


May 5, 2023
Galileo Charts Data Quality Course-Correction for AI Teams

(delcarmat/Shutterstock)
For several months, the Silicon Valley startup Galileo has been selling an AI-powered product designed to help correct data quality issues for natural language processing (NLP) models and applications. Today the company announced that it’s expanding that core product out to help data science teams correct data problems impacting computer vision (CV) models and applications too.
Galileo was founded two years ago by former senior product managers from Google and Uber. Despite their reputation for developing cutting-edge technology and tools, even tech companies as storied as Google and Uber suffer from the plague of poor data quality.
“The big 100,000-pound gorilla for us was the quality of the data that we were working with,” says Galileo co-founder and CEO Vikram Chatterji, who oversaw a team of product managers and data scientists at Google AI. “It was really hard for my data scientists to figure out what’s the data that was pulling the model performance down as they were going through the iteration cycles on the training side.”
One might be tempted to think that workers at Google AI had amazing tools at their disposal that could magically identify data problems, fix them, and prepare the data for the world-class machine learning algorithms they built for the Google team as well as enterprise clients.
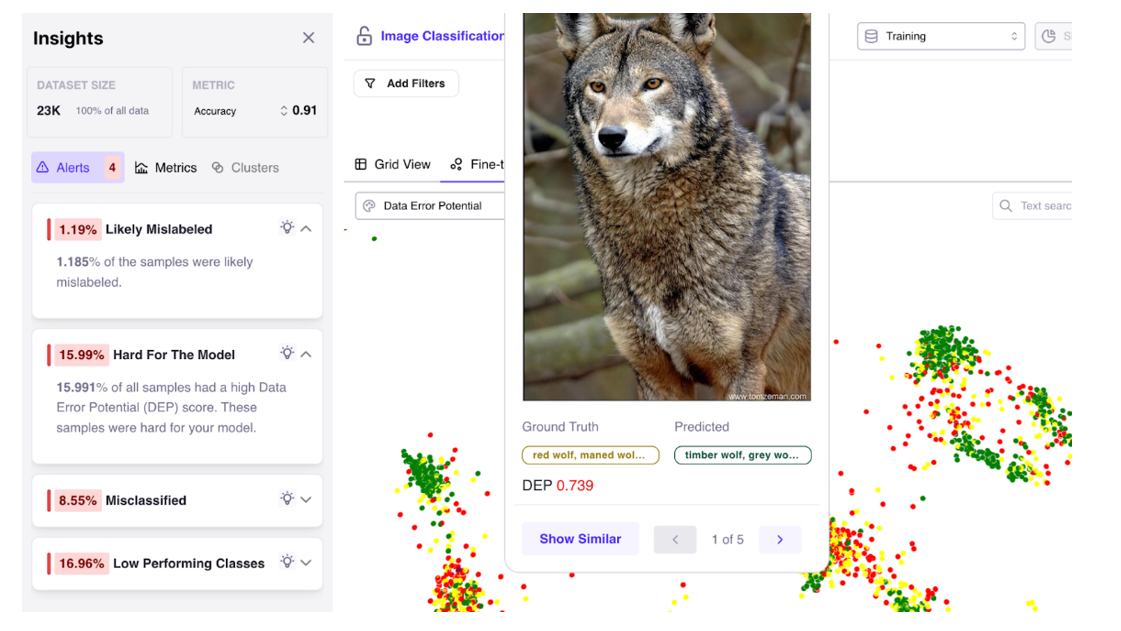
Galileo Data Intelligence for Computer Vision helps customers increase data quality of image data
However, one would be wrong. According to Chatterji, the Google AI team used Python scripts and Excel spreadsheets to diagnose the data problems in NLP and computer vision scenarios, just like everybody else. “It was taking literally 80% of our time at Google,” he tells Datanami. Just like everybody else.
Things were just as bad at Uber, where Galileo co-founder and CTO Atindriyo Sanyal was an engineering leader for Michelangelo. “He was seeing the same data quality problem,” Chatterji says.
Nothing was any better over in the Google Speech Synthesizer project, where Galileo co-founder Yash Sheth toiled wrangling audio files. “It’s even worse because you can’t even see speech,” Chatterji says. “They had hundreds of people literally trying to figure out what data, what it’s performing poorly on…then try to fix it.”
Without a proper solution for these particular problems, the trio of technologists did what many other inventors have done in history of IT and technology in general: They decided to build their own solution.
After a year spent talking to hundreds of machine learning teams and product development, Galileo rolled out its first solution a year ago. On May 3, 2022, the company launched ML Data Intelligence for Unstructured Data, which is based on its own proprietary AI technology.
The software was designed to help customers automatically identify problems with the text data they’re with their NLP models, from the data selection stage all the way to the post-production phase. The product has been a hit, with dozens of paying customers and many more dozens in the testing phase, Chatterji says.
Along the way, customers started clamoring for a data quality solution for their image data, too. The company responded by tweaking the core algorithm at the heart of its ML Data Intelligence and rolling out a new solution dubbed Galileo Data Intelligence for Computer Vision. The San Francisco company made that announcement today.
According to Galileo, the product’s AI models can automatically identify problematic image data that’s negatively impacting model performance. Then it can suggest actions the data science team can take to rectify the problem.
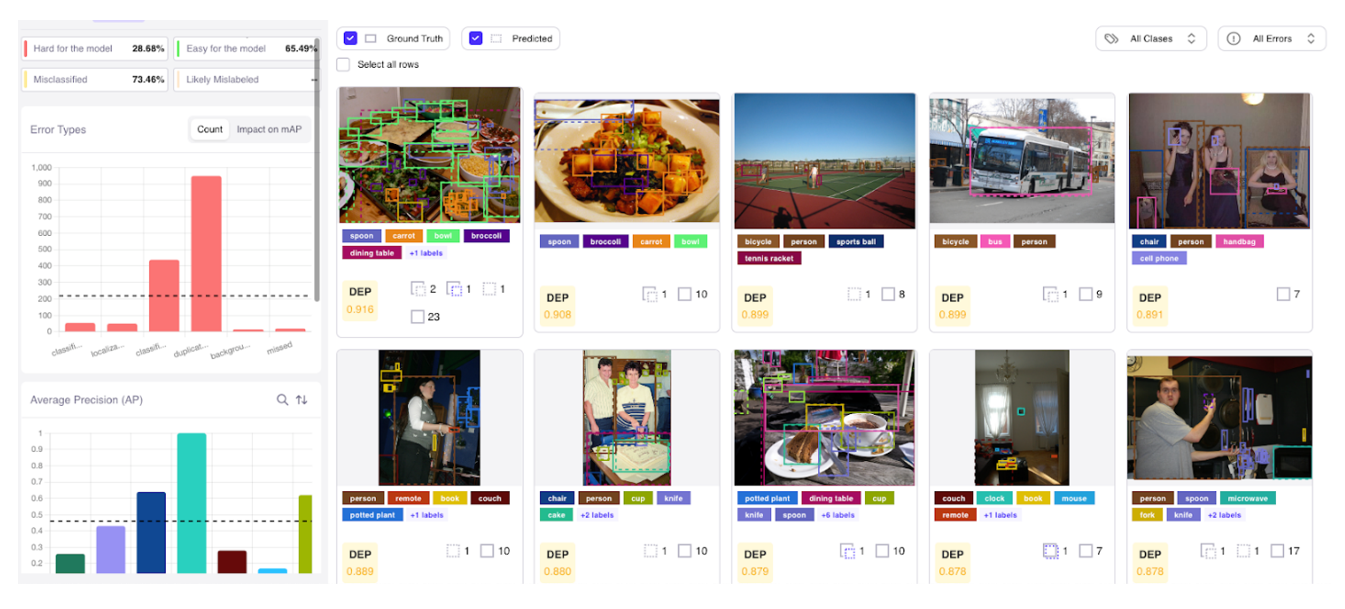
Data labeling is one area of the computer vision workflow that can improve with its solution, Galileo says
One of the ways primary ways that Galileo helps is by optimizing the data labeling process. Data labeling is a necessary process for most forms of AI, but it’s especially crucial for CV. However, it’s very expensive and time-consuming, which means there is lots of room for improvement. By automatically picking the right image data to send to the labelers, Galileo can reduce labeling costs by 30% to 40%, Chatterji says.
Galileo has the capability to automatically spot bad image data. If a customer is building a model to train self-driving cars, for example, the customer would want the best quality image data, free of snow, dim-driving conditions, or fog (although in some edge cases, those are exactly the images one would need to build a solid model). In either case, Galileo provides the intelligence to automatically identify whether the images will work or not.
“We have some proprietary algorithms,” Chatterji says. “One of them is called the Data Error Potential score, which automatically surfaces these images and says, this has a very high error potential. Then the practitioner can go in and say, oh, this is because it’s mislabeled. It’s a picture of a snowy road, but it’s actually labeled as a sunny day.”
In this case, Galileo can serve as a net to catch images that human labelers get wrong. It can also be used to identify the types of images that are in short supply and which the team will need more of to ensure the model is solid and not overfitting, Chatterji says.
“These are the things that they can’t figure out by themselves and they’re kind of just finding the needle in the haystack, so we automate that process,” he says. “The labels are incorrect. They don’t have enough of that data. The model is overfitting on some data. That’s the heavier, more difficult stuff to do. We also do the simpler stuff, like this data is blurry, this data is dark, this one is rotated the wrong way.”
Once the model has been trained and put into production, one might think things would get easier from a data quality perspective. That would be an erroneous assumption, according to Chatterji.
“Once the model is in production, many things can go wrong,” he says. “We automatically detect if the model’s performance has gone down and tell them what data it went down on, so that they can retrain the model on that. It’s just a cyclical thing. So we’re an end-to-end platform for data quality.”
Galileo’s solutions fit right into the typical software stack the data science teams work with, including Jupyter, Amazon SageMaker, Google Vertex AI, or Databricks for AI. Integration requires the addition of just a few lines of Python at the data science notebook level. It can also work with labelign tools like Scale AI and LabelBox, Chatterji says.
“We are completely agnostic of the platform that they use, and we in fact are partnering with some of them and integrating with a lot of them, because they don’t have this capability right now and they want it,” he says. “You find the issues in Galileo, and either you send that back for adding more data of that sort, or you send it to the labeling team so that they can very specifically work on 100 data points versus 1,000 data points, which is very expensive.”
Galileo Data Intelligence for Computer Vision is available now. The company is hosting a webinar on the new product May 9 2 p.m. ET. You can register here.
Related Items:
Data Quality Is Getting Worse, Monte Carlo Says
Achieving Data Quality at Scale Requires Data Observability
Leading Solution Providers
















