

October 9, 2015
Combining High Performance Computing with Big Data Analytics on the Same Infrastructure
Three important trends keep coming up in conversations with customers in the high performance computing (HPC) and big data markets. The first is that more and more users want to combine HPC workloads with big data analytics workloads on the same infrastructure. The second trend is the demand for flexibility to run workloads on either bare metal, virtual machines, or, most recently, in containerized environments. The third trend, closely related to the second, is the demand for flexibility to run on-premise and in the public cloud. New technology is providing an infrastructure that can be the foundation for combining high performance computing, big data, and private and public cloud environments, and managing it all through a single-pane-of-glass.
HPC and OpenStack – gaining flexibility to allocate resources
The cloud computing revolution continues to change the way organizations view their IT resources. OpenStack cloud software provides a common, open source platform that can be used by corporations, service providers, researchers, and anyone else that wants to deploy a private cloud. For many HPC users the question now becomes, can I run an HPC workload atop this OpenStack or alongside it? In the past users needed a dedicated HPC cluster, but now the ability to choose either option creates flexibility. Virtualizing the infrastructure using an OpenStack private cloud allows administrators to be far more flexible in allocating resources.
Take an example of a 25-server environment, in which 10 servers must be dedicated to meet the demands of the HPC load. In this scenario, it is difficult to grow or shrink to meet demand if the demands change significantly. With OpenStack, users have far more flexibility to grow or shrink the cluster. One might increase the cluster overnight and decrease it again in the morning.
Running workloads virtualized inside OpenStack can be a big benefit in many settings. Take the example of researchers in the pharmaceutical industry conducting simulations for drug discovery. When one is required by regulation to store results of simulations and be able to produce them years later, one could choose to run inside a virtual machine (VM) and then shut down and store the entire VM, complete with operating system and libraries. The user would know for certain that results can be precisely duplicated, because the software environment is stored exactly as it was. In addition, some users have very different requirements for their operating systems and their versions of libraries, and a completely tailored environment can be offered in a VM.
While offering a variety of benefits, OpenStack can be difficult to configure and manage. In addition, with virtualization there is a performance penalty, typically less than 10 percent. Some users chalk that up to the price one must pay, while others consider it a barrier to adoption. Also, there is a perception that some hardware technologies are not fully supported by OpenStack, but the industry is definitely making huge progress. For example, InfiniBand and accelerators can now be used through virtualization.
Those not using OpenStack are probably turning to other forms of private cloud, which can be quite an expensive proposition. Or, they may just semi-manually manage their VMs on bare metal using customized scripts and smart provisioning. This is not as flexible, can be prone to errors, and perhaps most significantly, makes users very dependent on the system administrator.
Foundation for combining HPC and big data workloads
Figure 1 is a conceptualization of an infrastructure that combines HPC and big data workloads and gives users the choice of working in either a bare metal or virtualized infrastructure – and even burst through into the public cloud.
We start at the bottom with the physical infrastructure of the servers. On top of that basic infrastructure resides a Linux operating system, with a management solution in which the Bright agent is running on every server. Running HPC on top of that foundation would require the use of a cluster management solution like Bright Cluster Manager. The Bright Computing layer offers a single pane of glass management for the hardware, the operating system, the software, and users.
For running big data workloads or adding big data functionality on top of that, one would use Bright Cluster Manager for Big Data, an option that builds, manages, and maintains big data clusters using Hadoop and/or Spark. Bright Cluster Manager for Big Data was specifically designed to combine HPC and big data workloads. When used on a Bright cluster with Intel’s HAM + HAL plugins, the system offers a common file system and workload manager across the two platforms.
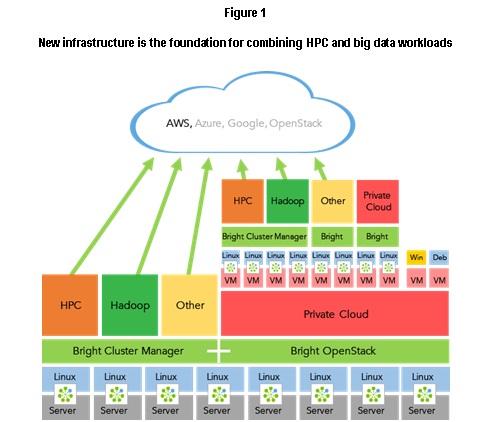
The scenarios in the Other category, for example, server farms, storage clusters, or even a high frequency trading cluster at a bank, also require a similar cluster management solution and infrastructure. For the Private Cloud option, Bright OpenStack adds cloud capability on top of the initial foundation.
The support of Bright Cluster Manager allows users to offload the workload to a public cloud or to a mixed environment, with some servers run on-premise and some in the cloud. It is easy to expand the two options with the single pane of glass solution.
The demand to build an on-premise private cloud has become stronger recently, driven in part by security issues. In some industries, legislation requires that certain data remain inside the company’s firewall. There are other issues that favor an on-premise solution over a public cloud. For example, the very large datasets involved with big data applications may be impractical to transfer to a public cloud. Finally, cost may be a factor, since public cloud services are often more expensive to use over the long term, when compared to on-premise alternatives.
Moving up the diagram, perhaps the most exciting aspect of the concept is the ability to combine all these options on the same infrastructure. For example, the next step would be to further build on top of the virtualization layer provided by OpenStack.
The chief task of OpenStack is to manage VMs – to stand them up, apply a configuration to the template, move them around, and to manage them. But it is important to realize that OpenStack has no awareness of – and no control over – what happens inside the VM. In other words, it controls the VM itself, but it does not control what goes on inside it. Typically, an operating system runs inside of these VMs, either Linux or Windows. If one wants control and awareness of what happens inside the VM, one could apply the Bright layer on top of these VMs and operating systems.
This means that the software used to build and manage the cloud is the same as that used to manage the cluster built inside that cloud – even though the bottom is based on bare metal, and the top is based on virtual machines. The figure shows that one can continue to build exactly the same infrastructure on top of the VM layer as was achieved with bare metal, including HPC, big data, private cloud, as well as other server types. Finally, this foundation sets the stage for bursting out to the public cloud from within both the physical and virtualized infrastructures. Bright Computing can do all of this out of the box.
The conceptualization shows an approach for combining HPC and big data workloads and giving operators the flexibility to choose between bare metal and virtualized infrastructure. The next step, now in the works, is working with containers – simulated virtual machines that may look and feel like a real server from the point of view of owners and users.
Real world examples of HPC and big data clusters working together
The innovative and unique infrastructure depicted in the diagram has been in place for nearly a year at Bright Computing. It is being used to run a private cloud inside a Bright data center, where software developers stand up HPC clusters, big data clusters, and OpenStack clouds. It has also been used by quality assurance engineers to run tests, by support engineers who need to reproduce a scenario experienced at a customer site, and by systems engineers to run demonstrations.
The infrastructure has proven to be extremely flexible, enabling Bright to do a lot more with its resources. The ability to virtualize the clusters enables us to stand up and shut down the large number of clusters needed to serve customers, without having to build out a much larger data center.
Another example is a major pharmaceutical company that was looking to optimize the use of its existing server infrastructure. The company had a substantial group of HPC and big data users and wanted to deploy a private cloud in their data center in which they could mix general IT workloads with HPC workloads. The objective was to make more HPC resources available for researchers to run jobs overnight when the general IT world load was low.
Using Bright OpenStack, the company’s administrators were able to provide flexibility and customization to their user base while optimizing the use of existing resources. The solution reduced their need to invest in more hardware because they could use what they already had more efficiently. The initial deployment was so successful that similar deployments are now in use at five other sites.
—
Author: Dr. Matthijs van Leeuwen, Bright Computing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States