

October 4, 2022
Developing Kafka Data Pipelines Just Got Easier

(Blue Planet Studio/Shutterstock)
Developing data pipelines in Apache Kafka just got easier thanks to the launch of Stream Designer, a graphical design tool that is now available on Confluent Cloud. Confluent also used this week’s Kafka conference, dubbed Current 2022, to announce a new version of its Stream Governance offering that adds point-in-time lineage tracking to the mix.
There’s no denying the power and popularity of Apache Kafka for building streaming data pipelines. Kafka is pretty much the undisputed heavyweight champion in this category, with 80% of the Fortune 100 using the open source product, which was originally developed at LinkedIn to store and query large amounts of streaming event data.
But along with that streaming power comes technological complexity, both in terms of getting the Kafka cluster set up and also in the development of data pipelines. Confluent has addressed the infrastructure complexity with its hosted Kafka offering, dubbed Confluent Cloud. And with today’s launch of Stream Designer, it’s taking a bite out of the design-time complexity too.
With Stream Designer, Confluent is giving Kafka users a way to design data pipelines in a visual manner. Instead of constructing a Kafka data pipeline from scratch by writing SQL. As a Directed Acyclic Graph (DAG), Stream Design allows users to construct data pipelines by dragging and dropping elements on a screen, which the product then converts to SQL that’s executed on the Kafka cluster, just as it did before.
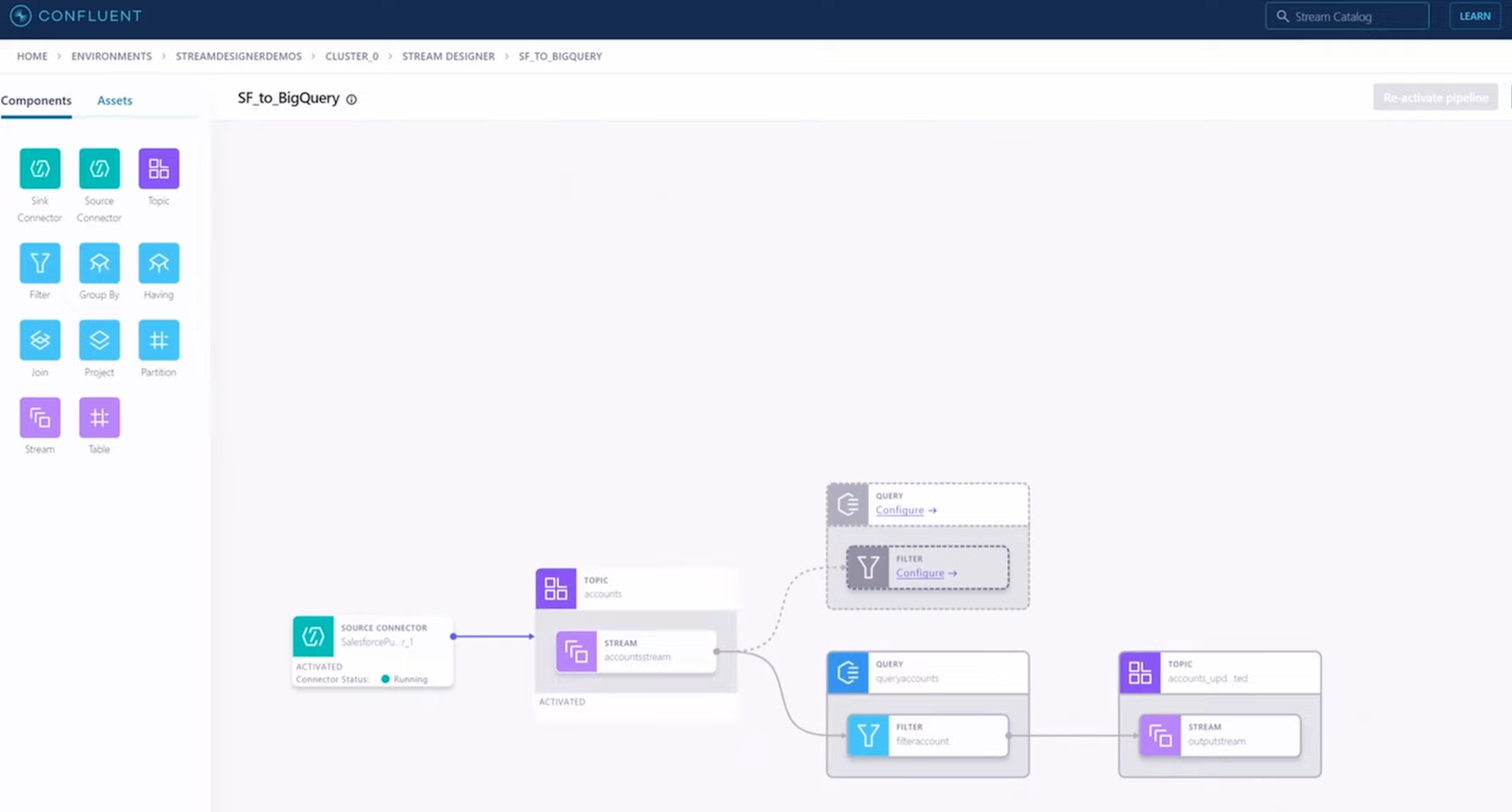
Stream Designer is a drag-and-drop environment for creating data pipelines for Apache Confluent
Stream Designer will appeal to all Kafka users, including Kafka newbies who are just getting their feet wet with streaming data, as well as those with a lot of experience on the platform, says Jon Fancey, principal product manager at Confluent.
“It can often feel with any new technology that you have to learn everything before you do anything,” Fancey says. “If you’re relatively new to Kafka, some of the concepts and the learning curve can feel pretty steep. So Stream Designer provides an easier on ramp for you to be able to build things graphically.”
Confluent does a lot of stuff for the user automatically. For instance, since Kafka Connect connectors write data to topics (“It’s what they do,” Fancey says), Confluent created Stream Designer to automatically create and configure a topic for the user when they select one of the 70-plus connectors available.
The product also lets users add stream processing capabilities to the pipeline, including filtering data and context-based routing, which will push results to an analytical database like Snowflake or Google Cloud Big Query, Fancey says.
“We can also do things like aggregation on the data, so maybe you can group it, summarize it over that streaming set of data,” he tells . “So essentially everything you can do in ksql that we have as our stream processing query engine, you can do in Stream Designer. And everything you can do in Connect with all the connectors that we have, you can do in Stream Designer as well.”![]()
Stream Designer includes a built-in SQL editor, allowing users to go back and forth from the GUI design tool to the command line editor. Users can export the SQL generated by Stream Designer into code repositories, like GitHub, to provide change management capabilities. Users can also bring externally written SQL into Stream Designer, and work with it there, Fancey says.
But Stream Designer won’t just function as training wheels for Kafka beginners. According to Fancey, old Kafka hands will also find useful capabilities in the new product, such as the new observability metrics that highlight potential problems in a running Kafka cluster, and then surface the information necessary for the engineer to fix it.
“You can see the data flowing end to end and you can look at the lag of the data so you can understand if the pipeline is running effect and correctly at all times,” Fancey says. “And if there is a problem–maybe you have an issue with one of the tasks that’s running on the connector–we actually flag that for you. We alert you in the design canvas, and you can click into that and do a diagnosis, where we’re kind of surfacing up some of the internal log information into one place, instead of having to … jump around the platform to figure out what’s going on.”
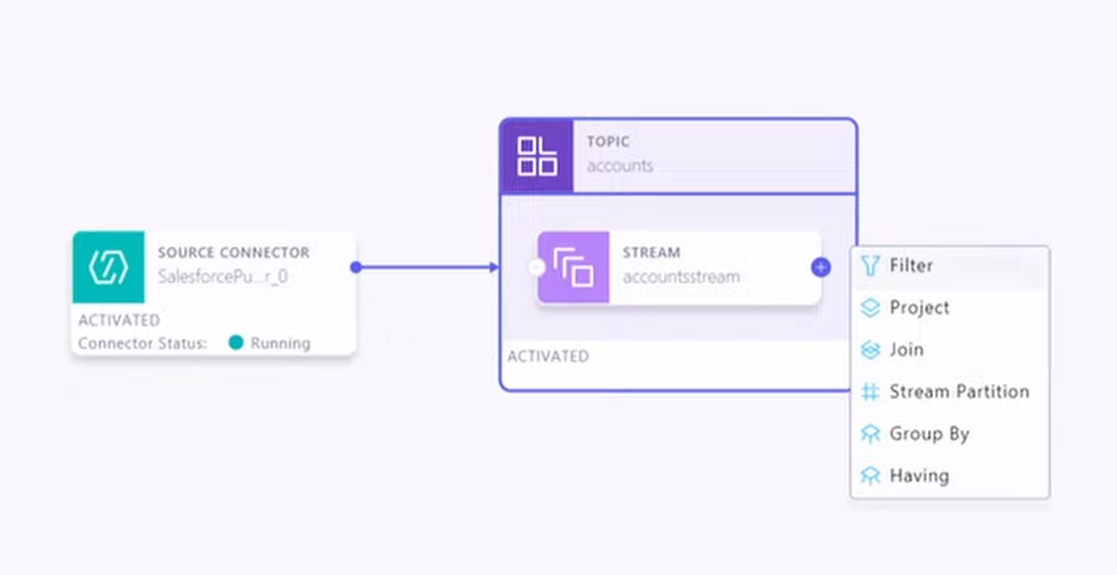
Everything you can do with ksqlDB, including filtering and aggregations, you can do with Confluent’s new Stream Designer
As data pipelines start to proliferate at companies, the creation and management of them can quickly become a bottleneck to productivity. The tools and techniques that data engineers originally used with a handful of pipelines may not work when 100 or 1,000 pipelines are at play. By adding a GUI to the mix with Stream Designer, Confluent is giving users the option to choose which modality works for them. And users can always go back to and make tweaks to the generated SQL by hand, Fancey says.
“The code you would write in Stream Designer is the same code you would write without Stream Designer, with zero performance penalty,” Fancey says. “Some other tools don’t work the same way.”
For more info on Stream Designer, check out today’s Confluent blog post on the topic (no Connector necessary).
Streaming Data Governance
The other big announcement is the launch of Stream Governance Advanced.
Confluent previously launched its Stream Governance suite about a year ago. Today, Confluent is debuting Stream Governance Advanced, which adds several important new capabilities to the mix (the capabilities in the pre-existing product are now referred to as Stream Governance Essentials).
The biggest feature is the addition of point-in-time playback capability for data stream lineage. In the previous product, customers could go back and do a deep inspection of the previous 10 minute’s worth of streaming data. With this release, that window has been expanded to 24 hours, which will give users a much finer-grained look at what happened with their data, Fancey says.
“Maybe you had an issue in your environment yesterday,” he says. “You can actually go back in time to determine what caused that, and you can actually wind the clock back and look at those data flows as they existed at a previous point in time.”
In fact, Stream Governance Advanced goes beyond that, and allows users to inspect the previous seven-day window. However, that capability is only available with hourly blocks of data, meaning the data is less fine-grained (but still potentially useful).
When somebody says there’s a problem with the cluster, and they want to look at the log, the response often has been “well, they’re gone. The idea is to avoid those types of situations and given users the ability to track down those problems instead of waiting for them to reoccur, Fancey says.
Stream Governance Advanced also builds on the data catalog capability that Confluent previously launched (which is now available in Essentials). In the previous release, users could tag objects. With this release, Confluent has added the ability to track business metadata, which the company says will improve the ability for users to discover data in their streaming data catalog.![]()
Confluent has also added a GraphQL API, which will allow users to be more targeted in receiving only the specific data elements that they’re looking for in their query, as opposed to getting back much more data than they wanted.
Stream Governance has been well-received by Confluent customers so far, Fancey says, and the new features Confluent is launching with Advanced reflect the needs that early adopters have.
“It solves a problem that creeps up on you,” Fancey says. “The ability to govern data at scale…in a large estate can feel like a problem that you wish you’d planned for. Governance provides this capability straight away, and this is why we’re introducing Advanced.”
While users could conceivable create their own tools to govern the data, or perhaps buy third-party tools (although few, if any, exist for streaming data, which is a nascent category), the option of going without any governance increasingly is not an option for companies.
“The alternative is no governance, which means you end up with poor outcomes,” Fancey says. “Maybe [you get] low quality, untrusted data. You don’t understand the provenance of it. You don’t know who owns it. Governance solves a lot of these challenge, and Advanced provides more ability to add things like business metadata to the schemas, to the data, flowing through, so you can understand where it comes from, who owns it, how you contact them, and how you should be using it.”
Today marks the first full day of Current 2022, which is the follow-on to the Kafka Summit conference that Confluent previously sponsored. You can find more information about this currentevent.io.
Related Items:
It’s Time for Governance on Streaming Data, Confluent Says
Confluent Delivers New Cluster Controls, Data Connectors for Hosted Kafka
Intimidated by Kafka? Check Out Confluent’s New Developer Site
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States