


May 18, 2023
Beyond the Moat: Powerful Open-Source AI Models Just There for the Taking

(AI generated/Shutterstock)
ChatGPT and GPT-4 models get all the headlines these days. But if you look around, you’ll find capable open source models you can run yourself, for free, with no restrictions, with excellent performance. A Google researcher admitted as much in the “We Have No Moat” memo leaked earlier this month, but the computing public doesn’t seem aware of the plethora of new and exciting AI models being released every day, experts say.
The launch of ChatGPT on November 30, 2022 will likely go down in history as a defining moment in the democratization of AI. You would have to go back to Steve Jobs’ introduction of the Apple iPhone on June 29, 2007, to find a comparable moment. OpenAI CEO Sam Altman’s testimony in the US Senate this week demonstrates not only the awesome potential of AI technology, but the fear of what comes next.
The buzz around ChatGPT is spurring the machine learning and AI community to action, too, as technologists search for ways to augment every cognitive task with AI capabilities. From data analytics data management to ERP and app dev, every application is getting an AI-based copilot to elevate human ability.
Luis Ceze, a computer science professor at the University of Washington and CEO of OctoML, is as amazed at the progress as the rest of us. The machine learning expert credits OpenAI with kickstarting the current AI craze.
“It’s just absolutely astounding what’s going on right now,” he says. “I feel like ChatGPT has been a wonderful thing all around, not only as a fantastic demonstration of technology, but also bringing attention to this capability…Now you don’t have to explain to people what all these models can do.”

(Ebru-Omer/Shutterstock)
Large language models (LLMs) have been on the radar for a while, and OpenAI deserves credit for opening doors for new AI use cases. But prospective users should be careful not to get too caught up in thinking OpenAI is the only game in town when it comes to AI. In fact, there are many other alternatives to GPT-4 and ChatGPT that will likely be a better fit for AI builders than APIs to OpenAI, he says.
“We’re seeing a lot of customers and users get started using OpenAI and then they realize ‘Oh, what I really need is just this,’” he tells Datanami. “They [OpenAI] build amazing models and those models have taken a lot of investment to get to where they are. But for the use cases that people often care about, you don’t need that level of functionality.”
In some instances, such as summarize text, using ChatGPT is akin to “taking a Ferrari to go pick up coffee,” Ceze says. “There’s a lot of free cars to use.”
Among the “free cars” OctoML is helping users to take for a ride are RedPajama, LMSYS.org‘s Vicuna, and Dolly, offered by Databricks. On the image front, Stable Diffusion and Dall-E 2 come to Ceze’s mind. Meta’s LLaMa model was leaked online and people are building upon it. Stanford’s Alpaca is based on LLaMa. Hugging Face provides access to more than 13,000 models. There are many more that already exist, with more coming every day, the professor says.
“The pace of progress is wild,” Ceze says. “I’m talking about major, major improvements that are happening. I’m not exaggerating that it’s often on a daily basis that there’s a new amazing model that’s just popping up. I don’t think people realize that.”
In addition to being free, the open source models have other advantages. For starters, users can run them on their own infrastructure, which gives them more control. If they have the data science skills, they can tweak the weights and tune the algorithm, and even train the model to run on their own data. There’s also the matter of added risk of running a model trained on unknown data, which is something OpenAI has been criticized for doing.
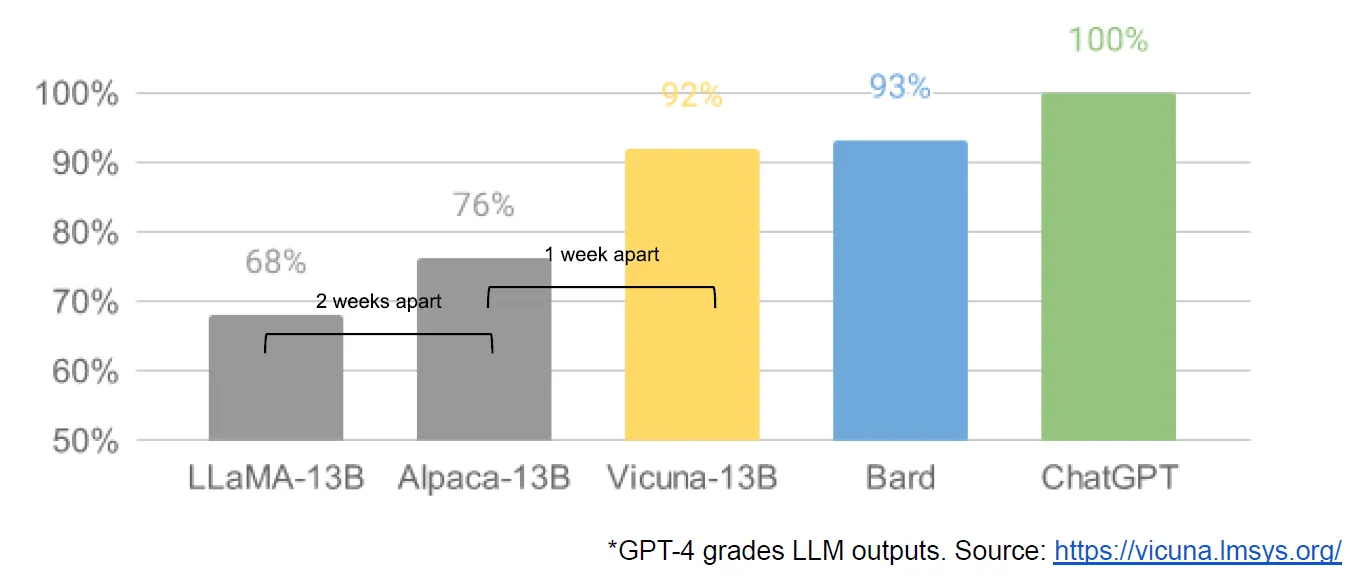
The pace of innovation with LLMs is accelerating (Image source: LMSYS.org)
A Google researcher bolstered Ceze’s point of view two weeks ago when the internal “We Have No Moat and neither does OpenAI” memo was leaked on a Discord server. The folks at SemiAnaysis confirmed the memo was real and then published a moderately redacted version of it.
According to SemiAnalysis, The Google researcher wrote:
“While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. This has profound implications for us.”
There’s no “secret sauce” to what Google does with Bard and other models, the researcher writes. Improvement happens through community collaboration, not mixing digital potions in the Google lab. And as smaller language models start to do what previously could only be done with large language models, the gap will narrow until there is no advantage left.
We’ve seen a “tremendous outpouring” of innovation since LLaMa was leaked online in March, the research writes. It took the community about a month to start building upon the foundation model with variants that took instruction tuning, quantization, quality improvements, human evaluations, multimodality, and RLHF [reinforcement learning human feedback] to new levels.
“Most importantly,” the researcher writes, “they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.”

RedPajama is a variant of Meta’s LLaMa foundational model
In other words, a permanent bridge has come down across the moat–if there was ever a moat to begin with.
“People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality,” the Google researcher writes. “We should consider where our value add really is.”
This, of course, is great news for everybody–from hobbyists who want to tinker to researchers that want to experiment to Fortune 100 corporations that want to incorporate AI into their business processes.
One of the most compelling technological advancements in recent history is now freely available to anybody with a laptop, an Internet connection, and the curiosity to look around. The barrier of entry to using the technology has already been greatly reduced, and further reductions are almost guaranteed, relegating PhDs to search for even bigger innovations while allowing the rest of us to create new applications and reinvent businesses with what is already available.
“People have put a lot of attention on the closed big models like OpenAI and Cohere and so on and I don’t think there’s enough awareness that the open source models are incredibly capable,” Ceze says. “It’s something that I don’t think people are paying enough attention to.”
Related Items:
AI Chatbots: A Hedge Against Inflation?
LLMs Are the Dinosaur-Killing Meteor for Old BI, ThoughtSpot CEO Says
ChatGPT Dominates as Top In-Demand Workplace Skill: Udemy Report
Applications:
Artificial Intelligence
Technologies:
Frameworks
Sectors:
Academia
Tags:
AI, ChatGPT, DALL-E, Dolly, foundation models, LLaMA, Luis Ceze, moat, open source, RedPajama, Stable Diffusion, Vicuna
Leading Solution Providers
















