

Automate your Google Cloud Data Warehouse on BigQuery with Cloud Dataprep

About the author: Geoffroy de Viaris is a Data and Analytics Project Manager at a high fashion luxury goods manufacturer.
I’ve been working for more than 10 years with big businesses in the foodservice industry as well as luxury goods manufacturers managing, cleaning, and enhancing databases with millions of records. I’ve always had one goal in mind: provide our business with quality insights to monitor operations, inform decisions, and drive strategy. Over the years, I’ve encountered various technologies and processes, and I can say that I’ve been able to identify the best practices and tools that provide the highest impact for business. I’m now able to deliver scalable data warehouses for self-service analytics in record time.
Creating a data warehouse used to require a large team, long lead time, and a consequently large budget. Now, there is an affordable way for you to design your data warehouse quickly thanks to some innovative solutions in the cloud.
I recently delivered a webinar about this, and wanted to summarize the key takeaways to put you on the fast track with an end-to-end demo to get you started on your new cloud analytics journey. This blog focuses on the Google Cloud analytics suite and on Cloud Dataprep in particular so you can turn your raw data into gold. I also added a few best practices recommendations so you can be sure to scale from day one.
The old way: On-premise analytics
The main strategy for many years was to use Extract Transform Load (ETL) tools on employees’ computers or in the company server room, a.k.a. “on-premise”. The goal here was to prepare the data (deduplication, cleaning, combining, etc.) to create your local data warehouse. This worked quite well for some time but had a few limitations.
ETL/On-Premise limitations: Forecast, Scalability & Price
This approach can work, but it’s important to bear in mind what your current data strategy is and where your business is heading.
As time passes, the volume of data you deal with will grow, and it may be hard to forecast your data needs in advance. Having your own server room is costly, and you don’t want to pay for something you won’t need. Scaling your servers up or down requires resources and time that turn into big costs and waste. I can tell you from experience that many companies, big or small, have a hard time forecasting their data needs in the long run. Which brings us to a new approach to tackle analytics initiatives.
The new way: Cloud Analytics
Over the past few years, the cloud has increasingly been adopted by big and small businesses because of its flexibility, price attractiveness, as well as its robust and secure environment for data. Let’s see how it can fix on-premise limitations. With the cloud, you can:
- Scale-up and scale-down in real-time as required without forecasting future needs
- Pay only for what you use, which is often cheaper and more secure than doing it yourself
- Process vast amounts of data faster than on-premise, thanks to the large number of servers available to parallelize the load
- Change your value to become a business partner versus a technology geek
Getting the data ready for analytics
With the cloud, a new generation of data services has been designed specifically to take full advantage of its benefits. This blog post uses Google Cloud to demonstrate data preparation as a new approach to designing and automating a data warehouse pipeline. In the Google Cloud, we can leverage Cloud Dataprep by Trifacta, which is the native tool Google Cloud provides for data preparation. It allows your teams to collaborate easily and save valuable time in getting data ready for analytics.
Let’s get started with the basic concepts of data preparation for data warehousing to turn your raw data into refined data (cf. Fig.1).
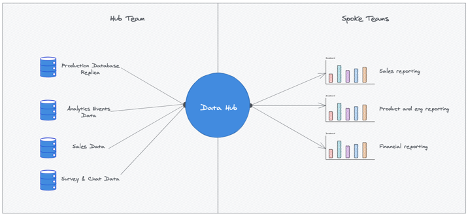
Raw data refers to your input data before it has gone through preparation (structuration, cleaning, enriching, validation, deduplication, combining, etc.). Input data can come from various sources, such as files (Excel or Google spreadsheets, CSV, etc.), Cloud Services such BigQuery (Google Cloud Data Warehouse), Google Cloud storage, and additional databases and applications.
Refined data refers to the prepared data that often resides in your Data Warehouse. Once data has been refined, it’s ready to be used in various ways. Some examples include:
- As a backend database or for direct analysis
- Implemented into a dashboard, with tools such as Data Studio, Tableau Software, QlikView, etc.
- Used to build machine learning models
The Cloud Dataprep user experience and concepts
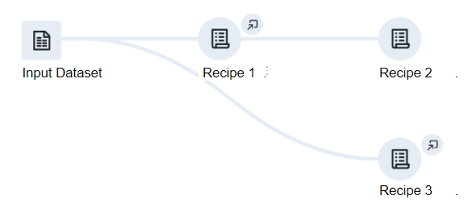
To use Dataprep, it’s useful to get familiar with a few key concepts:

- The library is where you import your datasets (files and databases)
- A recipe is a list of steps that transforms one dataset into another
- The flows section is where you can arrange recipes and link them together
- The jobs section is where you run your recipes and flows and monitor the results
Guiding you to your first dashboard
Next, we’ll go through the steps required to leverage Cloud Dataprep to transform your raw data into refined data in Google BigQuery. We’ll use an e-commerce sales analytics example where we want to display the refined data in an attractive dashboard.

For reporting and dashboarding we’ll use Data Studio, Google’s free data visualization service. Once we’ve gone through the steps, the final result will look like this:

Below is a recorded demo you can follow to design your end-to-end data warehouse from data acquisition to dashboarding.

