


February 20, 2013
HP Diving Deeper into R Parallelization
Despite R’s popularity as a statistical tool, its single-threaded nature might be a short-coming in scaling its use as a tool for big data applications.
 Not if they can help it, says HP.
Not if they can help it, says HP.
In a recent webinar titled, “Unlocking the Massive Potential of Sensor Data and the Internet of Things,” HP discussed the integration of R in their Vertica platform, explaining that plans to expand the parallel capabilities of R are underway.
HP says that because much of the advanced analysis of sensor data involves statistics, integration with R is a real big plus allowing analysis to be done right in the database. However, scaling concerns for the statistical language have caused HP to search for solutions to make it’s usefulness in big data extend past a single thread.
“[R] is single-threaded and limited by the amount of RAM on the machine it is running on, which makes it challenging to run R programs on big data,” said Lakshimikant Shrinivas, Pratibha Rana, and Mark Waner, software engineers with Vertica Systems in a recent article. “There are efforts underway to remedy this situation, which essentially fall into one of the following two categories (1) Integrate R into a parallel database, (2) or parallelize R so it can process big data.”
The Vertica teams plan for doing this includes two prongs. First they plan on running multiple instances of the R algorithm in parallel with queries that chunk the data independently, while relying on SQL to put the operations in proper order for querying partitioned data.
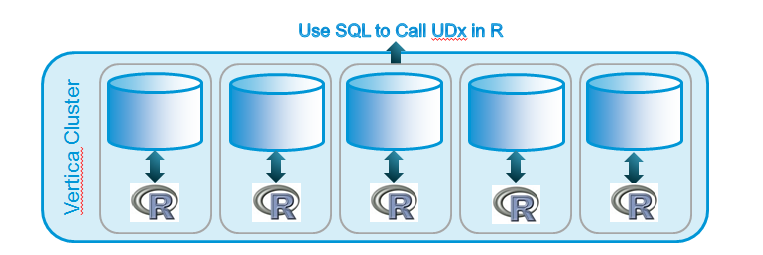
“The parallelism comes from processing independent chunks of data simultaneously (referred to as data parallelism),” explains the Vertica engineering trio. “SQL, being a declarative language, allows database query optimizers to figure out the order of operations, as well as which of them can be done in parallel.”
Secondly, the team explains, they will be leveraging column-store technology for optimized data exchange for querying non-partitioned data.
“It is important to note that even for non-data parallel tasks (functions that operate on input that is basically one big chunk of non-partitioned data), Vertica’s implementation provides better performance since computation runs on a server instead of client, and we have optimized data flow between DB and R (no need to parse data again),” explains the team.
These developments should come as good news for the expanding user base of the open source R language, which has been growing year over year. According to the most recent survey by Rexer Analytics, close to half of all data miners (47%) are using R as a part of their toolkit, with historical trends showing year-over-year increases in adoption.
Vendors:
HP
Leading Solution Providers
















