


November 27, 2023
Mastering Data Modeling: Insights from a Data Product Developer

(Tee11/Shutterstock)
Let’s not deny it; we’ve all been captivated by the elegant symmetry of Data Products. If you haven’t encountered them yet, you might be living under a rock. But don’t worry, before we delve into advanced solutions, let’s first explore the foundational concepts, as we always do.
On the other hand, data modeling has been a timeless warrior, empowering data teams, from novices to experts, to navigate the dense and intricate jungle of data. But if data modeling were the ultimate solution:
→ Why do organizations increasingly voice dissatisfaction with the ROI from their data initiatives?
→ Why are data teams burdened with the ever-escalating task of proving the value of their data?
→ Why do data models often become congested and more costly than their intended benefits?
The answer lies in the fact that we haven’t been approaching data modeling correctly. While data modeling as a framework is ideal, the process of constructing a data model often rests on shaky foundations.
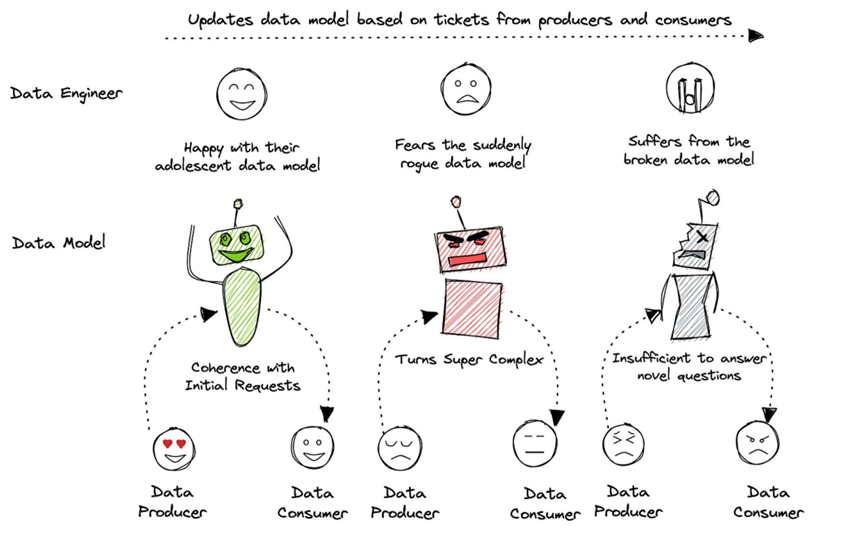
Changing data models threaten the happiness of data producers and consumers (Source: Travis Thomspon and Animesh Kumar)
The lack of consensus and transparency between business teams responsible for the business logic and IT teams managing the physical data is a perennial challenge. When one side undergoes even minor restructuring, it can throw the other side into disarray, requiring delicate adjustments to avoid disrupting critical data pipelines.
In this article, we will provide a concise overview of data modeling and explore the transformative potential of data products. We’ll delve into the solutions that the data product paradigm offers in the context of modeling and examine the key factors driving this evolution.
This piece is tailor-made for those who lead data teams or hold positions of influence in data development within their teams or organizations.
Understanding the Big Picture
Data modeling isn’t the sole pillar bearing the weight of the data challenges. In fact, it often comes later in the data journey, after several other foundational pillars have been established. To truly grasp the issues surrounding data modeling, we need a high-level understanding of all the layers that precede it.

Data Modeling resides near the far end of the semantic layer, just before data is operationalized for various distinct use cases (Source: Travis Thomspon and Animesh Kumar)
The Role of Data Models
Now that we have a rough idea of where a data model fits within the vast data landscape, let’s explore what it can achieve from its position on the semantic floor.
If you were to embody a data model, you’d essentially become a librarian. Your responsibilities would include:
- Responding to a wide range of queries from data consumers across diverse domains, effectively serving the books they seek;
- Empowering data producers to generate relevant data and ensuring they are placed on the appropriate shelves;
- Developing a profound understanding of the relationships between various data entities to present related information;
- Reorganizing shelves whenever new books arrive to make space for fresh information in the right location;
- Maintaining a set of metrics or KPIs to glean insights from the existing data inventory;
- Managing metadata on library users and visitors to govern access;
- Curating metadata on books to detect any tampering or damage.
However, as we discussed in the introduction, data models face scalability challenges over time within prevailing data stacks due to the constant back-and-forth interactions with data producers and consumers. The image below summarizes this tug-of-war and underscores the burden it places on the central data engineering team, as well as the anxiety it generates for both producers and consumers.
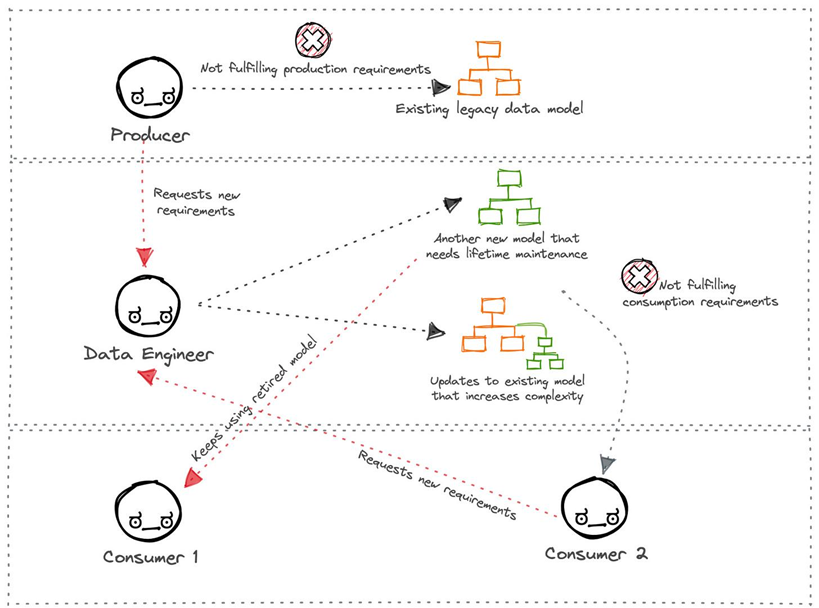
Representation of complexity and collaboration issues over time in traditional data modeling (Source: Travis Thomspon and Animesh Kumar)
Leveraging Data Products for Modeling Challenges
It’s important to clarify what we mean by a “data product” in many instances throughout this piece. While it might seem repetitive during the writing process, it’s essential due to the unintentional inflation of the term “data product” in the community.
In the data realm, numerous brands attach the “data product” label to their offerings. However, upon closer examination, these products often bear little resemblance to the true essence of a data product as it was originally intended.
A data product is more than just data; it encompasses not only the data itself but also the tools and capabilities that empower its use.
🗒️ Data Product = Data & Metadata + Code + Infrastructure
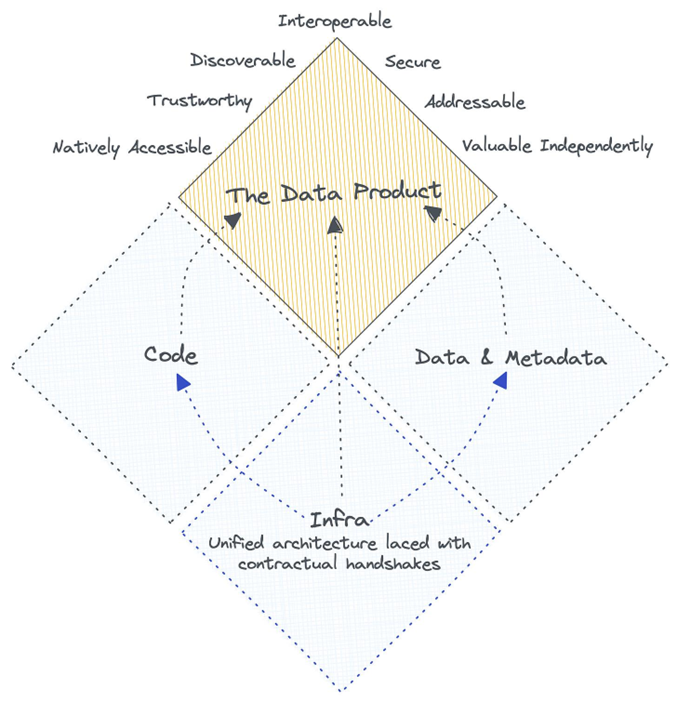
The Data Product Quantum (Source: Travis Thomspon and Animesh Kumar)
Visualizing Data Products on a DDP Canvas
Now that we have a clearer understanding of what constitutes a Data Product, let’s explore how to visualize it within the context of the data landscape.
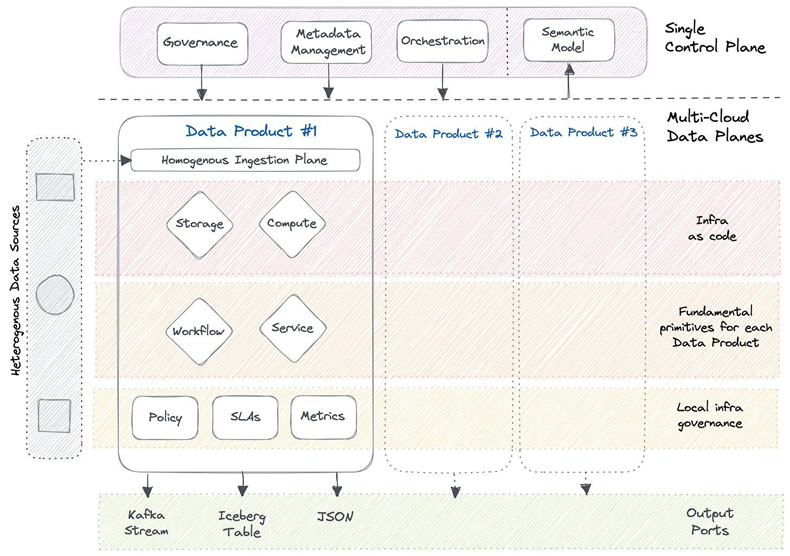
Representation of Data Products as on a DDP Infrastructure Specification (Source: Travis Thomspon and Animesh Kumar)
The above provides a high-level overview of Data Products, focusing on how they are enabled through the infrastructure specifications of a data developer platform (DDP)
Key Observations to Note
- Dual Planes: The central control plane offers complete visibility across the data stack, overseeing metadata across various sources and data products. In contrast, data planes are isolated instances deployed for specific domains, data product initiatives, or use cases.
- Infrastructure Isolation: Each data plane provides complete isolation, facilitating the construction of data products. Isolated data planes include fundamental building blocks or primitives for custom infrastructure, such as Storage and Compute.
- Platform Orchestration: The platform orchestrator is the core of the DDP infrastructure specification, enabling centralized change management through standard configuration templates. This abstraction simplifies data development by eliminating dependencies and complexities across environments, planes, or files.
- Infrastructure as Code (IaC): IaC practices involve building and managing infrastructure components as code, granting programmatic access to data. Think of it as applying object-oriented programming principles to data, allowing abstraction, encapsulation, modularity, inheritance, and polymorphism. Code becomes an integral part of independent units served as a Data Product.
- Local Governance: While central governance is crucial for managing cross-domain and global policies, data product-level governance ensures local hygiene. This includes domain-specific policies, SLAs, and operational metrics.
- Embedded Metadata: Every operation in the data stack generates metadata that enriches data products by providing context and hidden meta-relations. Metadata adds meaning to data.
- Disparate Output Ports: Data products have the flexibility to present data in multiple formats, aligning closely with practical use cases and various personas.
How Data Products Address Traditional Modeling Challenges
Before we delve into solutions, let’s briefly explore the persistent challenges of traditional data modeling.
Challenges of Traditional Modeling
- Rapid changes lead to complex and unwieldy data models that struggle to handle novel queries;
- Governance and data quality are often considered as an afterthought, resulting in difficulties in enforcement;
- Striking the right balance between normalization and denormalization remains a challenge.
- Continuous iterations between teams are required for updates, fixes, or new data models;
- Fragile pipelines break with any hint of data evolution, which is frequent in the world of data;
- Creators of data models (central engineering teams) often lack a deep understanding of the business landscape and requirements, exacerbating the above issues.
Challenges of Modern Data Delivery
- Data from disparate sources is often ingested into data lakes without transformation, leaving data engineers to adapt it for specific purposes;
- Data lakes can quickly become data swamps, with only a few experts capable of navigating the complexity;
- Semantic, governance, and quality issues arise when data becomes incomprehensible, making it challenging to define rules and policies;
- Businesses face centralized bottlenecks when trying to operationalize data for decision-making, hindering real-time insights even for batch data.

Representation of Data Products on a DDP Infrastructure Specification (Source: Travis Thomspon and Animesh Kumar)
Decoupled Data Modeling
In this landscape, a logical abstraction or semantic data model separates the modeling layer from the physical data realm. The Semantic Model utilizes data entities provided as data products.
- This approach enables right-to-left engineering, allowing business teams to define the business landscape and data’s purpose. Central engineering teams, with a partial view of the business, are freed from the burden of repeatedly fixing subpar models and can focus on mapping;
- Ownership of the model shifts to the business front, granting flexibility while bestowing accountability on business users;
- Redundancy and expensive migration at the physical level are minimized by enabling materialization through logical channels that activate on demand;
- Robust local governance is established, encompassing security policies, quality rules enforced through SLAs, and observability metrics for data and infrastructure, leveraging the expertise of domain users.
Embedded Quality as Governance
Not all data should be curated as data products, as it can lead to impractical data proliferation. Instead, organizations should focus on curating high-definition product-like experiences for core entities. For example, a Customer360 data product provides a comprehensive view of the customer entity. Quality checks and governance standards are declaratively defined by business and engineering counterparts, ensuring that data activated through the semantic data model is of high quality and well-governed.
Managing Data Evolution
Data evolution, a common challenge for data pipelines, is addressed in the data product landscape through specification files or data contracts. These files specify the semantics and shape of the data, and any changes are caught at the specification level, allowing for dynamic configuration management or single-point changes across pipelines, layers, environments, and data planes. Non-desirable changes can be revised or validated at the higher specification level.
Summary
In this article, we provided an overview of the objectives of data models, explored data products as a construct, and delved into the data product landscape as implemented through a DDP infra spec. We’ve seen how this landscape becomes an enabler for data modeling.
We discussed how abstracting the data model as a semantic construct can shift ownership and accountability to business teams, relieving central teams of burdens and eliminating bottlenecks.
In conclusion, we’ve demonstrated how data products, positioned as a layer before logically abstracted data models, can effectively address data quality, governance, evolution, and collaboration challenges commonly encountered in both traditional and modern data delivery approaches.
Please note that many concepts in this article are conveyed through diagrams for ease of consumption.
About the authors: Travis Thompson is the Chief Architect at The Modern Data Company as well as the Chief Architect of the Data Developer Platform Infrastructure Specification. Over the course of 30 years in all things data and engineering, Travis has designed state-of-the-art architectures and solutions for top organizations such as GAP, Iterative, MuleSoft, HP, and more. You can view his LinkedIn profile here.
Company as well as the Chief Architect of the Data Developer Platform Infrastructure Specification. Over the course of 30 years in all things data and engineering, Travis has designed state-of-the-art architectures and solutions for top organizations such as GAP, Iterative, MuleSoft, HP, and more. You can view his LinkedIn profile here.
 Animesh Kumar is the Chief Technology Officer and Co-Founder at The Modern Data Company a co-creator of the Data Developer Platform Infrastructure Specification. During his 30+ years in the data engineering space, Animesh has architected engineering solutions for a wide range of A-Players, including NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI, and more. You can view his LinkedIn profile here.
Animesh Kumar is the Chief Technology Officer and Co-Founder at The Modern Data Company a co-creator of the Data Developer Platform Infrastructure Specification. During his 30+ years in the data engineering space, Animesh has architected engineering solutions for a wide range of A-Players, including NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI, and more. You can view his LinkedIn profile here.
Related Items:
In Search of Data Model Repeatability
Why a Universal Semantic Layer is the Key to Unlock Value from Your Data
The Polyglot Problem: Solving the Paradox of the ‘Right’ Database
Leading Solution Providers
















