


December 5, 2023
Inside AWS’s Plans to Make S3 Faster and Better

(Tee11/Shutterstock)
As far as big data storage goes, Amazon S3 has won the war. Even among storage vendors whose initials are not A.W.S., S3 is the defacto standard for storing lots of data. But AWS isn’t resting on its laurels with S3, as we saw with last week’s launch of S3 Express Zone. And according to AWS Distinguished Engineer Andy Warfield, there are more changes and optimizations planned for S3 on the horizon.
The big get with S3 Express One Zone, which was unveiled a week ago at re:Invent 2023, is a 10x reduction in latency, as measured from the moment a piece of data is requested and when S3 delivers it. It delivers data in less than 10 milliseconds, which is darn fast.
When the lower latency and the higher cost of S3 Express One Zone relative to regional S3 are factored in, it corresponds with a 80% reduction in total cost of ownership (TCO) for some workloads, according to AWS. Considering how much big companies spend on big data storage and processing, that’s a lot of dough.
So, how did AWS achieve such remarkable numbers? “It’s not a simple answer,” Warfield said. AWS used several techniques.
For starters, it ditched the two extra copies of data that AWS automatically creates in different Availability Zones (AZs) with regional S3 and other storge products. Those extra two copies protect against data loss in the event that the primary and first backup copy are lost, but they also add latency by increasing the amount of data sent over networks before storage events can be completed. The offering still keeps two backup copies of customer data, but they are stored locally.
“By moving things to a single AZ bucket, we reduce the…distance the request had to travel,” Warfield said during an interview at re:Invent last week. “It’s still an 11 nines product, but it’s not designed to be resilient to the loss of a facility like regional S3 is.”
S3 Express One Zone is the first new bucket type for S3 since AWS launched the product back in 2006, Warfield said, but it’s not the first AWS storage product that stores its data in single site. “EBS [Elastic Block Store] is built that way as well,” he said.
Another technique AWS used to slash the network overhead of its distributed storage repository is by moving authentication and authorization checks out of the mainline. Instead of requiring authentication and authorization checks to be completed with each individual data request, it’s doing it all at the beginning of the session, Warfield said.
“We observed…that the cost of doing [individual checks] ended up adding a bunch of latency,” he said. “Each request had to pay a price. And so we redesigned the protocol to hoist those checks out to a session-level check. So when you first connect with the SDK with the client, you authenticate into S3. And then we’re able to cache that for the session and really limit the overhead of per-access checks.”
AWS is still delivering the same level of security, Warfield said. But all the heavy lifting is being moved to the front of the session, enabling more lightweight checks to be done from that point forward, until something changes in the policy, he said.
Might we see this in the mainstream regional S3 product? “It’s a great question,” Warfield said. “I think we may explore that.”
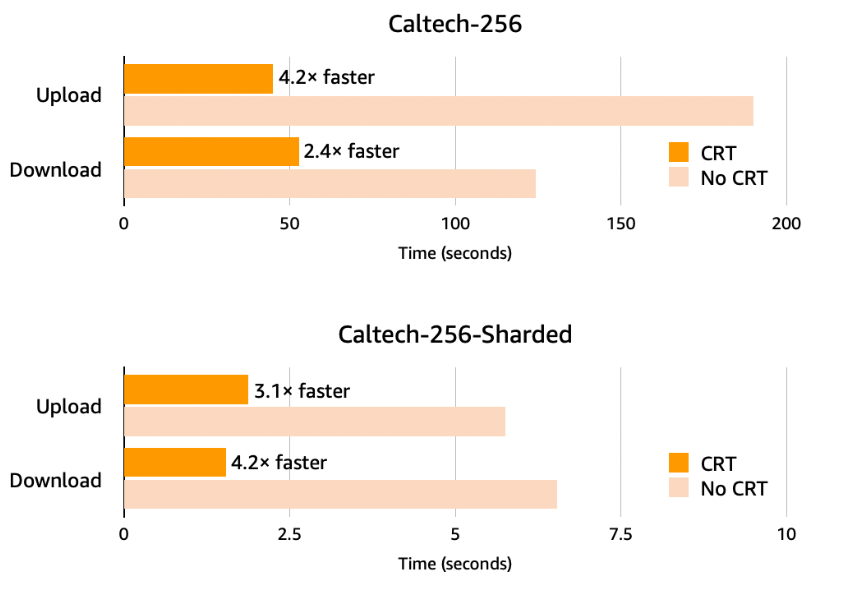
The new PyTorch library in the AWS CRT improves data loading times from S3 (Image source AWS)
AWS is also using “high performance media” to boost performance and cut latency with S3 Express One Zone, Warfield said. While that may seem to imply that AWS is using NVMe drives, AWS has a policy against identifying exactly what media it’s using under the covers. (This is the same reason why it’s never been confirmed by AWS, although it has been widely suspected for some time, that S3 Glacier is based on tape drives.)
But S3 Express One Zone isn’t the only way AWS is looking to speed up data serving out of S3. Earlier this year, it launched the Common Runtime, or CRT, which is a group of open source, client-side libraries for the REST API that are written in C and that function like a “souped-up SDK,” Warfield said.
“It manages all of the connections and requests going from the client to S3,” he said. “So it auto-parallelizes everything. It tracks health. It kind of treats S3 like the giant distributed system that it is. That library aims to get NIC entitlement, to saturate the network interface for request traffic to S3. and we’ve taken it as a tool and linked it into a whole bunch of other client libraries.”
AWS made a couple of CRT-related announcements at re:Invent last week. For starters it announced that the AWS Command Line Interface (CLI) and SDK for Python are now integrated with the CRT. The end result is that users should see better performance on machine learning workloads developed with PyTorch, Warfield said. “For data loading and checkpointing in PyTorch, you just get automatic amazing performance off of S3,” he said.
Earlier this year, AWS launched Mountpoint, which wrappers S3 GET/PUT requests in an HDFS dialect, and is made accessible via the CRT. Mountpoint is designed to make it easier to bring tools developed in the Hadoop ecosystem into S3. For the past five years or so, AWS has been getting a lot of requests to bolster S3 and make it more compatible and performant (i.e. less latency) for Hadoop-era analytics tools.
“In building out the scale of S3, we ended up building up this huge throughput window into the data, and people running Apache Hadoop, MapReduce jobs or Spark would burst up and they would transfer terabytes of data per second through that,” Warfield said. “And now, as we’re moving into these more direct engagements, with training and inference or people just writing apps directly to S3, we need to close the latency thing.”![]()
AWS has worked with many customers to optimize their analytics tools to work with data in S3. It’s written white papers about it, which people can read if they like. The goal with CRT is to build those performance optimizations directly into the product so that people can get them automatically, Warfield said.
“So things like, if you want to transfer a ton of data out of S3, here’s how to spread that load across the front-end fleet, and get really good performance,” he said. “Because it’s a distributed system, sometimes you’re going to hit a host that’s not behaving as well as it should be, and so you should detect that and move it over. This is stuff that customers were already doing, and with the CRT release, we’re making it automatic.”
The company has more investments planned for S3, including outfitting S3 Express One Zone with more of the features that are available in regional S3, such as automated data tiering capabilities. The company will be customer-directed and look to smooth out “whatever sharp edges folks face as they use it,” Warfield said.
“There’s a ton of deep technical investment under the cover in the various aspects of the system,” Warfield said about Express. “We’re not talking as much about what we’re planning to do with that next, but I’m pretty excited about how we’re going to be able to use that to launch a whole bunch of pretty [cool] stuff.”
AWS maintains 700,000 data lakes on behalf of customers, spanning many exabytes of data and a mind-boggling 350 trillion objects. As these customers consider how they can leverage AI, they’re looking to their data assets and AWS to help. Express One Zone plays an important role there.

Andy Warfield is a distinguished engineer at AWS who works on S3 and storage
“Express is a way to move data that they expect a lot of frequent access on onto faster media,” Warfield said. “And the client work that we’ve done with the PyTorch connector and Mountpoint speeds up that end of the data path.”
Many of these customers have invested a lot of time and money in data management and data preparation in their data lakes, and are very well positioned to move quickly with AI, Warfield said.
“A lot of the established data lake customers have been so fast to be able to jump on generative AI tooling. It’s been rewarding to see,” Warfield said. “And a lot of the work that we’re doing with Bedrock…is the fact that it’s all API-driven. You can take a model, fine tune onto a private copy with the data in your data lake, and get going in an afternoon.”
The Hadoop-era of big data has passed, but many of the lessons live on. One of those is moving the compute to the data, which is something that AWS has embraced–at the insistence of its customers, of course.
“[Customers] are really apprehensive about taking their data to a detached set of tooling, because they’ve already done all this work on governance and data perimeter, things like that. They have a practice around it,” Warfield said. “And so the Amazon approach across all of this that really resonates with the data lake customers is bringing the models to your data.”
Related Items:
AWS Launches High-Speed Amazon S3 Express One Zone
Five AWS Predictions as re:Invent 2023 Kicks Off
Object Storage a ‘Total Cop Out,’ Hammerspace CEO Says. ‘You All Got Duped’
Editor’s note: This article has been updated to reflect the fact that S3 Express One Zone still stores two backup copies of data, but they’re stored in the same Availability Zone and not different AZs, as with standard S3.
Applications:
Data Management
Vendors:
AWS
Leading Solution Providers
















