


January 29, 2013
RHadoop Brings Code to Data
According to Jeffrey Breen of Think Big Analytics, the last twelve months has seen more companies move from experimentation in Hadoop to actual implementation.
 With that being said, 60 percent of the 2000 people that joined a live webinar conducted by Breen and hosted by Revolution Analytics were still in the test stage with Hadoop.
With that being said, 60 percent of the 2000 people that joined a live webinar conducted by Breen and hosted by Revolution Analytics were still in the test stage with Hadoop.
In an effort to help those users join those who are moving into full implementation, the webinar was set up to explain both the value and the intricacies of working with Hadoop along with introducing RHadoop, an open source platform supported by Revolution.
What RHadoop brings to the table, according to Breen, is the ability to bring code to the data. As shown in the figure below, a typical Hadoop cluster has data stored in a lot of places, with the total volume potentially reaching the petabyte range. It would be much more efficient to bring a MapReduce task in the form of a few lines of code to that data rather than moving the sizable amount of data to the code.
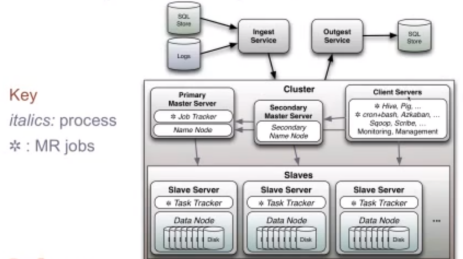
In order to do that, the code must be optimized for efficiency. A good way to do that is to understand the essence of a MapReduce job itself.
To illustrate his point, Breen explained the fundamentals of MapReduce through a simple word counting task. His example included three files, each containing one of the following phrases: “Hadoop uses MapReduce,” “There is a map phase,” and “There is a reduce phase,” followed by a fourth empty file.
The map phase, per Breen’s explanation, takes the input, breaks it into pieces, and assigns value to the pieces. The reduce phase then orders the pieces based on the values and generates one output. This can be likened to assigning coordinates to a geographical area so they can all be ordered and placed digitally.
In the word counting example, the phrases are broken up during the map phase into their individual words and assigned a value based on how many times the word was repeated in a given phrase. The reduce phase will notice while aggregating all of the words from all of the phases that the words ‘a,’ ‘phase,’ and ‘there’ are all used twice and will note that in the output.
That example is a somewhat simplistic one involving only four files (the empty one was included to indicate that it would not trip MapReduce). However, Breen noted that the principle for approaching potentially hundreds of thousands of files is similar to that of using just four files.
There was a point where, according to Breen, if someone wanted to write a MapReduce task, they would have to write it in Java. Thankfully, due to a streaming API, those jobs can be written in virtually any language. “If your preferred language can handle standard in and standard out, you can use your language to write MapReduce jobs now,” Breen said.
Coding in a variety of languages combined with the described efficient coding practices would make bringing the code to the data through RHadoop an attainable goal.
Related Articles
How Data Analytics is Shifting Politics
MapR Charts Hadoop’s Path to Europe
Applications:
Enterprise Analytics
Vendors:
Revolution Analytics
Leading Solution Providers
















