










April 2, 2021 — In a blog post, Charlie Gu, Tech Lead, Analytics Platform; Lena Ryoo, Software Engineer, Analytics Platform; and Justin Mejorada-Pier, Engineering Manager, Analytics Platform at Pinterest discussed the open-sourcing of the big data analytics tool, Querybook. The blog post is included in part below.
With more than 300 billion Pins, Pinterest is powering an ever-growing and unique dataset that maps interests, ideas, and intent. As a data-driven company, Pinterest uses data insights and analysis to make product decisions and evaluations to improve the Pinner experience for more than 450 million monthly users. To continuously make these improvements, especially in an increasingly remote environment, it’s more important than ever for teams to be able to compose queries, create analyses, and collaborate with one another. Today we’re taking Querybook, our solution for more efficient and collaborative big data access, and open sourcing it for the community.
The common starting point for any analysis at Pinterest is an ad-hoc query that gets executed on a SparkSQL, Hive, Presto cluster, or any Sqlalchemy compatible engine. We built Querybook to provide a responsive and simple web UI for such analysis so data scientists, product managers, and engineers can discover the right data, compose their queries, and share their findings. In this post, we’ll discuss the motivation to build Querybook, its features, architecture, and our work to open source the project.
The Journey
The proposal to build Querybook started in 2017 as an intern project. During that time, we used a vendor-supplied web application as the query UI. There were often user complaints about that tool regarding its UI, speed & stability, lack of visualizations, as well as difficulty in sharing. Before long, we realized there was a great opportunity to build a better querying interface.
We started to interview data scientists and engineers about their workflows while scoping out technical details. Shortly, we realized most were organizing their queries outside of the official tool, and many used apps like Evernote. Although Jupyter had a notebook user experience, its requirement to use Python/R and the lack of table metadata integration deterred many users. Based on this finding, our team decided Querybook’s query interface would be a document where users can compose queries and write analyses all in one place with the power of collocated metadata and the simplicity of a note-taking app.
Released internally in March 2018, Querybook became the official solution to query big data at Pinterest. Nowadays, Querybook on average has 500 DAUs and 7k daily query runs. With an internal user rating of 8.1/10, it’s one of the highest-rated internal tools at Pinterest.
Feature Highlights
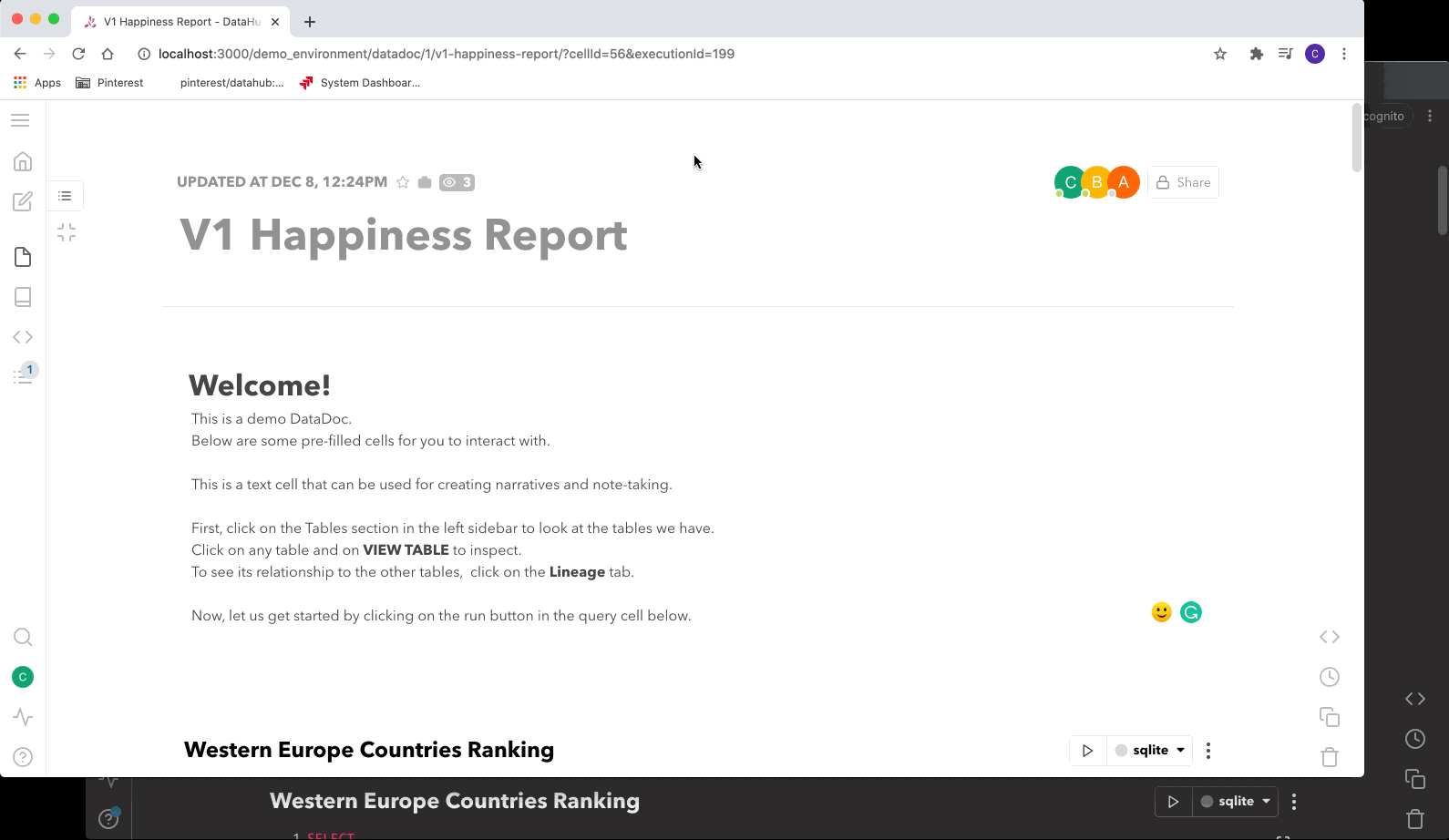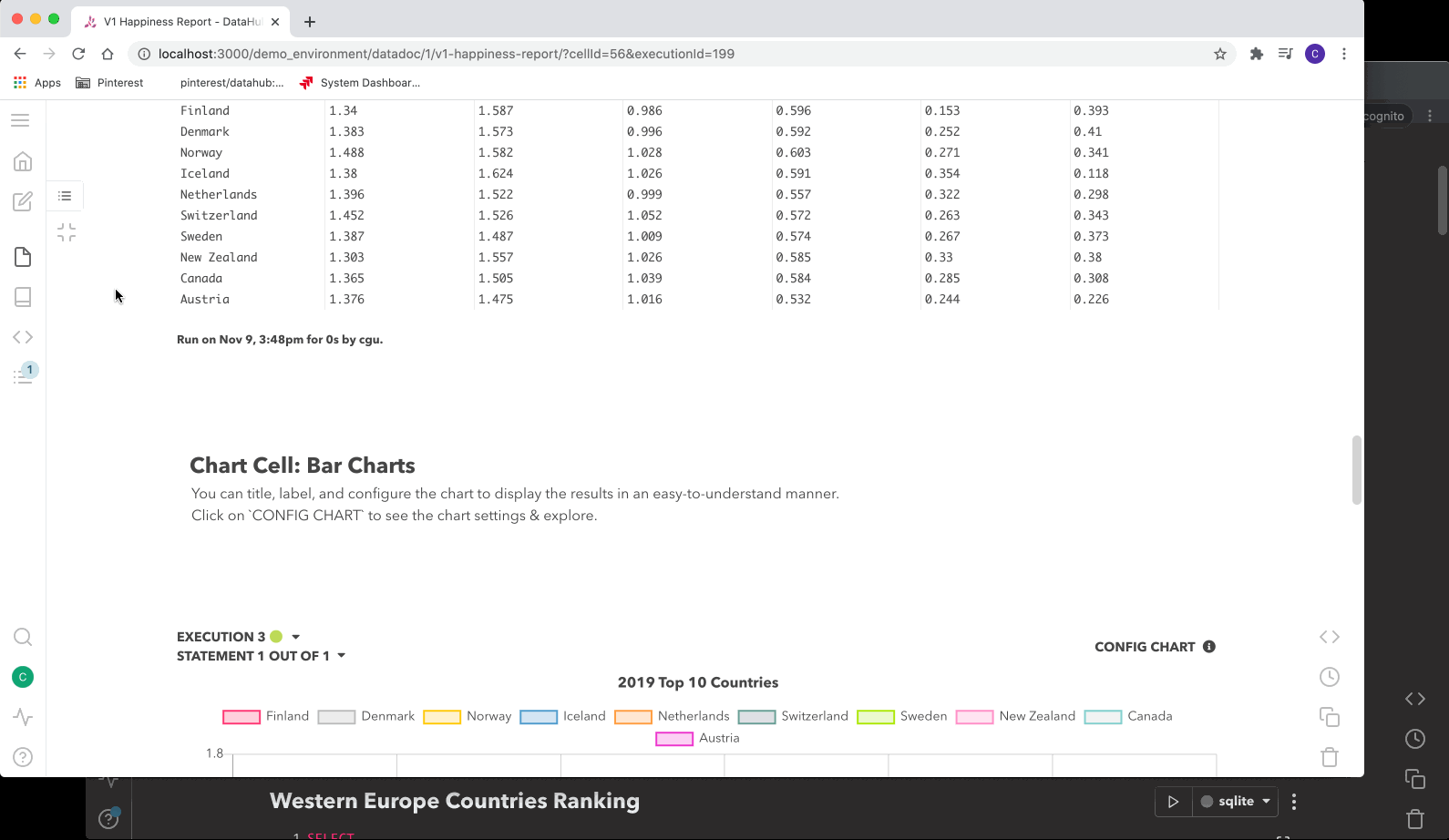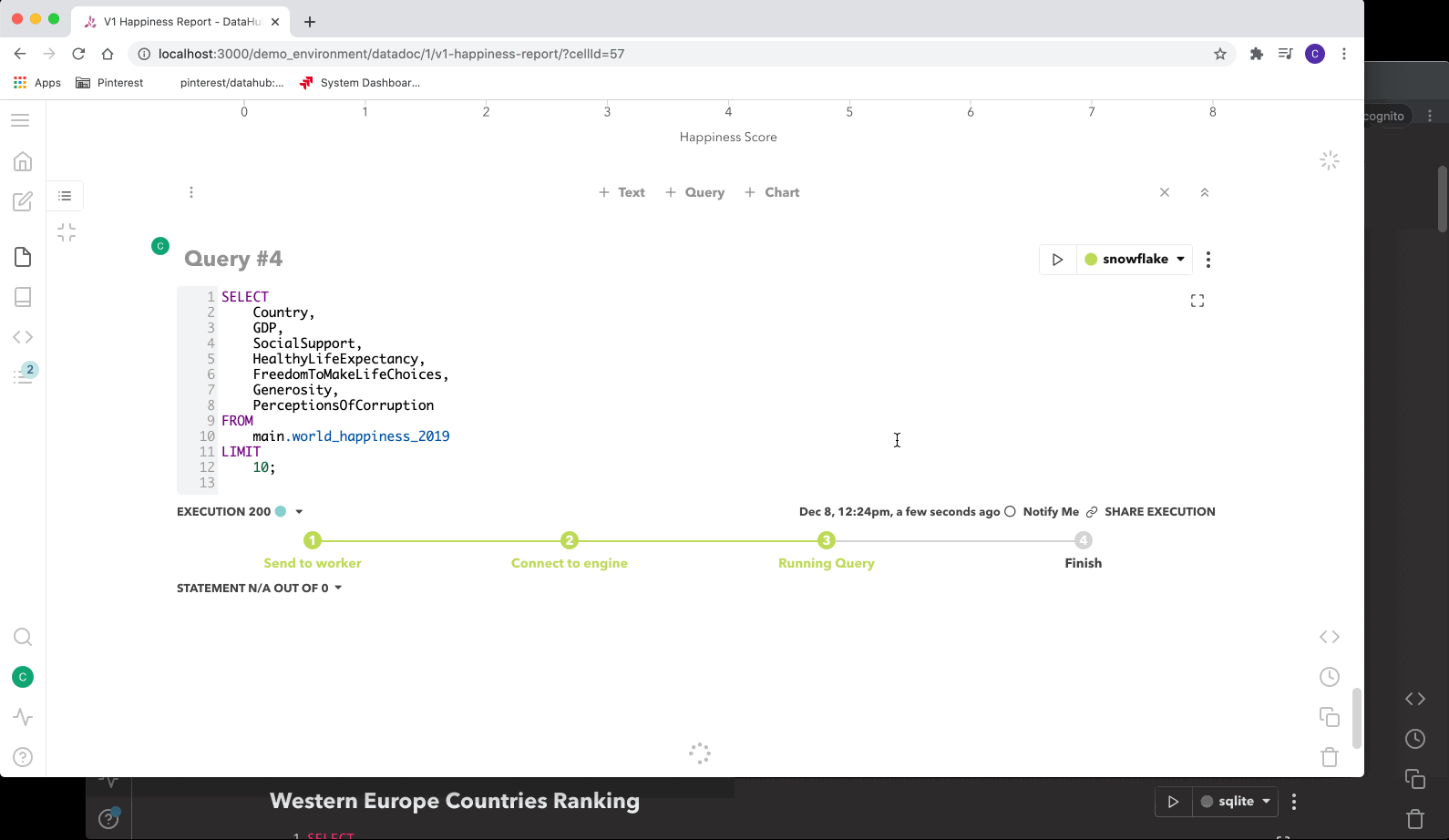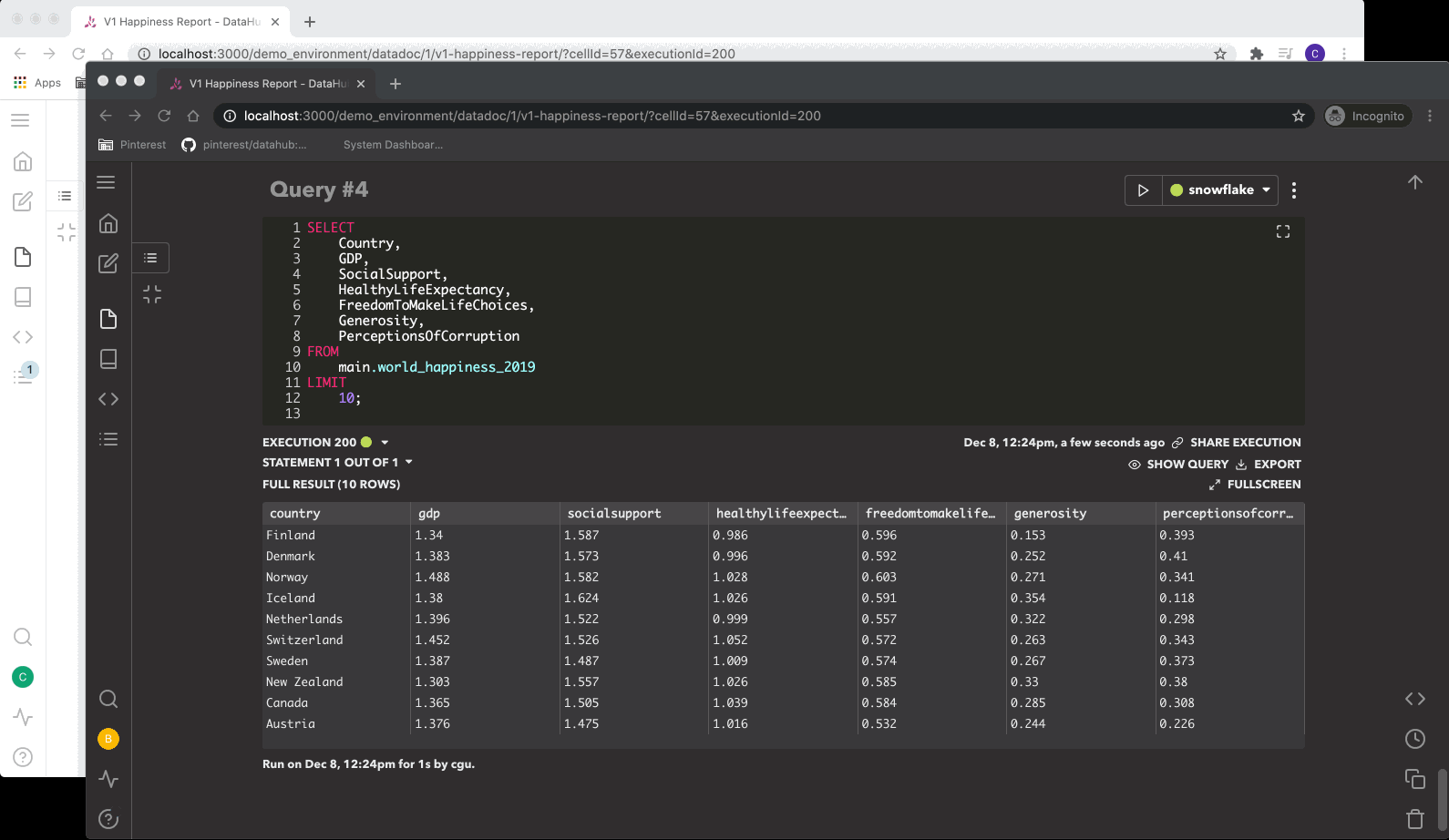
Figure 1. Querybook’s Doc UI. Click to view GIF.
When a user first visits, they‘ll quickly notice its distinctive DataDoc interface. This is the primary place for users to query and analyze. Each DataDoc is composed of a list of cells which can be one of three types: text, query, or chart.
- The text cell comes with built-in rich-text support for users to jot down their ideas or insights.
- The query cell is used to compose and execute queries.
- The chart cell is used to create visualizations based on execution results. Similar to Google Docs, when users are granted access to a DataDoc, they can collaborate with each other in real-time.
With the intuitive charting UI, users can easily turn a DataDoc into an illustrative dashboard. You can choose from different visualization options, such as time-series, pie-charts, scatter plots, and more. You can then connect your visualization to the results of any query on your DataDoc and post-process them with sorting and aggregation as needed. To automatically update these charts, you can use the scheduling options and select your desired cadence. The scheduler can notify users of success or failure. Combined with the templating option powered by Jinja, creating a live updating DataDoc is very quick.
Scheduling and visualization features aren’t intended to replace tools such as Airflow or Superset. Rather, these features provide users a simple and fast way to experiment with their queries and iterate on them. Often, Pinterest engineers use Querybook as the first step to compose queries before creating production-level workflows and dashboards.
Last but not least, Querybook comes with an automated query analytics system. Every query executed gets analyzed to extract metadata such as referenced tables and query runners. Querybook uses this information to automatically update its data schema and search ranking, as well as to show a table’s frequent users and query examples. The more queries, the more documented the tables become.
Architecture

Figure 2. Overview of Querybook’s architecture.
To understand how Querybook works, we’ll walk through the process of composing and executing a query.
- The first step is to create a DataDoc and write the query in a cell. While the user types, the user’s query gets streamed to the server via Socket.IO.
- The server then pushes the delta to all users reading that DataDoc via Redis. At the same time, the server would save the updated DataDoc in the database and create an async job for the worker to update the DataDoc content in ElasticSearch. This allows the DataDoc to be searched later.
- Once the query is written, the user can execute the query by clicking the run button. The server would then create a record in the database and insert a query job into the Redis task queue. The worker receives the task and sends the query to the query engine (Presto, Hive, SparkSQL, or any Sqlalchemy compatible engine). While the query is running, the worker pushes live updates to the UI via Socket.IO.
- When the execution is completed, the worker loads the query result and uploads it in batches to a configurable storage service (e.g. S3). Finally, the browser gets notified of the query completion and makes a request to the server to load the query result and display it to the user.
For brevity, this section only focused on one user flow of Querybook. However, all the infrastructure used is covered. Querybook allows some of it to be customized. For example, you can choose to upload execution results to either S3, Google Cloud Storage, or a local file. In addition, MySQL can also be swapped with any Sqlalchemy-compatible database such as Postgres.
The Path To Open Source
After noticing the success that Querybook had internally, we decided to open source it. One challenge we bumped into was how to make it generic while preserving some of the Pinterest-specific integrations. For this, we decided to have a two-layer organization through a plugin system and to add an Admin UI.
The Admin UI lets companies configure Querybook’s query engines, table metadata ingestion, and access permissions from a single friendly interface. Previously, these configurations were done inside configuration files and required a code change as well as a deployment to be reflected. With this new UI, admins can make live Querybook changes without going through code or config files.
The plugin system integrates Querybook with the internal systems at Pinterest by utilizing Python’s importlib. With the plugin system, developers can configure auth, customize query engines, and implement exporters to internal sites. Customized behaviors provided by the plugin system allow Querybook to be optimized for the user’s workflow at Pinterest while ensuring the open-source is generic for the public.
You can check out more of Querybook’s features and its documentation on Querybook.org.
Acknowledgments: We want to thank the following engineers that have made contributions to Querybook: Lauren Mitchell, Langston Dziko, Mohak Nahta, and Franklin Shiao. And to Chunyan Wang, Dave Burgess, and David Chaiken for their critical advice and support.
Click here for the full blog post.











