

April 7, 2023
Bringing Cloud Data Costs Under Control

(TAW4/Shutterstock)
It should come as no surprise that companies are struggling to contain the cost of storing and processing data in the cloud. With no upper limit on scalability, companies that were once data-starved can easily swing to being data-drunk. Unless companies are going to bring their data estates back on-prem, getting these costs under control is critical to the long-term health and stability of data operations.
There’s no shortage of data when it comes to understanding that cloud costs are spiraling out of control. A 2021 study by Anodot found that nearly one-third of data professionals reported their monthly cloud bills went up by nearly 50%, while one-fifth of them had their cloud bills double. In its 2022 State of Cloud Cost Report, Anodot says 54% of those surveyed believe their primary source of cloud waste is a lack of visibility into cloud usage.
News of excessive cloud spending is making its way to executives, many of whom greenlit moves to the cloud because it would be cheaper than running on prem. But forecasting and controlling cloud cost is a big challenge for 82% of decision-makers, according to 2022 Forrester report. “What was once meticulously planned and budgeted on-premises, is now unpredictable,” Forrester says in the report, which was commissioned by Capital One.
If the cloud is chaotic and expensive, how should companies proceed? Should they turn off their AWS and Microsoft Azure accounts and move everything back on-prem? That’s the option taken by one tech entrepreneur, Ruby on Rails creator David Heinemeier Hansson, who decided to move two of his tech startups off the public cloud and onto privately owned and managed servers after paying hefty cloud bills. “Do you know how many insanely beefy servers you could purchase on a budget of half a million dollars per year?” he said.
Moving back on-prem may make economic sense for some companies, but it’s a big lift for many more. While some cloud bills are high, many others companies are getting a tremendous amount of value from the public cloud, which has blossomed over the past few years into a veritable smorgasbord of big data goodness.
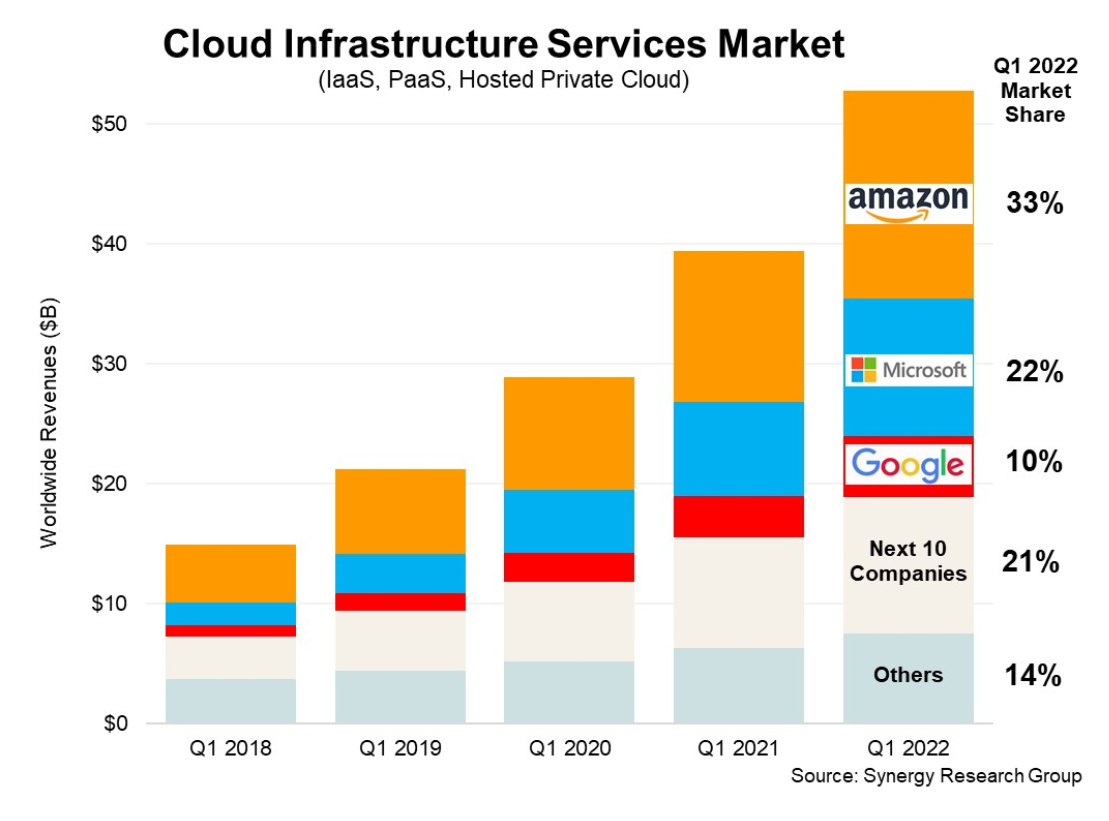
Cloud vendors enjoy health revenue growth (Source: Synergy Research Group)
The folks at Capital One have firsthand experience with how cloud costs can quickly get out of control, but they also understand the enormous value that public clouds can bring. The company started a migration of its data off on-prem Teradata systems and into Snowflake running on AWS in 2017, and completed it in 2020.
Capital One initially struggled with excessive cloud costs, as many companies do. They wanted to unleash analysts on the data to make the business more competitive, but in doing so they found the costs and controls in the cloud were lacking. It learned from that experience and used it to devise a unique set of data management tools designed to tackle that very problem.
New Cloud Rising
The new cloud paradigm requires new ways of thinking, according to Patrick Barch, the senior director of product management for Capital One Software.
“Yesterday’s models for managing your data ecosystem, for governing your data, no longer work in the cloud,” Barch says. “The concept of an enterprise data team that secures and manages the company’s enterprise data and is solely responsible for the underlying cost and budgeting for the platforms doesn’t really work in today’s day and age.”
The problem is, the cloud’s greatest strength is also a source of weakness, Barch says. That strength–the ability to store an unlimited amount of data and enable many more people to access that data and do creative things with it–is simultaneously one of the biggest challenges in managing data in the cloud and controlling spending. The deluge of data and analysts eager to access and query it simply overwhelms the old fashioned approach of empowering a centralized enterprise IT team to decide who can access what data, and how.
“So you skew towards enablement,” Barch says. “But if you do that, how do you ensure that the data is protected according to enterprise standards? How do you ensure in Snowflake, for example, your business teams aren’t provisioning 3 XL warehouses in a QA or dev environment, and really incurring more cost than they should? It’s really about walking the perfect balance between control and governance and empowerment.”
The cloud providers are not really in the business of helping their customers minimize spending, and you can’t really blame them. They do provide the mechanisms for controlling usage, but those controls can be complicated and require expertise to get the most out of them.
Capital One figured out how to do that, and then they wrote a piece of software that automates a lot of the nitty-gritty work of managing storage and compute resources in Snowflake, which they market and sell as the Slingshot product. “We take those primitives, as Snowflake calls them, and kind of package it up together into policies that work for the enterprise,” Barch says.
“Do you want everybody at your company to be a Snowflake expert, I guess is the question,” he continues. “You probably employ five to 10 people for a larger company that are really your experts in Snowflake. But if you want to empower the business teams, the question becomes, how do you make those five people act like 50? Because not everybody on the business side has the time to be a Snowflake expert. They’re worried about driving revenue. They’re worried about driving customer impact.”
Today, Capital One has thousands of users running millions of queries on the Snowflake data warehouse, which holds 60PB of data, Barch says. More importantly, the company has managed to get its usage of cloud storage and compute resources under control. Thanks to the tools it developed, Capital One was able to reduce costs by 27%, he says.
Gaining visibility and control over cloud usage is a critical step that companies must make if they’re going to make their cloud investments work long-term, Barch says. While cloud bills will probably still go up as the data volumes grow, the cloud customer will know that they’re getting value commensurate with that spending and not paying for resources that are wasted through ignorance and error.
“If you can’t predict how much you’re going to spend month-over-month, a consumption-based billing model is scary. And so you are probably more hesitant to turn on the spigot, so to speak, of data consumption,” he says. “The end result of that is you’re not leveraging the benefits that the cloud ostensibly provides around more data stored, giving access to that to more data to more people, giving your analysts free form access to all of the data the company has and enabling them to be creative.
“That’s really the promise the cloud is enabling: To create more and better analyses,” Barch continues. “But if you’re not enabling them to use that data because you’re afraid of how much you’re going to spend at the end of the month–well, that’s kind of like a broken promise.”
Related Items:
The Cloud Is Great for Data, Except for Those Super High Costs
Cloud Costs Exploding, Anodot Survey Finds
Cloud Migrations Negatively Impacting Data Estates, Capital One Says
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States