

April 10, 2023
Data Products: The Solution to the Data Silo Trap

Data can be somewhat of a double-edged sword for modern enterprises. On one hand, it is critical to the decision-making process. Typically speaking, the quality of decisions improves as the amount of pertinent data analyzed increases. Simply put, the more data there is, the more angles there are for a question to be explored, which ultimately means more experience that can be included into a decision-making process, resulting in higher quality decisions.
Even beyond decision-making, data is critical to the functioning of modern enterprises. Retail enterprises need to keep customer contact information such as addresses, and credit card details on file in order to avoid making the customer re-enter this information every time they interact with the enterprise. Banking enterprises need to be able to tell their customers where their money is at any period of time. Gaming enterprises need to store game state. Human resources need basic information about all employees in order to be able to function properly. These datasets are fundamental to the basic operations of these enterprises.
On the other hand, data can cause huge headaches for enterprises. Data breaches can lead to precipitous drops in confidence in a particular company and large financial losses. Data espionage by competitors can significantly disadvantage an enterprise’s competitive viability. Critical data can get lost or corrupted. Poor data governance can lead to false, inaccurate, or outdated data being presented to people without proper notice. Indeed, it can cause the exact opposite of what was said above — instead of data leading to improved decision making, it can lead to significantly poorer decision making.

(Arcady/Shutterstock)
There are very few other factors that can have a similar type of enormous swing effect in overall enterprise success.
Data Dangers Lead to Centralized Data Management
Given the sheer magnitude of this swing – proper data management can cause so much good but while poor data management can cause so much bad – the best practice for decades was to maintain central control over all enterprise data. The presumption was that a centralized team of highly-paid data management experts are most capable of putting together data governance rules, implementing, enforcing, and abiding by those rules, as well as preventing the dangers presented by the double-edged sword from inflicting too much damage.
The basic thesis of centralized data management is that there is a central repository of enterprise data that can only be accessed via secure and well-governed standards that help limit potential exposures to breaches and espionage. Having all the data in one place greatly simplifies the enforcement of security and privacy rules and enables tracking, control, and reporting of data usage. Furthermore, processes are put in place to ensure that all data inserted into this repository is high quality — meaning it is correct, complete, up-to-date, well-documented, and well-integrated with other enterprise data-sets. It is often possible to make various guarantees related to data integrity and other data access service levels. Having all data stored in the same repository also makes data cataloging and enterprise-wide search much easier to implement.
Indeed, the centralized data management approach does a reasonable job of blunting the dangerous side of the data sword. The problem is that it also blunts the other side of the sword, limiting the overall effectiveness of data utilization within an enterprise.
For example, a new dataset may come along that is enormously valuable to making a particular decision. When data is not centrally managed that dataset can be incorporated instantly into the decision-making process. However, when data is centrally managed, a delay is incurred as the centralized team gains access to the new dataset and brings it into the centralized repository while upholding all the quality and data integration standards. It is not unusual for this process to take several months. By the time the data is finally available from the central repository, its value may have already decreased due to this time delay. Thus, in many cases, centralized data management can reduce organizational agility.

(maglyvi/Shutterstock)
Furthermore, having a human team in charge of ingress into the centralized data repository fundamentally limits the scalability of an organization. The amount of datasets available to an organization is rapidly increasing. Doing proper cleaning, integration and quality management on each dataset is a time consuming process and requires at least some domain expertise in the domain of the dataset. Handing off responsibility for this processing to a single human team creates a giant bottleneck in organizational data pipelines. This human team limits the ability of the organization to expand into new domains, and even to expand within existing domains.
Let the Stuff We Need Now Live Outside
Since so much time and effort needs to be spent to get data into a fully governed and integrated format within the central repository, there exists a large temptation to avoid the process altogether. For example, it is possible to cut corners by dumping datasets into data lakes without initially going through a quality control process. Alternatively, data can sit inside data silos outside of (or even inside) any kind of central repository. Such approaches help to overcome the agility and scalability challenges of centralized control, but introduce other challenges. Data silos are often created via an ad-hoc process: an individual or team takes some source data, enhances it in various ways, and dumps the result in a silo repository or data lake for themselves and/or others to use. These data silos often have significant value in the short term, but rapidly lose value as time goes on. In some cases, data silos not only lose value over time, but actually become harmful to access due to outdated or incorrect data resulting from lack of maintenance, and failure to keep up with data privacy and sovereignty standards. In many cases, they never used approved data governance practices in the first place and present security vulnerabilities for the enterprise.
Furthermore, the value of a data silo is typically limited to the creators of the dataset, while the rest of the organization remains unaware of its existence unless they are explicitly notified and directly tutored in its syntax and semantics. Silos only become harder to find over time as institutional memory weakens with employee turnover and movement across units. Due to lack of maintenance, they also become harder to integrate with other enterprise data over time. Much effort is wasted in the initial creation of these data silos, yet their impact is limited in both breadth and time. In some cases, the opposite is true: data silos have too much impact, where other units build dependencies on top of these silos that are deployed with unapproved data governance standards, and all the harmful side-effects of improperly governed data spreads across the enterprise.
Going back to the “double-sword” analogy: while the centralized data management approach dulls both ends of the sword, the data silo approach sharpens the wrong side of the sword: it maintains most of the dangers inherent in data management, while providing (at best) only limited short term benefits in terms of improving organizational decision-making.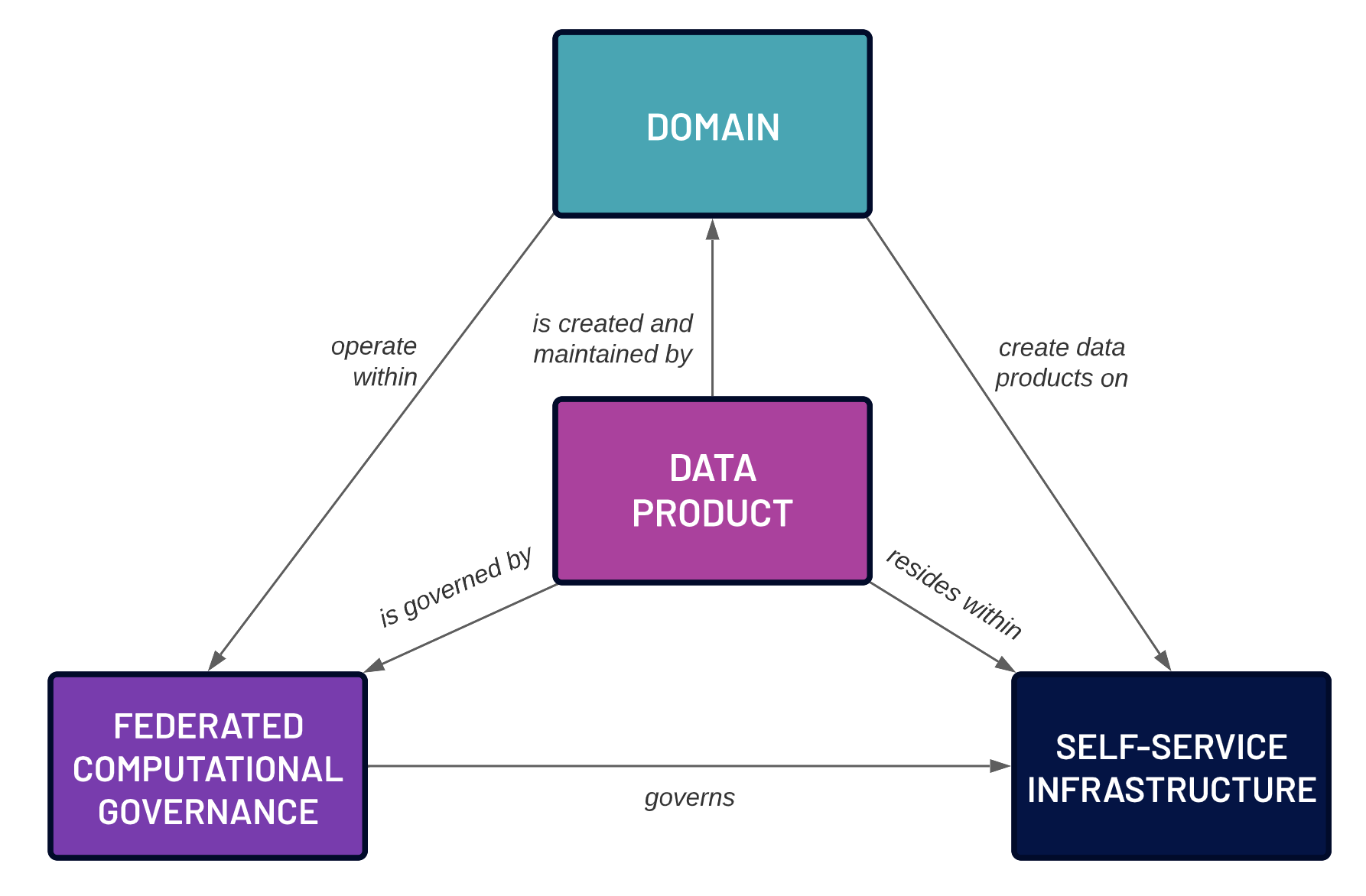
A New Approach
Ultimately, what we want is all the advantages of centralized data management, without the drawbacks around agility and scalability. In other words, we want to scale all the activities of the centralized team, and everything that they do around data governance and integration, in a decentralized fashion by distributing their activities to domain owners without sacrificing the governance and data quality you get with a centralized team. A promising way to meet this goal is the “Data Products” approach: an idea that has recently been gaining traction, especially within the context of data marketplaces, the “Data Mesh”, and other emerging organizational data management best practices.
Data Products, as a strategy, require a radical shift in mentality during the process of making data available within an organization. Previously, making data available to other units was a low-effort process, involving one of two possible approaches. The first approach is to simply hand a dataset over in its entirety to the other units. The dataset then becomes a silo in the possession of those other units, leading to duplicated effort as each unit may perform similar data cleaning and integration processes. Thus the short term benefit of low-effort sharing leads to long-term problems in terms of wasted physical and human resources resulting from data duplication and related processes. [These disadvantages are on top of the other disadvantages of data silos discussed above.] The second approach involves handing off the dataset to the centralized team, which is then burdened with the work of doing all the upfront effort in making the dataset usable so that other units can use the dataset with less duplicated effort. Either way, the team that owns the dataset — and that probably understands it the best — takes minimal responsibility in the effort involved in making it generally usable to other units. This effort is instead placed on other teams within the organization.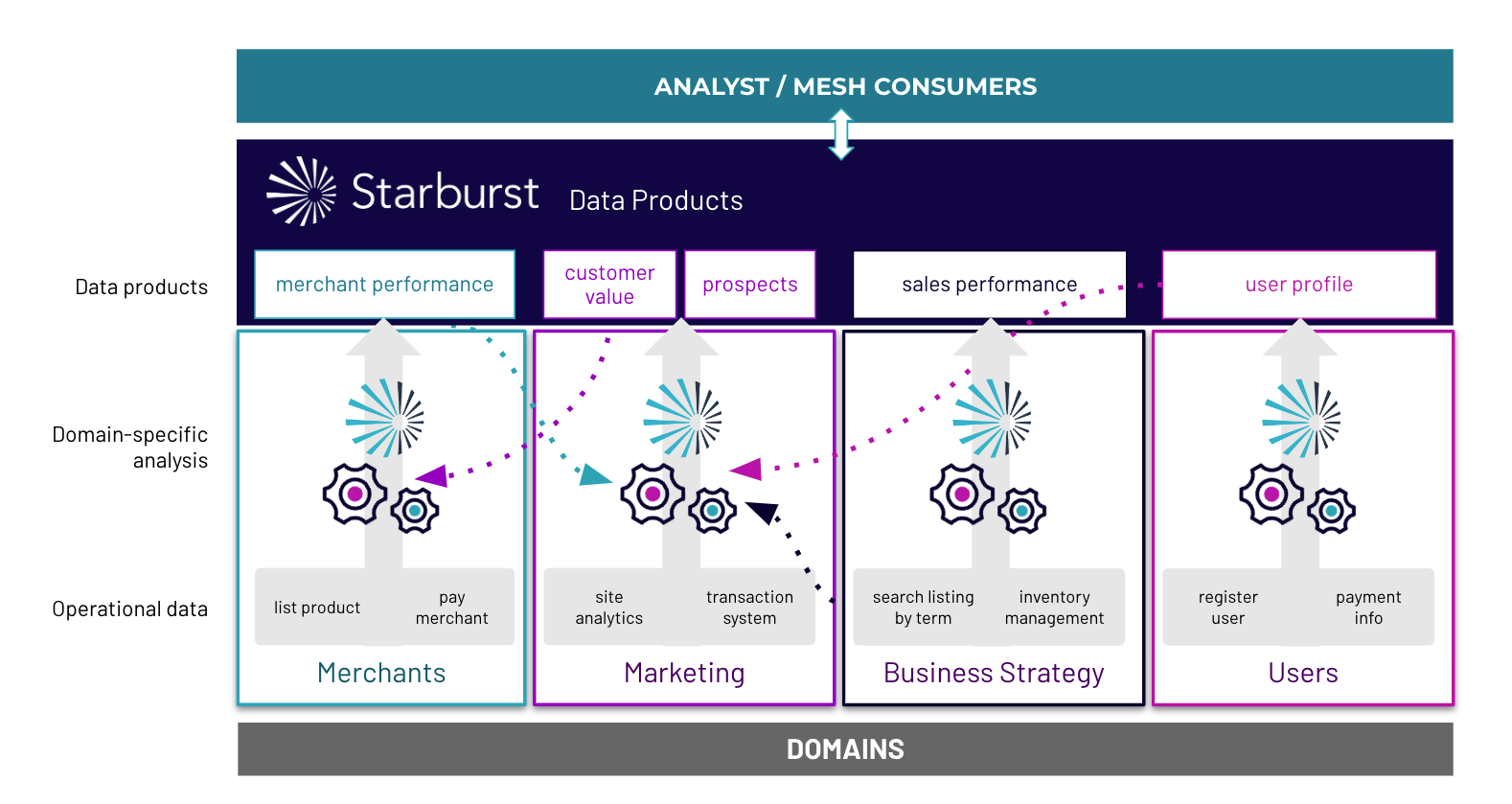
The radical shift in mentality behind the Data Product approach is to move much of this effort to the team that owns the dataset. Data cleaning and integration, in addition to cataloging and documentation, is thus performed by the team that understands the data best. Many of the data governance responsibilities, that were previously performed by a centralized team, now fall into the responsibility of the dataset owners. These owners are thus charged with a long term commitment to making the dataset available, and maintaining its long term data quality and business value. While there is some short-term pain, as the process of sharing a dataset becomes much more involved, the long term benefits greatly outweigh this short-term pain.
The physical storage of a Data Product, along with the tools required to query this data, is not necessarily the responsibility of the Data Product owner. It is still possible to require that Data Product owners utilize centralized data storage and query layers, that use standardized security and privacy protocols, when making the data available across an organization. However, the key difference from the traditional centralized approach is that no approval process from a centralized team is necessary for ingress of a Data Product into the repository. As long as the Data Product owner takes responsibility for the long term maintenance and documentation of the dataset, and can validate that they are upholding the set of data governance rules specified by the organization, the dataset becomes immediately available without the months-long delay under previous approaches.
To be successful, Data Product owners must think beyond the immediate set of groups within the organization that currently want access to the dataset, but must think more generally: who are the ultimate “customers” of this Data Product? What do they need to be successful? What are their expectations about the contents of the product? How can we communicate generally the contents and semantics of the dataset so it can be accessed and used by a generic “customer”?
The need for a centralized team does not disappear when using the Data Product approach. The centralized team still needs to define the data governance standards and facilitate validation of these standards when new products get introduced. Furthermore, they must negotiate with software vendors to provide data storage and query tools that Data Product owners can use during the process of creating and deploying their product. They also need to provide training so that Data Product owners can learn how to use these tools and develop the expertise necessary to perform important tasks such as data integration with existing datasets. It is generally helpful to provide template processes that can be used by a new team that wants to create Data Products at different levels of data governance restrictions depending on the intended use of the Data Product. Typically, they also maintain a global database of identifiers associated with customers, suppliers, parts, orders, etc. that Data Products must use when referring to shared conceptual entities. 
It is important to note that none of these centralized activities are done on a per-dataset basis. This is critical because any activity done on a per-dataset basis would bottleneck the introduction of new Data Products into the ecosystem.
Nonetheless, the Data Product approach is closer to the data silo side of the tradeoff than the centralized control side. Any team — as long as they take long term responsibility for the dataset — can create a Data Product and make it available immediately. Just like traditional real-world products, some products will become successful and widely-used, whereas others will end up in obscurity or go “out of business”. However, unlike the data silo approach, going “out of business” is an explicit decision by the team in charge of the Data Product to stop supporting the ongoing maintenance obligations of the product and removing its availability.
Additionally, just as traditional real-world products come with an expectation of documentation on how to use the product, a number to call when there are issues, and an expectation that the product will evolve as customer requirements change, so do Data Products. Similarly, just as traditional products need to take advantage of marketplaces such as Amazon to broadcast the availability of their product to potential customers, organizations need to create marketplaces for Data Products (which may include an approval process) so that Data Product producers and consumers can find each other. Moreover, just as real-world product sellers must provide the requisite metadata about their product so that it can appear in the appropriate places when searched for, along with other specs that define the parameters of the product, Data Product owners need to provide this information when deploying to a marketplace.
While there are many important factors for organizations to consider when implementing the Data Products approach, ultimately there is potential for many benefits –– greater agility, reduced bottlenecks, faster insights and teams that are empowered to do more. In today’s data-driven world, the ability to analyze the right data, quickly, is an extremely valuable, and virtually necessary trait for enterprises to possess. Organizations will find success by embracing a decentralized approach to data management by enabling data driven insights to be easily curated and shared across the enterprise through Data Products.
About the author: Daniel Abadi is a Darnell-Kanal professor of computer science at the University of Maryland, College Park and chief scientist at Starburst.
Related Items:
How to Maximize the Value of Data with Data Mesh
Data Mesh Vs. Data Fabric: Understanding the Differences
Starburst Announces New Data Product Functionality
Applications:
Data Management
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Starburst
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States