

Tag: Hive

Big Performance Gains Seen Across SQL-on-Hadoop Engines
You can't really go wrong these days when it comes to picking a SQL-on-Hadoop engine. As long as you stick to the mainstream open source products like Hive, Impala, Spark SQL, and Presto, your SQL queries are likely runn Read more…

ODPi Tackles Hive with Latest Hadoop Runtime Spec
ODPi today unveiled the second major release of its Runtime Specification that's geared at setting a standard for Hadoop components to ensure greater interoperability among distributions and third-party products. New add Read more…
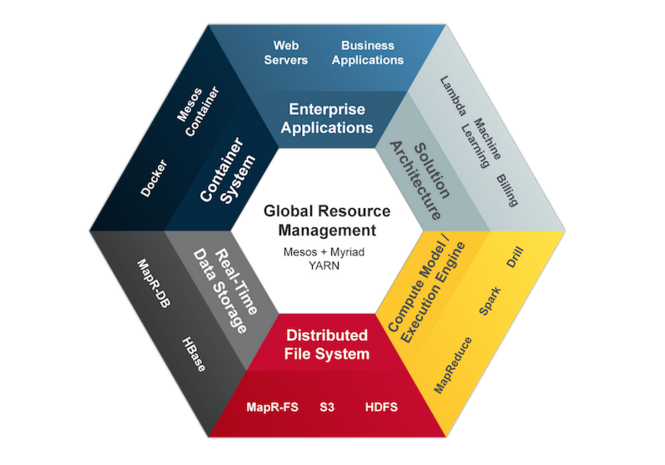
From Hadoop to Zeta: Inside MapR’s Convergence Conversion
If you're a regular Datanami reader, you likely know MapR Technologies as a Hadoop distributor, one of the three "pure play" providers alongside Hortonworks and Cloudera. But with its integrated NoSQL database, a modifie Read more…

SQL-on-Hadoop Test: Each Engine Has ‘Sweet Spots’
Business intelligence has emerged as the top workload for Hadoop, ahead of data science and ETL. That has prompted bench markers to zero in on the performance of leading SQL-on-Hadoop engines for BI use cases. AtScale Read more…

Google Releases Cloud Processor For Hadoop, Spark
Google took the wraps off of its managed Apache Hadoop and Spark service this week, saying its cloud data processing platform is intended to reduce the cost and ease management of processing big datasets. Cloud Datapr Read more…

Distributed Computing Tops List of Hottest Job Skills
If you have cloud and distributed computing skills, your job prospects for 2016 are golden. That's because those particular job skills—which parallel the rise of Hadoop and other distributed computing frameworks--topp Read more…

Picking the Right SQL-on-Hadoop Tool for the Job
SQL is, arguably, the biggest workload many organizations run on their Hadoop clusters. And there's good reason why: The combination of a familiar interface (SQL) along with a modern computing architecture (Hadoop) enabl Read more…

Three Ways Zoomdata Makes Big Data Pop
When it comes to big data visualization tools, there's no shortage of players. Tableau, Qlik, Spotfire, and Microstrategy are established incumbents with big followings. But there's a fresh crop of visualization tools ma Read more…

Three Tips for Building a Big-Data Back-End for Your Mobile App
With more companies striving to become data-driven, many businesses are developing mobile applications and integrating big data analytics for their products or services. As companies expand, along with their user bases, Read more…

Kyvos Debuts OLAP for Hadoop
Many technology pros view OLAP as a legacy technology, a holdover from the days of data warehousing that doesn't have a place in today's big data world. But several startups are fighting to change that perception, includ Read more…

AtScale Claims to Mask Hadoop Complexity for OLAP-Style BI
AtScale came out of stealth mode today with new software designed to trick business intelligence tools into thinking that Hadoop is a standard database upon which they can perform OLAP-style analysis, as opposed to the h Read more…
Tableau Aims to Speed Analytics with V9
Tableau Software has long positioned itself as a provider of tools that help you visualize big data, but hooking up to big data sources has not always been easy, and the resulting analyses have not always run as fast as Read more…

Deep Dive Into Oracle’s Emerging Big Data Stack
Oracle has a lot of turf to protect in the multi-billion-dollar relational database market, where it owns a dominant share of the market. That creates a natural tension when it comes to big data technologies like Hadoop Read more…

How Advances in SQL on Hadoop Are Democratizing Big Data–Part 2
In a previous article, we discussed several key advances in SQL on Hadoop that are making Big Data capabilities increasingly accessible to analytics organizations. While SQL democratizes Big Data by leveraging convention Read more…

How Advances in SQL on Hadoop Are Democratizing Big Data–Part 1
September 2014 marked the anniversary of Edgar F. Codd’s 1969 introduction of “A Relational Model of Data for Large Shared Data Banks”, which is a compellation of research and theories that ultimately provided the Read more…
Hortonworks Goes Broad and Deep with HDP 2.2
From full support for Apache Spark, Apache Kafka, and the Cascading framework to updated management consoles and SQL enhancements in Hive, there's something for everybody in Hortonworks' latest Hadoop distribution, which Read more…
Hortonworks Hatches a Roadmap to Improve Apache Spark
Hortonworks today issued a broad and detailed roadmap outlining the investment it would like to see made to Apache Spark, the in-memory processing framework that has become one of Hadoop's most popular subprojects. The p Read more…
Yahoo: We Run the Whole Company on Hadoop
Hadoop is absolutely critical to the operations of Yahoo, executives with the company said this week at the Hadoop Summit. While the company, which spun out Hortonworks in 2011, is moving away from “traditional” Hado Read more…
Faceboook Gets Smarter with Graph Engine Optimization
Last fall, the folks in Facebook's engineering team talked about how they employed the Apache Giraph engine to build a graph on its Hadoop platform that can host more than a trillion edges. While the Graph Search engine is capable of massive graphing tasks, there were some workloads that remained outside the company's technical capabilities--until now. Read more…
Teradata Makes Data Warehouse More Hadoop-ish
It's no stretch to say that the folks at Teradata aren't the world's biggest fans of Hadoop. If nothing else, the hoopla surrounding Hadoop has caused some Teradata customers to question future investments in the company's traditional data warehouse technology. But with today's launch of the next generation of Teradata's flagship platform, the company has made its software a little more Hadoop-ish, particularly when it comes to taking the compute to the data and supporting semi-structured file formats. Read more…
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States