

May 1, 2023
We’re Still in the ‘Wild West’ When it Comes to Data Governance, StreamSets Says

The passage of data privacy laws like GDPR and CCPA was supposed to rein in the excesses of the big data boom days and usher us toward a new era of data civility. It hasn’t quite worked out that way, according to data integration provider StreamSets, which says we’re still living in the “Wild West” when it comes to data governance.
While GDPR and CCPA (since replaced by the CPRA) have stopped some of the most flagrant violations of data privacy and security in the European Union and California, respectively, the laws (and others like them in other countries) haven’t coincided with a widespread ascent into a more rational phase of data governance among the tens of thousands of companies around the world that are collecting, storing, and processing data.
New laws notwithstanding, a multitude of factors are contributing to the difficulty in building solid data governance cultures and practices, according to a StreamSets report, titled “Creating Order from Chaos: Governance in the Data Wild West.”
StreamSets, which was acquired by Software AG just over a year ago, surveyed about 650 data decision-makers and practitioners from large enterprises in the US, UK, Germany, France, Spain, Italy, and, Australia to gather data about what’s going on with data governance in the field. The results pointed the data governance finger at some of the usual culprits, but also illuminated new barriers to success.
For example, 54% of the survey respondents say a decentralized data environment that spans on-premises and multiple cloud environments has contributed to a “data wild west.” A smidge more (57%) say this fragmentation in the data supply chain “has made it harder to understand, govern, and manage data in their organization.”
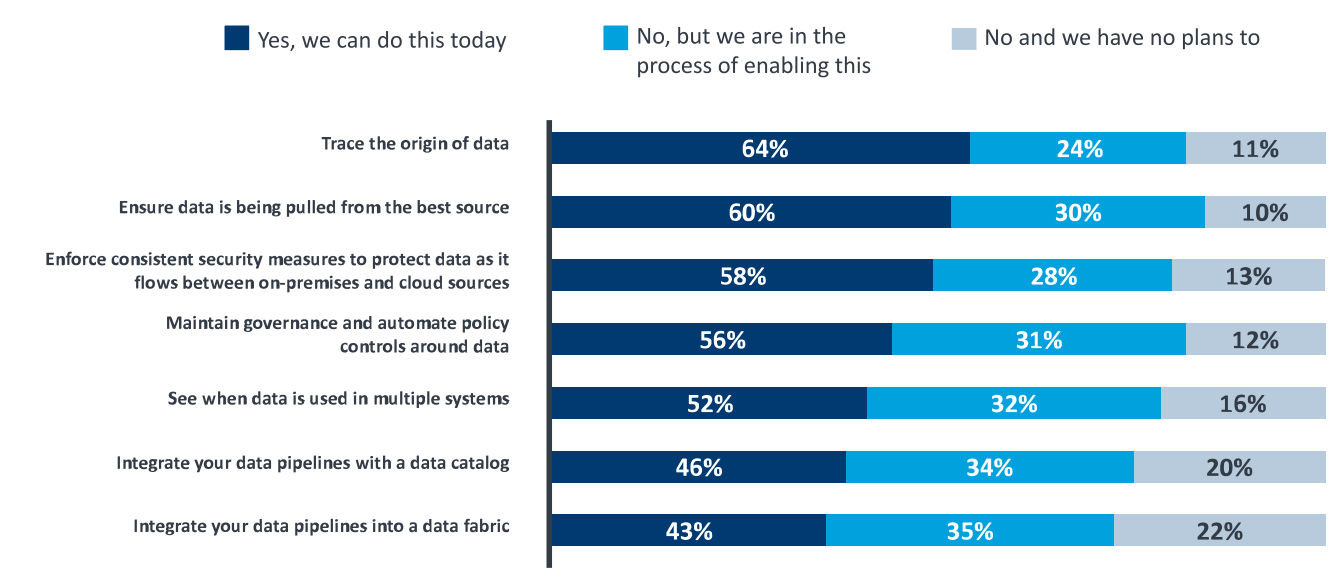
Data-leaders report difficulty in accomplishing many data governance tasks (Graphic source: StreamSets report “Creating Order from Chaos: Governance in the Data Wild West”)
StreamSets identified a gap between the types of data governance capabilities companies claim to have, and the actual functions they have implemented in their systems. For example, the survey says 71% of respondents say “they are confident they have complete visibility ad control over their data.”
However, the survey found that “44% of organizations cannot maintain governance and automate policy controls around data, and 42% cannot enforce consistent security measures–a clear vulnerability,” StreamSets says in its report.
A lack of visibility into data pipelines raises the risk of other data security problems, the company says. “The research reveals that 48% of businesses can’t see when data is being used in multiple systems, and 40% cannot ensure data is being pulled from the best source,” it says. “Moreover, 54% cannot integrate pipelines with a data catalog, and 57% cannot integrate pipelines into a data fabric.”
Who holds responsibility for cleaning up the data mess? Well, that’s another area with a bit of murkiness. About half (47%) of StreamSets survey respondents say the centralized IT team bears responsibility for managing the data. However, 18% said the line of business holds primary responsibility, while it’s split between the business and IT in 35% of cases.
A second survey released by StreamSets last week highlights the difficulty in running data pipelines in the modern enterprise. Many companies have thousands of data pipelines in use and are hard pressed to build, manage, and maintain them at the pace required by the business, according to StreamSets.
“The demand for data is higher than the ability of most technical teams to provide it,” StreamSets says in “Lifting the Lid on the Hidden Data Integration Problem,” which is based on the same survey mentioned above. “More than half (59%) of respondents say the acceleration of digital transformation priorities has created major data supply chain challenge.”
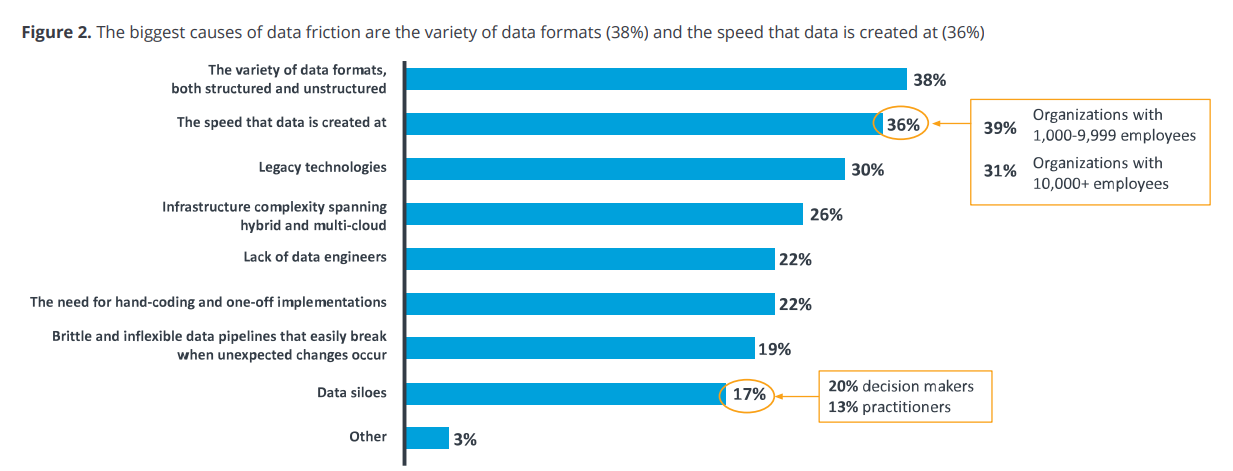
The leading causes of data friction (Graphic source: StreamSets report “Lifting the Lid on the Hidden Data Integration Problem”)
Despite advances made in ETL/ELT, data transformation, and data pipeline building, the rapid expansion of data silos with inconsistent formats means that the expertise of a trained data engineer is typically required to build one-off (bespoke) data pipelines. These data engineers simply cannot keep up with the demand.
It’s no surprise, then, that 68% of data leaders say data friction is “preventing them from delivering data at the speed the business requests it,” or that 65% said that “data complexity and friction can have a crippling impact on digital transformation.”
While laws have been erected that prevent consumers from suffering from some of the most egregious abuses of data privacy and security, the fact remains that data is still poorly governed inside many enterprises. The factors that spurred the big data phenomenon 15 years ago–exploding data volumes, rising data velocity, and questionable veracity–have only grown in magnitude since then.
Data management tools have gotten marginally better over the years. Architectures such as data mesh and data fabrics help, and incremental enhancements in data catalogs, ETL/ELT, data transformation, and data observability have helped us keep pace with the change in many cases. But it’s clear there’s quite a bit of work to do, and we’re a ways off from achieving the Holy Grail of big data.
Related Items:
Software AG to Acquire StreamSets
The Enlightening Side of GDPR Compliance
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States