


May 28, 2024
J.P. Morgan Launches ‘Containerized Data’ Solution in the Cloud

(Tee11/Shutterstock)
Getting access to consistent, high-quality data ranks as one of the toughest challenges in big data, advanced analytics, and AI. It’s a challenge that is being taken up by Fusion by J.P. Morgan with its new Containerized Data offering, which provides institutional investors with consistent, enriched data that’s been standardized with a common semantic layer.
The worst-kept secret in big data is that data prep consumes the vast majority of time in analytics, machine learning, and AI projects. Raw data does contain signals that data scientists so desperately want to leverage for competitive gain, but that data must be thoroughly cleansed and standardized before it can be merged with other data sets for analysis or fed into machine learning algorithms to train predictive models.
J.P. Morgan hopes to reduce the data prep time with Containerized Data, which it says will provide investors with high quality data for their downstream data needs. No matter what type of data they’re working with or analysis they’re doing, the goal with Containerized Data, which is being offered through its cloud-based data mesh and data lakehouse offering, dubbed Fusion by J.P. Morgan–is to make it look, feel, and behave the same across sources.
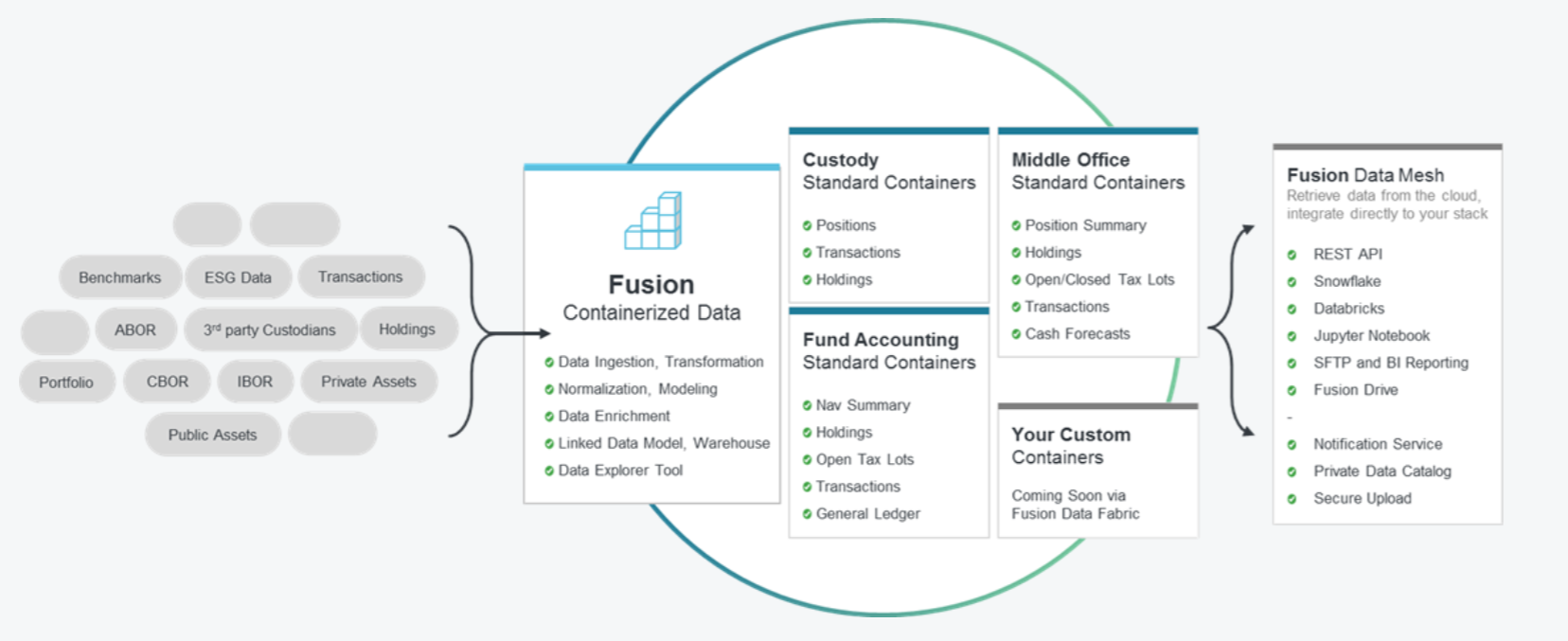
Image courtesy J.P. Morgan
“This end-to-end solution provides investors with consistent and enriched data across business services, leveraging a new common semantic layer to model and normalize data across multiple providers, sources, types and structures,” the bank says in a press release last week.
“Fusion ingests, transforms, and links data, making it interoperable and ready for AI and ML applications. Investors can access data in consistent containers anytime, using cloud-native channels, including API, Jupyter notebooks, Snowflake, Databricks and more,” the bank says.
Containerized Data works with a variety of J.P. Morgan and non-J.P. Morgan-based data, including transactions, benchmarks, holdings, portfolios, public assets, ESG data, and ABOR, CBOR, and IBOR data. As data is ingested into Containerized Data, it’s normalized and harmonized according to data standards set and enforced by various containers in the solution, including custody, middle office, fund accounting, and custom containers.

(Konektus Photo/Shutterstock)
“Linked data in Fusion enables a complete portfolio overview of each element across clients’ portfolios and accounts, integrated into a single panoramic view,” the company says. “With all investment data normalized and linked, it’s easy to see your custody, middle office, fund accounting data and more, including public and private assets, in one place.”
Linked data makes it easy for analysts or other end users to explore available data, even data originating from different domains. When it comes time to analyzing the data, the Containerized Data supports a data mesh that allows individual teams to consume the normalized and standardized data in their choice of platform, including on-prem notebooks like Jupyter and cloud-based platforms like Databricks or Snowflake.
“We understand institutional investors’ nuanced data challenges, and with Containerized Data, we’re addressing the most pressing needs we hear from our clients,” Jason Mirsky, head of data solutions for J.P. Morgan’s securities services, said in the press release. “Our financial data expertise, vast reference data universe and strategic industry collaborations enable us to model data in ways that other firms can’t, solving unique data frustrations for clients.”
Related Items:
Breaking Down Silos, Building Up Insights: Implementing a Data Fabric
What’s Hot in the Data Preparation Market: A Look at Tools and Trends
Applications:
Data Management
Sectors:
Financial Services
Leading Solution Providers
















