

Tag: Spark

Apache Flink Creators Get $6M to Simplify Stream Processing
Real-time stream processing is one of the hottest topics this week at Strata + Hadoop World, and one of the new frameworks turning heads is Apache Flink. Developed by the German company data Artisans, Flink is unique in Read more…

Finding Long-Term Solutions to the Data Scientist Shortage
As we learned in the first part of this series, the gap between demand for skilled data scientists and supply is driving salaries north of $200,000 in some areas of the country. If big data analytics is to be democratize Read more…

Machine-Learning Platform Certified For Cloudera
In the run up to next week's Hadoop confab in Silicon Valley, vendors are releasing a flock of automation and other tools aimed at beefing up the mainstream data processing framework. Among them is an attempt to incorpor Read more…

Why Hadoop Must Evolve Toward Greater Simplicity
Developers have been filing the rough edges off Apache Hadoop ever since the open source project started to gain traction in the enterprise. But if Hadoop is going to take the next step and become the backbone of analyti Read more…
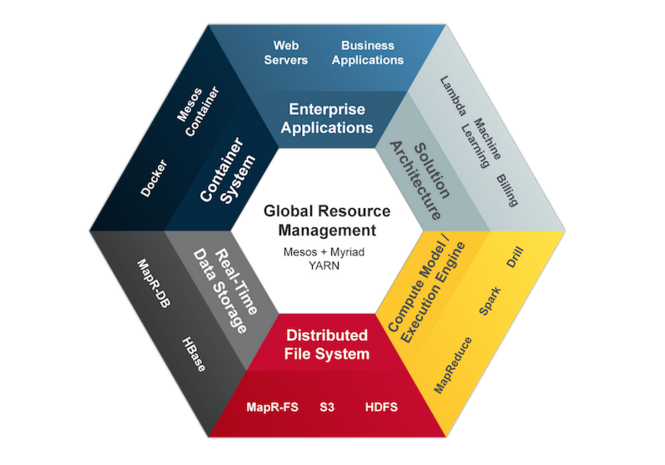
From Hadoop to Zeta: Inside MapR’s Convergence Conversion
If you're a regular Datanami reader, you likely know MapR Technologies as a Hadoop distributor, one of the three "pure play" providers alongside Hortonworks and Cloudera. But with its integrated NoSQL database, a modifie Read more…

How Big Data Can Empower B2B Sales
As consumers, we've grown accustomed to having Big Data look over us. We're no longer surprised when Amazon recommends a perfect of headphones for a 14 year-old girl, or when Target reminds us it's time to buy laundry de Read more…

See EBCDIC Run on Hadoop and Spark
Only 20,000 or so of the big beasts still exist in the wild. They're IBM mainframes, and despite the scorn of a legacy label, they continue to run critical processes companies simply don't trust to commodity Intel boxes. Read more…

MapR Joins Growing List Targeting U.S. Big Data
As federal agencies struggle to upgrade their cloud and overall IT capabilities, a leading analytics vendor is setting up shop inside the Capital Beltway in a bid to boost big data capabilities. MapR Technologies said Read more…
Hortonworks Splits ‘Core’ Hadoop from Extended Services
Hortonworks today announced a major change to the way it distributes its Hadoop software. Going forward, Hortonworks plans to update "core Hadoop" components like HDFS, MapReduce, and YARN just once a year in accordance Read more…

Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
The folks at Databricks last week gave a glimpse of what's to come in Spark 2.0, and among the changes that are sure to capture the attention of Spark users is the new Structured Streaming engine that leans on the Spark Read more…

SQL-on-Hadoop Test: Each Engine Has ‘Sweet Spots’
Business intelligence has emerged as the top workload for Hadoop, ahead of data science and ETL. That has prompted bench markers to zero in on the performance of leading SQL-on-Hadoop engines for BI use cases. AtScale Read more…

Google Releases Cloud Processor For Hadoop, Spark
Google took the wraps off of its managed Apache Hadoop and Spark service this week, saying its cloud data processing platform is intended to reduce the cost and ease management of processing big datasets. Cloud Datapr Read more…

Airlines Embracing Analytics to Stave Off Disruption
Over the past five years, we've seen the incredible rise of Uber and Airbnb, two tech-savvy startups that turned the travel and hospitality industries upside down. Now airlines are starting to fight back by embracing big Read more…
Arrow Aims to Defrag Big In-Memory Analytics
You probably haven't heard of Apache Arrow yet. But judging by the people behind this in-memory columnar technology and the speed at which it just became a top-level project at the Apache Software Foundation, you're goni Read more…
Apache Spark Surrounded By Cloud Data Services at IBM
IBM has made no secret about its admiration for Apache Spark, which it sees as the future for in-memory analytics. Today the IT giant unveiled a host of new cloud-based data services that bolsters its hosted Apache Spark Read more…

Lifting the Fog of Spark Adoption
Clients are often confused about Apache Spark, and this confusion sometimes hinders its adoption. The confusion is not about the features of Spark per se, but about installing and running the big data framework. One c Read more…

Platfora Riding High on Wave of Big Data Growth
The big data analytics business at Platfora is booming these days, accounting for 100 percent revenue growth this year. With a $30 million round in funding announced yesterday and software industry veteran Jason Zintak n Read more…

Trifacta Goes Back to the Future with Free ‘Wrangler’
Trifacta hearkened back to its roots in free software with today's launch of Wrangler, a new data preparation tool for Windows and Mac desktops. The free tool is designed to automate much of the process of cleansing dat Read more…
Teradata Puts Aster in Hadoop for IoT Analytics
The Internet of Things (IoT) is simultaneously a colossal data management challenge and the analytic opportunity of a lifetime. Teradata (NYSE: TDC) addressed both of those today with two product announcements, including Read more…

Inside Yahoo’s Super-Sized Deep Learning Cluster
As the ancestral home of Hadoop, Yahoo is a big user of the open source software. In fact, its 32,000-node cluster is the still the largest in the world. Now the Web giant is souping up its massive investment in Hadoop t Read more…
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States