


November 30, 2023
AWS Adds Vector Capabilities to More Databases

(theromb/Shutterstock)
Amazon Web Services is adding vector search and vector embedding capabilities to three more of its database services, including Amazon MemoryDB for Redis, Amazon DocumentDB, and Amazon DynamoDB, the company announced yesterday at its re:Invent 2023 conference. It doesn’t look like the cloud giant will be adding a dedicated vector database to its offerings.
Demand for vector databases is surging at the moment, thanks to the explosion of interest in generative AI applications and large language models (LLMs). Vector databases are a critical component of the emerging GenAI stack because they store the vector embeddings generated ahead of time by LLMs, such as those offered in Amazon Bedrock. At runtime, the GenAI user input in matched to a stored embedding by using a nearest neighbor search algorithm in the database.
AWS added support for pgvector, a vector engine plug-in for PostgreSQL, to Amazon Relational Database Service (RDS), its PostgreSQL-compatible database offering, in May. It added pgvector support to Amazon Aurora PostgreSQL-Compatible Edition in July. With its announcements this week at re:Invent, it’s adding vector capabilities to its NoSQL database offerings.
The addition of vector capabilities to Amazon MemoryDB for Redis will cater to customers with the highest performance demands for vector search, chatbots, and other generative AI applications, said AWS VP of database, analytics, and machine learning Swami Sivasubramanian.
(Image source: AWS)
“Our customers ask for an in-memory vector database that provides millisecond response time, even at the highest recall and the highest throughput,” he said during his re:invent 2023 keynote on Wednesday. “This is really difficult to accomplish because there is an inherent tradeoff between speed was as relevant of query results and throughput.”
Amazon MemoryDB for Redis customers will get “ultra-fast” vector search with high throughput and concurrency, Sivasubramanian said. Even with millions of vectors stored, the service will deliver single digit millisecond response time, “even when tens of thousands of queries per second at greater than 98% recall,” he said. “This kind of throughput and latency is really critical for use cases like fraud detection and real time chat bots, where every second counts.”
The company also announced the general availability of vector search capabilities in Amazon DocumentDB and Amazon DynamoDB, as well as the GA of the previously announced vector engine for Amazon OpenSearch Serverless.
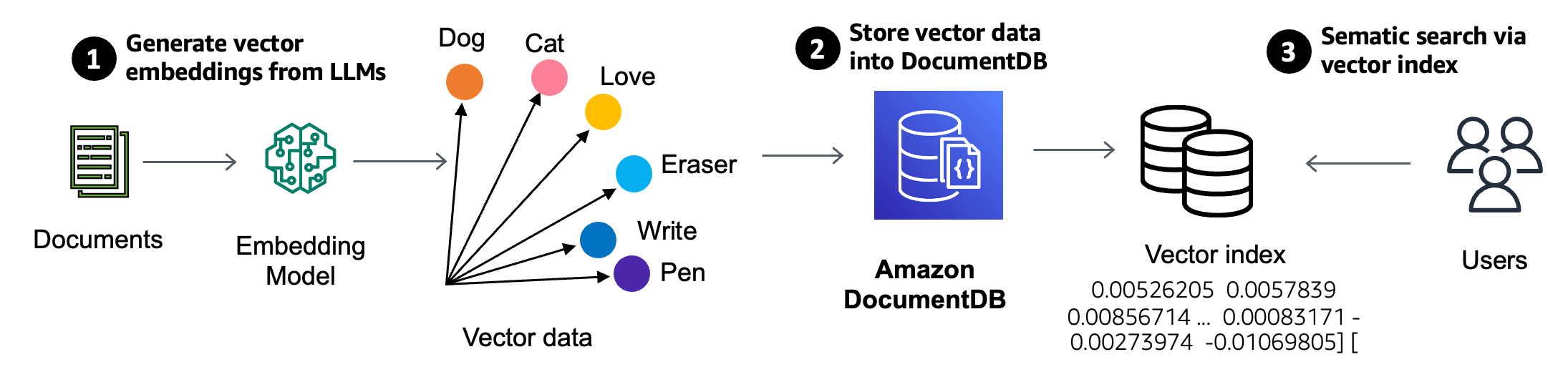
Adding vector search to DocumentDB allows customers to store their vector embeddings right next to their JSON business data. That simplifies the GenAI stack, says Channy Yun, a principal developer advocate for AWS.

AWS VP of database, analytics, and machine learning Swami Sivasubramanian
“With vector search for Amazon DocumentDB, you can effectively search the database based on nuanced meaning and context without spending time and cost to manage a separate vector database infrastructure,” Yun writes in a blog. “You also benefit from the fully managed, scalable, secure, and highly available JSON-based document database that Amazon DocumentDB provides.” For more information on the vector capabilities in DocumentDB, read this blog.
The company also announced the GA of a vector engine in OpenSearch Serverless, the on-demand version of AWS’s Elasticsearch-compatible database. This previously announced capability will allow OpenSearch users to utilize similarity search along with other search methods, like full text search and time-series analysis, Yun writes.
“You can now store, update, and search billions of vector embeddings with thousands of dimensions in milliseconds,” Yun writes in a separate blog. “The highly performant similarity search capability of vector engine enables generative AI-powered applications to deliver accurate and reliable results with consistent milliseconds-scale response times.”
A zero-ETL connection between OpenSearch Serverless and Amazon DynamoDB, the company’s proprietary key-value store database, gives DynamoDB customers access to OpenSearch Serverless’s vector search capabilities, the company says.
While it offers just about every other database type–including a graph database, which also was enhanced with vector capabilities–AWS did not announce a dedicated vector database, as some were expecting. It turns out that AWS customers prefer vector capabilities in existing databases rather than a dedicated vector database offering, according to Sivasubramanian.
“They told us they want to use them in their existing databases so that they can eliminate the learning curve associated in terms of the learning a new programming paradigm, tools, APIs,” Sivasubramanian said during his re:Invent keynote on Wednesday. “They also feel more confident [in] existing databases that they know how it works, how it scales, and its availability, and also evolves to meet the needs of vector databases.”
Another benefit of storing vector embeddings in an existing database is that the applications will run faster with less data overhead, Sivasubramanian added.
“There is no data sync or data movement to worry about,” he said. “For all of these reasons, we have heavily invested in adding vector capabilities to some of our most popular databases, including Amazon Aurora, Amazon RDS, and OpenSearch services.”
Related Items:
Amazon Launches AI Assistant, Amazon Q
Five AWS Predictions as re:Invent 2023 Kicks Off
Retool’s State of AI Report Highlights the Rise of Vector Databases
Leading Solution Providers
















