

October 28, 2022
How Snowplow Breaks Down Data Barriers

(DestroLove/Shutterstock)
If you have suspicions about your data, you’re not alone. The AI and data analytics dreams of many a company have been broken by poor data management and defective ETL pipelines. But by enforcing data schema at the point of creation and providing a single data model for all downstream AI and BI use cases, a company called Snowplow Analytics is making headway against the avalanche of questionable data.
In a perfect world, all our business data would be trustworthy and perfectly reflect the actual state of reality, in the past, present, and the future. There would be no questions about where the data came from, the values would never drift unexpectedly, schemas would never change (because we had it perfect the first time), we would all use the same grammar to query the data, and all the derived analytics and ML products that came from that data would give 100% correct answers every time.
Of course, we live in a decidedly imperfect world. Instead of trusting the data, we view it with suspicion. We constantly question the source of data, and we wonder why the values fluctuate unexpectedly. Schema changes are major life events for data engineers, and the CEO doesn’t trust her dashboards. We haven’t made progress with AI because the data is such a mess.
This is the main driver behind Snowplow Analytics. Founded in London nearly 10 years ago by Alexander Dean and Yali Sassoon, Snowplow developed an open source event-level data collection technology called Iglu that helps to ensure that only well-structured and trustworthy data makes it into a company’s internal system.
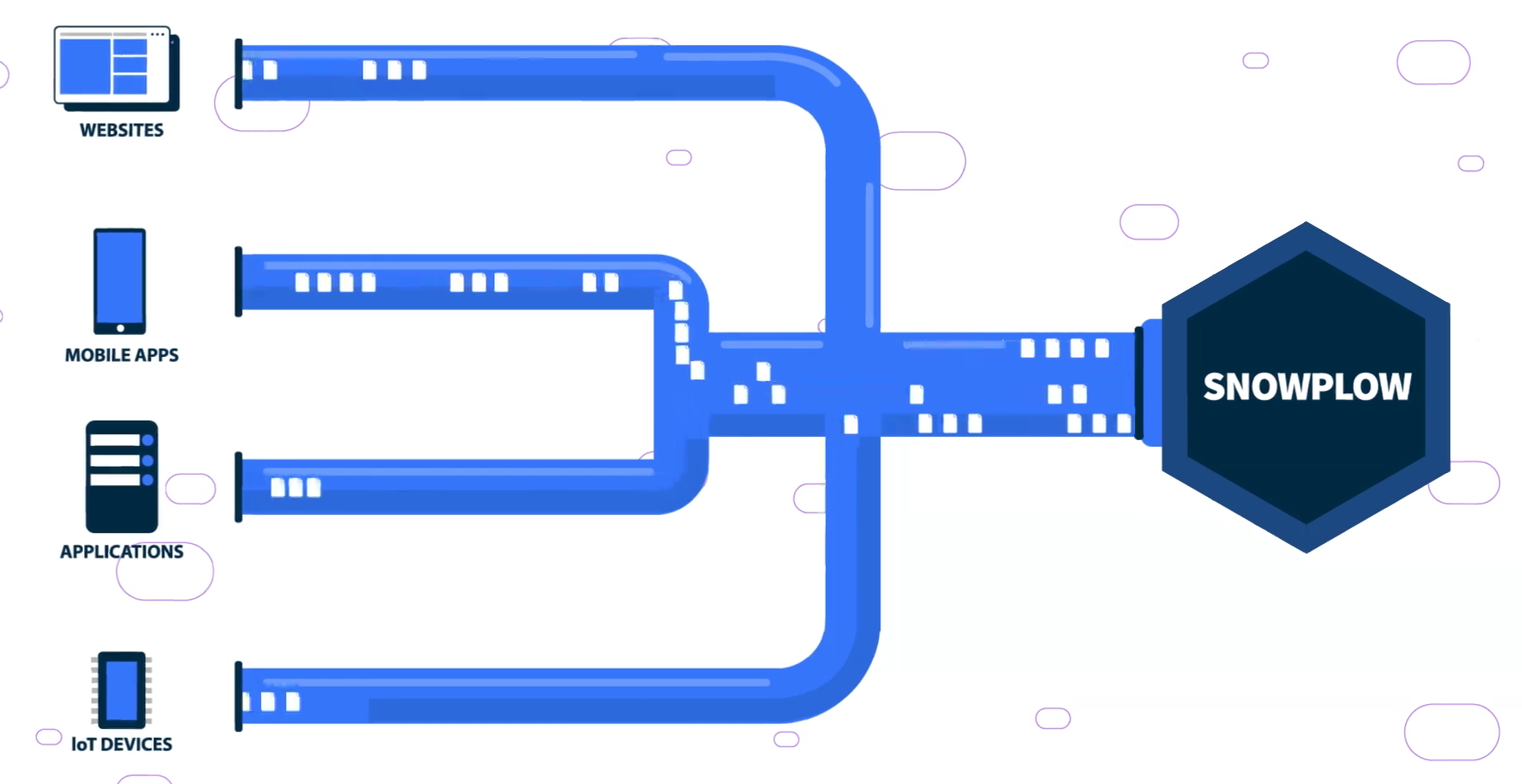
Snowplow’s Iglu schema registry enforces data quality before it hits customer data pipelines and storage
Snowplow looks at the problem from the standpoint of data creation. Instead of just accepting the default schema offered by vendors like Salesforce or Marketo–or any number of other applications that it can hook into via SDKs–Snowplow functions as an abstraction layer that converts the data provided by those vendors into a format that adheres to the semantics chosen by the customer
“Rather than trying to take data sources and work some magic to make them somewhat representative of your business, we go the other way, and say, hey, represent your business and we’ll create the data for that, and then we’ll take the third-party data and merge to it,” says Nick King, Snowplow’s president and chief marketing and product officer.
“The reason that’s so powerful is there’s just so much noise in third-party data,” he continues. “Everyone has a different schema. There’s so much maintenance…in those pipelines, so you end up with these really complicated, brittle pipelines, and a bunch of assumptions in the data. When you do it from a Snowplow perspective, you have complete data lineage. You can ensure and enforce policies at the edge, so you can ensure no biased data gets into your pipelines. You understand the data grammar.”
Companies get started with Iglu by defining their data schema, their data model, and their grammar. When an organization wants to load outside data through an ETL or ELT pipeline, that data must conform to Iglu’s schema registry before it can land in an atomic table residing in the company’s lake, warehouse, or lakehouse, King explains.
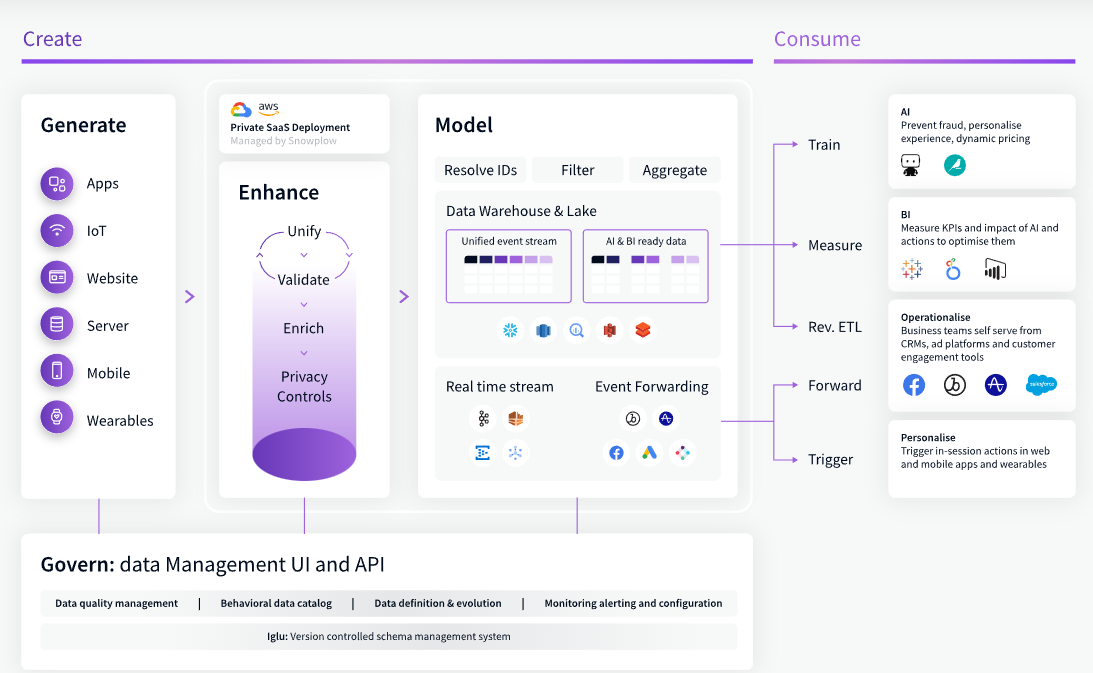
Snowplow acts as a source of data for AI and BI uses cases
“It’s a really very different way of looking at data management,” he says. “There’s just a really huge amount of waste and resource maintaining those data pipelines, whereas if you use Snowplow’s approach, we’ll define a data language that is for your organization. We’ll help create those events. We ensure schema consistency, so you don’t have to evolve the schema.”
When a schema needs to change, Snowplow helps ensure that the change is made in a controllable way. “You’ve sort of ensured that everything in your data warehouse is schema compliant,” King says. “You can evolve your schema as you need to. So we don’t think of schema-first or schema-second. We sort of think schema always.”
The goal is for Snowplow to become the trusted source of data for an organization. If a piece of data has landed in Snowplow’s atomic event table, that means it passes muster and has been determined to adhere to the schema and data rules that a customer put in place, King says.
“It’s kind of like the blue checkmark of data,” he says. “It’s like farm-to-table, creation-to-table data. You know exactly where it’s come from. You know the entire lineage of it.”
This approach can alleviate a lot of the pain and suffering involved with getting data ready for machine learning and AI use cases. But it can also help users trust their data for advanced analytics.![]()
For example, for a marketing user case, Snowplow might provide a pre-packaged set of data that includes the identity of a website visitor, any demographic or location data, and a history of clicks or navigation. The product can even stitch together multiple visits through time, which can make it easier for analysts to find actionable insights.
King says Autotrader uses Snowplow to bundle website visitor data for analysis. A website visitor may bounce around among two or three vehicles types and come back to the website three or four times.
“So you try to understand, OK is there a commonality? Have they gone back to Toyota versus Ford, and therefore Toyota should be higher up in the space? Have they been clicking on financing terms?” King tells Datanami. “That’s where behavioral data gets really interesting. It’s actually mathematically quite hard to stitch together a sequence of event, but when you approach it the way we do, we kind of inherently provide that sequence of events, because we can rejoin many different touch points over time.”
Snowplow cuts a wide swath across the data market. It competes with the ETL/ELT and data pipeline vendors. It can be said to compete with Google Analytics, as well as the various customer data platform (CDP) vendors. The difference with Snowplow, King says, is Snowplow wants to help customers create and run their own CDP on Snowflake, BigQuery, or Redshift, versus storing their data on a proprietary CDP platform.
“We want to maintain that whole data product management lifecycle,” King tells Datanami. “We want to help them create the data. We want to help them integrate third party data sources. We want to help them maintain core tables and publish data products. We want to look across that whole platform and actually fuel the business to help them take advantage of that data, but also to make the data product managers’ and data architects’ and data engineers’ lives a lot easier.”
Related Items:
What’s Holding Up Progress in Machine Learning and AI? It’s the Data, Stupid
MIT and Databricks Report Finds Data Management Key to Scaling AI
A Peek At the Future of Data Management, Courtesy of Gartner
Applications:
Data Management
Technologies:
Middleware
Vendors:
Snowplow
Tags:
AI, analytics, bi, big data, CDP, data creation, data data, data language, data modeling, data pipeline, data quality, data schema, ETL, machine learning
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States