


June 30, 2023
Databricks Strings a Data Mesh with Lakehouse Federation

(Oleksii Lishchyshyn/Shutterstock)
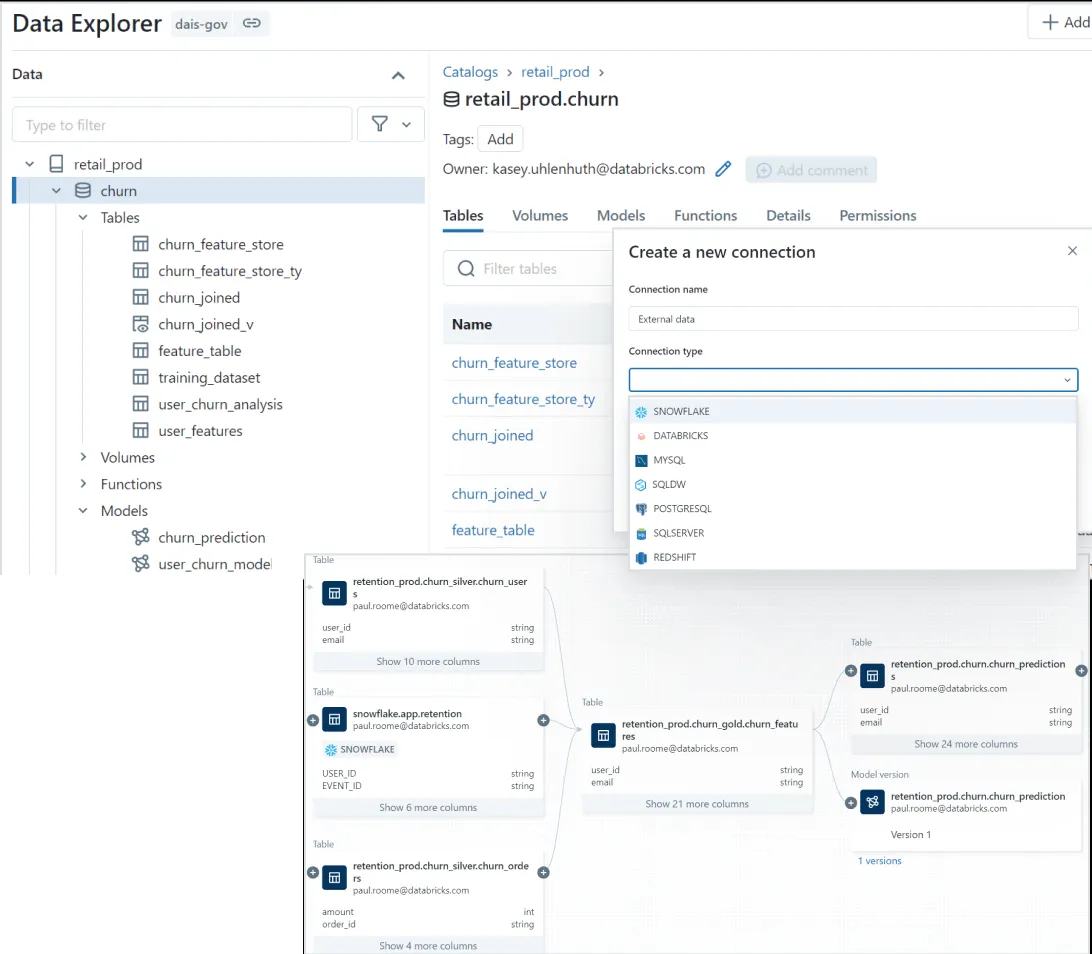
Databricks this week unveiled Lakehouse Federation, a set of new capabilities in its Unity Catalog that will enable its Delta Lake customers to access, govern, and process data residing outside of its lakehouse. The company says Lakehouse Federation will pave the path towards a data mesh architecture for customers.
Databricks says the addition of Lakehouse Federation capabilities to its Unity Catalog will give customers the capability to centralize data management and governance functions across all of their data platforms. They’ll be able to manage and govern data centrally from the Unity Catalog tool, which is free, without requiring the users to move or copy any data, the company says.
Unity Catalog will not only allow users to set and (eventually) enforce data access policies on tables, rows, and columns of data residing in Snowflake, AWS’ Amazon Redshift, Microsoft’s Azure SQL Database and Azure Synapse, Google Cloud’s BigQuery, MySQL, and PostgreSQL, but they’ll be able to execute data analytic and machine learning workloads that combine data from these databases and data warehouses, the company says.
“Within Databricks, you can connect data sources that can be any of these other systems, and inside the Databricks UI , they just appear as catalogs, and you can use all the features for setting permission, getting audit logs and so on,” Matei Zaharia, the Databricks CTO and co-founder, said during his keynote address at the Databricks Data + AI Summit Wednesday.

Databricks co-founder and CTO Matei Zaharia speaking at the Data + AI Summit June 28, 2023
“We’ve also spent a lot of work optimizing the way the engine works with these kinds of queries across data sources,” he continued. “So we can parallelize work. We can push queries effectively into each data source. We can cache results so that your users get excellent performance across all these data sources. So when you get a query like this that combines say Postgres and Delta Lake data, it can push the right kind of filtering into Postgres and make it happen quickly.”
A few weeks ago, Databricks announced that Unity Catalog would gain support for the Apache Hive API, which will open the data catalog up to any product that supports the Hive catalog. While use of Apache Hive as a SQL query engine has waned thanks to the availability of newer and faster engines, like Presto, Trino, and Spark SQL, many big data customers still use Hive to help manage their data.
The first of the Lakehouse Federation capabilites, including visibility into third-party data sources and query push-down, will soon be in preview. The Hive API compatibility will also soon be in preview. Another feature the company is working on is the capability to push data governance policies from Unity Catalog into third-party data sources; the company did not provide a timetable for that feature.
Databricks Unity Catalog gets hooks into third-party data sources with Lakehouse Federation
Databricks is delivering Lakehouse Federation in response to demands from customers for a smoother big data experience. The rapid organic growth of data silos within organizations has complicated those organizations’ efforts to manage and process big data. With so much data spread across so many databases, data warehouses, object stores, and distributed file systems, the acts of managing and governing data becomes rife with cost and complexity.
The data mesh architecture is one possible solution to this data silo problem. First conceived by Zhamak Dehghani in 2019, a data mesh enables distributed groups of teams to access and work with data within the confines of a domain-driven architecture, a self-service platform, and data product thinking.
The data mesh idea has caught on, and Databricks is now one of its newest adherents. The company is positioning Unity Catalog, with its new Lakehouse Federation capabilites (not to mention the Hive API compatibility), as a key technology enabling customers to embrace data mesh concepts and to actually build a data mesh of their own.
“[Lakehouse Federation] is a very powerful capability because it means everything you do in Databricks–data science, analytics, machine learning, generative AI, all that stuff–you can easily do it across all your data,” Zaharia said. “And it’s a very powerful enabler if you want to set up a data mesh architecture with distributed ownership, or if you just want to make the ingest process, the process of working with the latest data, easier.”
Databricks officially unveiled Unity Catalog at the Data + AI Summit in 2021 and announced that it was generally available one year ago today at the Data + AI Summit in 2022. This week’s announcements help to bolster a product that Databricks CEO Ali Ghodsi called his company’s “most strategic bet.”
“It’s free. We don’t even charge when people use Unity Catalog. Why?” Ghodsi said during a press conference at DAIS on Tuesday. “Because it’s extremely strategic to succeeding in having a data platform. It’s where you do all the governance. So this is where you set up all your privacy policies, all your attributes-based access control, where you say who can access what, who can not access what.”
The new features that Databricks unveiled this week in Unity Catalog, along with its recent acquisition of Okera and its investment in Immuta, shows that the company is pivoting strongly towards data governance.![]()
In addition to data governance, the company is moving toward enabling AI governance. To that end, Databricks also announced that it’s launching into a preview a product called Governance for AI.
According to Zaharia, Governance for AI will help automate the task of managing the variety of entities that data scientists work with while developing AI, including unstructured data files, models, features, and functions. “Today they’re often managed in completely different software platforms,” he said. “With Governance for AI and Unity Catalog, you get all these objects inside your catalog.”
To sign up for the waitlist for Lakehouse Federation, click here.
Related Items:
Databricks Puts Unified Data Format on the Table with Delta Lake 3.0
Databricks Unleashes New Tools for Gen AI in the Lakehouse
Databricks Enhances Lakehouse Governance with Okera Acquisition and Immuta Investment
Applications:
Data Management
Vendors:
Databricks
Leading Solution Providers
















