

May 16, 2023
HPE Brings Analytics Together on its Data Fabric

HPE today unveiled a major update to its Ezmeral software platform, which previously included over a dozen components but now includes just two, including the Ezmeral Data Fabric that provides edge-to-cloud data management from a single pane of glass, as well as Unified Analytics, a new offering that it says will streamline customer access to top open source analytics and ML frameworks without vendor lock-in.
HPE Ezmeral Data Fabric is the flexible data fabric offering that it acquired from MapR back in 2019. It supports an S3-compaible object store, a Kafka-compatible streams offering, and a Posix-compatible file storage layer, all within a single global namespace (with vectors and graph storage in the works). Support for Apache Iceberg and Databricks Delta table formats help to keep data consistent.
HPE updated its data fabric with a new SaaS delivery option, a new user interface, and more precise controls and automated policy management. But arguably a bigger innovation lies with Ezmeral Unified Analytics, which brings out-of-the-box deployment capabilities for a slew of open source frameworks, including Apache Airflow, Apache Spark, Apache Superset, Feast, Kubeflow, MLFlow, Presto SQL and Ray.
Customers can deploy these frameworks atop their data without worrying about security hardening, data integration issues, being stuck on forked projects, or vendor lock-in, says Mohan Rajagopalan, vice president and general manager of HPE Ezmeral Software.
“Our customers get access to the latest, greatest open source without any vendor lock-in,” says Rajagopalan, who joined HPE about a year ago. “They get all the enterprise grade guardrails that HPE can offer in terms of support and services, but no vendor lock-in.”
The open source community moves quickly, with frequent updates that add new features and functionality, Rajagopalan says. However, open source users don’t necessarily work with fervor to ensure their implementations deliver enterprise-grade security and compliance, he says. HPE will take up the mantle to ensure that work gets done on behalf of its customers.
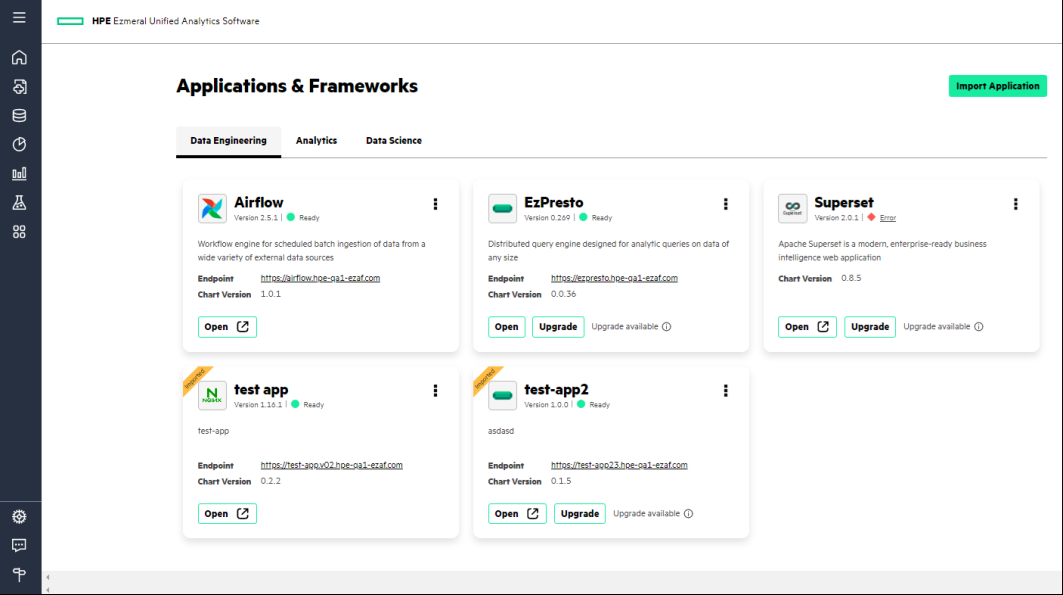
HPE Ezmeral Unified Analytics gives users access to top open source analytic and ML frameworks (Image source: HPE)
“Patches, security updates, etc. are all offered to our customers. They don’t have to worry about it. They can simply use the tools. We keep the tools evergreen,” he says. “We make sure that all the tools can comply with the enterprise or the company’s security postures. So think about OIDC, single sign-on, etcetera. We take care of all the plumbing.”
More importantly, he says, HPE will ensure that the tools all play nicely together. Take Kubeflow and MLFlow, for example.
“Kubeflow I think is the best-of-breed MLOps capability I’ve seen in the market today,” Rajagopalan says. “MLFlow I think has the best model management capabilities. However, getting Kubeflow and MLFlow to work together is nothing short of pulling teeth.”
HPE has committed to ensuring this compatibility without introducing any major code changes to the open source tools or forking the projects. That is important for HPE customers, Rajagopalan says, because they want to be able to move their implementations easily, including running them on any cloud, the edge, and on-prem.
“We don’t want to force our customers to choose the entire stack,” the software GM says. “We want to meet them where they’re comfortable and where their pain points are as well.”
Asked if this is a re-run of the enterprise Hadoop model–where distributors like Cloudera, Hortonworks, and MapR sought to build and keep in synch large collections of open source projects (Hive, HDFS, HBase, etc.)–Rajagopalan said it was not. “I think this is learning, stepping on the shoulders of giants,” he says. “However, I think that approach was flawed.”
There are important technical differences. For starters, HPE is embracing the separation of compute and storage, which eventually became a major sticking point in the Hadoop game and which ultimately led to the demise of HDFS and YARN in favor of S3 object storage and Kubernetes. HPE’s Ezmeral Data Fabric and Unified Analytics still supports HDFS (it’s being deprioritized), but today’s target is S3 (and Kafka and Posix file systems) storage coupled with containers controlled by Kubernetes.
“Everything that is there in Unified Analytics is a Kubernatized app of Spark or Kubeflow or MLFlow ![]() or whatever framework we included there,” Rajagopalan says. “The blast radius for each app is just its own container. However, behind the scenes, we’ve also created a bunch of plumbing such that the apps can in some sense communicate with one another, at the same time we also made it easy for us to replace or upgrade apps in place without disrupting any of the other apps.”
or whatever framework we included there,” Rajagopalan says. “The blast radius for each app is just its own container. However, behind the scenes, we’ve also created a bunch of plumbing such that the apps can in some sense communicate with one another, at the same time we also made it easy for us to replace or upgrade apps in place without disrupting any of the other apps.”
However, just rubbing some Kubernetes on a bucket of open source bits doesn’t make it enterprise-grade. Companies must pay to get Unified Analytics, and they’re paying for HPE’s expertise in ensuring that these applications can cohabitate without causing a ruckus.
“I don’t think Kubernetes is the secret sauce for keeping everything in synch,” Rajagopalan says. “I don’t think there is any magic box. I think we have a lot of experience in managing these tools. That’s what is the magic sauce.”
Support for Apache Iceberg and Databricks’ Delta Lake formats will also be instrumental in helping HPE to do what the Hadoop community ultimately failed at–maintaining a distribution of a large number of constantly evolving open source frameworks without causing lock-in.
“It’s huge,” Rajagopalan said of the presence of Iceberg in Unified Analytics. Iceberg has been adopted by Snowflake and other cloud data warehouse vendors, like Databricks, that HPE is providing data connectors to. Snowflake is popular among HPE customers who want to do BI and reporting, while Databricks’ and its Delta Lake format is popular among customers doing AI and ML work, he says.
“What we try to do is we try to provide the right sets of abstractions and here we’re leaning on open standards. We don’t want to create our own bespoke abstractions,” Rajagopalan says. “Right now, I would like for HP to be Switzerland, which is we try to provide the best of options to our customers. As the market matures, we may take a more opinionated stance. But I think there’s enough momentum in each of these spaces where it’s hard for us to pick one over the other.”
Related Items:
HPE Adds Lakehouse to GreenLake, Targets Databricks
HPE Unveils ‘Ezmeral’ Platform for Next-Gen Apps
Data Mesh Vs. Data Fabric: Understanding the Differences
Tags:
containers, data fabric, Kafka, Kubeflow, Kubernetes, magic box, magic sauce, MLflow, open source, presto, Ray, secret sauce, Spark
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States