

February 1, 2023
NeuroBlade Seeks Controlled Growth for Big Data Bottleneck-Buster

(3dkombinat/Shutterstock)
Early adopters of NeuroBlade’s processing-in-memory (PIM) architecture, called XRAM, are showing a 10x to 60X boost in throughput for big SQL workloads. But the company is playing it safe on the growth front, so don’t expect the analytics-boosting appliance to be shipped in volume this year.
Elad Sity and Eliad Hillel co-founded NeuroBlade in 2018 to address the I/O bottleneck that emerges between processors and memory during some data-intensive workloads. They observed that standard RAM can’t move data into the CPU fast enough to keep its pipeline full, leaving processor cycles on the table and analysts waiting for their queries to complete.
Sity initially sought speed-ups using Intel’s Optane technology. It worked for a while, but eventually he discovered he could get the same level of performance by tweaking standard disk drives, so he looked elsewhere for better numbers.
Eventually, Sity and his co-founder decided to try the custom silicon route. By building a custom-designed RISC processor and mounting it directly onto memory, what’s called a PIM architecture, NeuroBlade could offload work from the main processor, therefore allowing it to run more efficiently and get more work done.
In addition to the XRAM modules, NeuroBlade uses NVMe drives in its Hardware Enhanced Query System (HEQS). Each HEQS appliance can hold about 100TB data, and up to six HEQS units can be strung together, providing 600TB in total capacity to augment data lakes, which sit next to the HEQS on the LAN.

Each HEQS unit from NeuroBlade stores about 100 TB of data (Source: NeuroBlade)
Initial results have been promising, with early adopters showing 10x to 60x reduction in processing time, the company says. NeuroBlade has worked very closely with early adopters–which tend to be large financial services firms that run their own gear–to ensure that the HEQS are giving them the benefit they expect.
While the technology and packaging is promising, these are early days still for NeuroBlade, and Sity wants to make sure that each customer gets the full attention of the company to ensure they’re successful with the product.
“The focus today is on high-end customer,” Sity tells Datanami. “We’re going to take a couple of years to get a GA system. It’s related [to the fact] that we’re still a startup. We cannot support that many different use cases. You still learn a lot from every engagement you have. You still need to be really, really on it, speaking from both product perspective and support perspective.”
While NeuroBlade is “plug and play” from the perspective of the customer–who essentially just places the HEQS next to their existing data lake–there’s still a lot of complexity taking place behind the scenes. Sity estimates it takes about a month and a half of software development to build the integration necessary to support a given database, file system, or object store with the NeuroBlade API.
“When we started talking to customers, what we realized is that what we actually built was a new piece of infrastructure for data analytics which takes into account the storage, the networking, the compute, with specific accelerators of course, for analytics,” he says. “And the most important piece is a lot of software that’s orchestrating all of the above.”
Because it’s directly in the query path and executing certain queries in its XRAM technology while leaving other queries to be handled by the regular query engine’s processor resources, NeuroBlade needs to make 100% sure that it’s not modifying the customers’ SQL in any way. That takes quite a bit of work, Sity says.
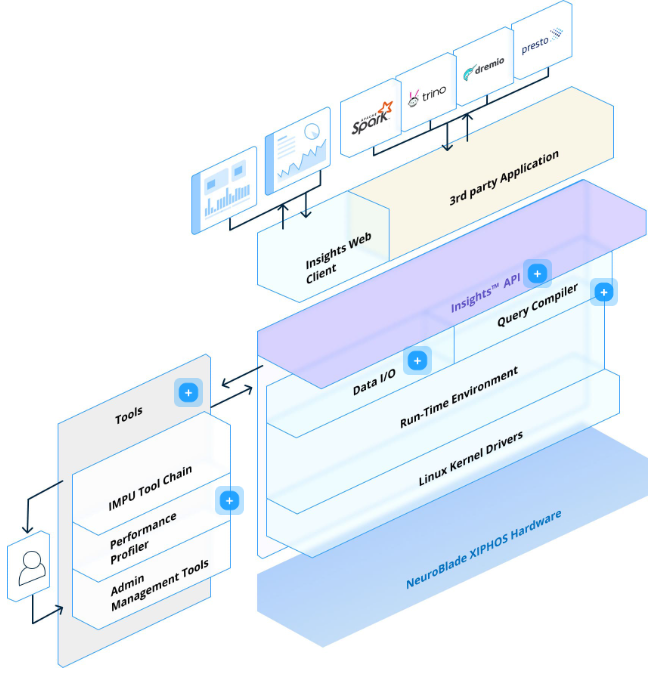
NeuroBlade’s HEQS architecture (Source: NeuroBlade)
“You can think of it as very complex software,” he explains to Datanami. “You get the query. We analyze it, and then we write code that realizes the query and then we compile it and then we download it to the hardware.”
NeuroBlade doesn’t support every data lake or data warehouse setup in the market. In fact, it’s fairly selective in choosing which environments it will work with. So far, it’s primarily been used in cloud-native data lake environments running on-prem using Presto, Trino, Spark, and Dremio query engines. Its architecture is not conducive for use in classic data warehouse environments where the compute and storage layers are closely linked.
“It’s not a small technical problem to be able to connect to the query engine of your database because you need to change the planning sometimes of your machine,” Sity says. “priority number one: Don’t change the query.”
Early adopters have been quite happy with the results so far, Sity says. They’re typically moving their most important queries into NeuroBlade, representing 10% to 50% of their total analytic query base, he says. The early adopters are able to use the greater efficiency either to crank up the generation of results from analyst SQL queries or save money by dramatically reduce the size of their existing analytic setup.
The company, which was founded in Israel, is growing selectively. It has raised than $110 million over A and B rounds, and opened its US headquarters in Palo Alto last year to help tackle the lucrative North American market.
Supply chain issues in the semiconductor industry haven’t been completely ironed out, which doesn’t help firms building custom silicon like NeuroBlade. Even so, Sity says the company is getting by. “Quantities are not big,” he says. “Sometimes we pay more…but we can manage.”
The bigger priority for company’s future is to ensure that each customer is successful with the offering, Sity says.
“We’re in some big engagements right now. But we’re going to very opportunistic, when the right opportunity come along,” he says. “I think the world proved us that you don’t need to grow very fast. You need to grow very healthy.”
Related Items:
NeuroBlade Tackles Memory, Bandwidth Bottlenecks with XRAM
Filling Persistent Gaps in the ‘Big Memory’ Era
The Past and Future of In-Memory Computing
Applications:
Enterprise Analytics
Technologies:
Processors
Sectors:
Financial Services
Vendors:
Neuroblade
Tags:
big data, Dremio, Elad Sity, hardware accelerator, PIM, presto, processor in memory, Spark, SQL analytics, Trino, XRAM
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States