating characteristics that address the speed, reliability, and ease of use demands of such users.
The company says that Version 5 is the first IMDG to link together in-memory data grids at multiple sites, including the cloud, into a single, logically coherent grid. This feature enables what ScaleOut calls the “seamless migration of data across geographies without the need to replicate data from site to site.” With Version 5, users are also able to combine multiple IMDGs into a single, virtual data grid to simplify data access and speed program development.
Version 5 also introduces highly optimized, property-based query of grid-based data that can be performed directly from application programs. The .NET community can use Microsoft’s Language Integrated Query (LINQ), and Java developers can use familiar filtered queries to programmatically access groups of related data within the grid based on selected criteria associated with the data.
The company says this release is suitable for using IMDGs in data mining and large scale analytics, especially with the addition of a new column-based analytical component that will allow users to update a targeted set of large grid objects in a manner similar to running stored procedures in a database environment.
Next — Moving Big Data Closer to Reach >>
Moving Big Data Closer to Reach
This week at the Hortonworks Hadoop Summit Karmasphere announced Karmasphere 2.0, which they’re dubbing as “the industry’s first collaborative analytics workspace.”
 The company is touting the ease of use angle for big data operations by providing a browser interface that allows for easier collaboration when dealing with complex, large datasets. This removes the IT “middleman” and lets users focus on their data as it is needed via simplified reporting, visualization, and publishing to existing databases and applications.
The company is touting the ease of use angle for big data operations by providing a browser interface that allows for easier collaboration when dealing with complex, large datasets. This removes the IT “middleman” and lets users focus on their data as it is needed via simplified reporting, visualization, and publishing to existing databases and applications.
For big data power users, the company also announced the a new workflow for analytics that includes the ability to ingest data into the Hadoop cluster, mine it for trends, analyze it using familiar operations, then visualize or publish. Karmasphere says that 2.0 is designed to work with any Hadoop distribution and leverages Apache Hive, the Hadoop SQL standard, for the portability of analytic assets.
“We continue to create very powerful and easy-to-use Big Data Insight capabilities on the open standards the entire Hadoop community is investing in such as Apache MapReduce, HDFS, Hive, Pig and Mahout. We know that customers are moving to Hadoop for its power, openness, speed of innovation and don’t want to be locked into proprietary environments,” said Martin Hall, EVP and Founder, Karmasphere.
Next — A Pervasive Partnership >>
Pervasive, Actuate Visualize Big Analytics
This week Actuate, the company that produces the BIRT BI platform and Pervasive Software announced a new partnership that targeted users with big data analytics and visualization needs. ActuateOne and Pervasive RushAnalyzer will blend to make big data analytics and visualizations available to business users in any industry and to the BIRT developer community.
 ActuateOne is an integrated suite of standard and cloud software built around BIRT, which enables visualization of data trends through customizable BIRT-based dashboards and Google-standard plug-and-play gadgets.
ActuateOne is an integrated suite of standard and cloud software built around BIRT, which enables visualization of data trends through customizable BIRT-based dashboards and Google-standard plug-and-play gadgets.
On the other end, Pervasive RushAnalyzer lets data analysts build and deploy predictive analytics solutions on multiple platforms, including Hadoop clusters and high-performance servers, to rapidly discover data patterns, build operational analytics and deliver predictive analytics. The drag-and-drop graphical interface speeds data preparation with direct access to multiple databases and file formats, as well as a prebuilt library of data mining and analytic operators, which say leads to simpler data manipulation, mining and visualization.
“Pervasive RushAnalyzer, the first predictive analytics product to run natively on Hadoop, enables users to rapidly transform and analyze terabytes of data on commodity hardware, and ActuateOne provides the advanced visualization capabilities to support insights and more productive conclusions,” said Mike Hoskins, CTO and general manager of Pervasive, Big Data Products and Solutions. “Pervasive’s seamless integration with Actuate, via BIRT, puts advanced Big Data analytic insights and actionable intelligence into the hands of multiple roles within an organization.”
Next — Startup Targets Hadoop Implementations >>
Startup Targets Hadoop Implementations
This week Bay Area startup, Cloudwick, announced the launch of enterprise-grade implementation and integration services for the Hadoop infrastructures. The company has been providing such services since 2010, but as Hadoop implementations ramp up, they expect to see more users.

One such user they pointed to this week was the large-scale online social gaming company, IMVU. “Cloudwick recently completed Hadoop deployment and data integration with our Mysql data backend.”, said Ken Bradley, Director of Business Intelligence at IMV. “Initial POC deployment gave us the advantage of defining use cases and technical functionality before we went for production deployment. Cloudwick’s deployment process helps us to keep our costs much lower than industry standard for similar deployments.”
The startup says that 90% of the use cases in the enterprises have been focused on Hadoop integration with existing data infrastructure. The enterprises are having hard time on setting up the Hadoop infrastructure and integrating with the existing data infrastructure.
Cloudwick says its services are designed for quick deployment and integration and that they’re providing 30 days POC that include hardware cluster and services. The POC allows the enterprises to define use cases and requirements before they have to spend the money. This approach will lead to much lower cost of operations.
“We have implemented large number of use cases and have developed expertise to deploy Hadoop solutions rapidly. “, said Mani Chhabra, Founder of Cloudwick. “With the launch of these Hadoop services we can cut down implementation from months to days.”
Leading Solution Providers
















