


September 4, 2014
Stinger Initiative Prepares for .next Phase

The Hadoop developer community that recently delivered the final tweaks to the Stinger Initiative, an effort to bring SQL capabilities to Apache Hive, said its Stinger.next effort would focus on further enhancements to SQL for supporting real-time access in Hive along with support for transactional capabilities.
In a blog post, Hortonworks developers Alan Gates and Raj Bains reported that 145 developers from 44 companies have contributed 390,000 lines of code over the last 13 months to the Stinger Initiative. They added that companies like Microsoft and Tableau Software are also backing the next phase of development.
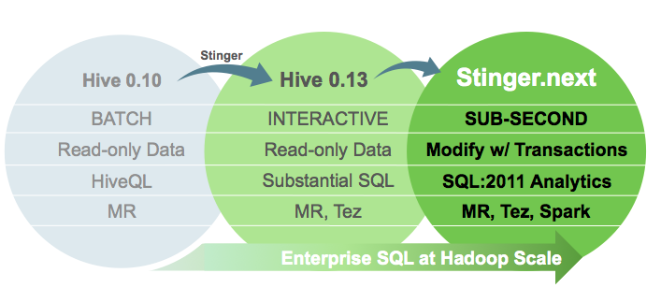
Stinger.next will continue the effort by improving the speed, scale and breadth of SQL support. As before, a three-phase delivery schedule is planned, and all development will from the open Apache Hive community. The speed goal for the Stinger.next effort is sub-second query response times. The scaling target will be a new SQL interface to Hadoop for queries that scale from gigabytes to petabytes. The effort also hopes to enable transactions via SQL:2011 analytics for Hive.
(Source: Hortonworks)
The three-phase delivery schedule looks like this: phase one in the second half of 2014 would provide transactions with ACID semantics in Hive along with temporary tables; phase two in first half of 2015 would include delivery of sub-second queries with a new tool called LLAP (Live Long and Process) along with integration of Hive-Spark machine learning; and a third phase during the second half of 2015 would include, among other things, SQL:2011 analytics and workload management via YARN and LLAP integration.
The goal of the initial effort was to develop a single Hive tool for SQL to move it beyond batch workloads to interactive queries. Stinger.next is intended to boost performance to near real-time, promoters say.
The addition of a transaction capability scheduled for delivery later this year would leverage ACID semantics, which the Hortonworks developers called “a major shift in the paradigm” since adding SQL transactions would “allow users to insert, update and delete the existing data. This allows a much wider set of use cases that require periodic modifications to the existing data,” they claimed.
Achieving sub-second queries with Hive would require fast query execution and low setup costs without sacrificing scale and flexibility. Hence, the plan to use a hybrid engine that leverages Apache Tez for near real-time big data crunching along with LLAP. The latter is described as an optional daemon process running on multiple nodes that among other capabilities provides caching and data reuse across queries.
Hortonworks said YARN would be used to provide workload management in LLAP, adding the queries would bring resource allocation information from YARN to LLAP. LLAP then allocates additional resources to serve the query as instructed by YARN.
“The hybrid engine approach provides fast response times by efficient in-memory data caching and low-latency processing, provided by node resident processes,” Hortonworks said.
Meanwhile, Hive sidesteps limitations on workload management, for example, by limiting the use of LLAP to the initial phases of the query processing.
Recent items:
Putting Some Real-Time Sting into Hive
Stinger Looking to Tez to Cross 100x Performance Line for Hive
Leading Solution Providers
















