

September 20, 2022
Apache Druid Shapeshifts with New Query Engine

(Yurchanka Siarhei/Shutterstock)
Apache Druid is known for its capability to deliver sub-second responses to queries against petabytes of fast-moving data arriving via Kafka or Kinesis. With the latest milestone of Project Shapeshift, the real-time analytics database is morphing into a more versatile product, thanks to the addition of a multi-stage query engine.
With more than 1,000 organizations using Apache Druid in production applications, including NYSE, Amazon, and Verizon, it’s becoming clear that Druid is finding a niche when it comes to keeping interactive applications fed with the latest data.
That niche sits at the junction of two well-established database types, including transactional systems like MongoDB and analytics databases like Snowflake, says David Wang, vice president of product marketing for Imply, the commercial entity behind Druid.
The two databases are designed for different workloads, Wang says. Transactional databases traditionally are optimized for writing data and serving a large number of requests very quickly in an ACID compliant manner, he says. Analytics databases, on the other hand, store aggregated data in a read-optimized manner, and serve a smaller number of requests without the same sense of urgency.
Druid is unique in that it delivers characteristics of both types in a way the market hasn’t seen before, he says.
“There is an emerging market that’s forming at the intersection of analytics and applications,” he says. “You look at this intersection in the middle, you have folks like Snowflake who are adding row storage. Their tagline is run analytic queries on real time transaction events. You have folks like MongoDB who are adding columnar storage, who are saying, hey not only do you care about real-time events, but you now care about historical data.”![]()
Where Druid excels is delivering the type of aggregated data that would traditionally be served from an analytics database, but doing it in a sub-second, highly concurrent manner with the types of transactional guarantees that would normally be done with a transactional system. Wang and his Imply colleagues call these “modern analytics applications.”
“There is a third use case that really [calls for] for a modern analytic application that’s marrying strengths…from both the analytics world and the transactional world,” he says. “Specifically, user applications where the developers and architects are being asked to pull together a use case that support read-optimized, large group-bys, and aggregation on some data. But Druid is doing that with instant, sub-second response, and doing that at high peak concurrency.”
There’s no one thing in Druid that enables the database to check all these boxes, says Vadim Ogievetsky, co-creator of Apache Druid project and co-founder and CXO at Imply.
“It’s a salad bar,” Ogievetsky says. “You can literally check all the boxes for things that make it go fast. It has very read-optimized compression. It has columnar storage, so you only read the column that you need. It has different filters, time partitions. The way you do data dictionaries and the index structure are very specific to make reading and filtering very, very fast.”
None of these concepts on their own are new or unheard of, Ogeivetsky says. But in combination, they can help Druid to query large amounts of data and deliver results in a hurry.
Imply today announced the completion of Mile 2 of Project Shapeshift, which is delivered as Druid version 24.0. A key new capability delivered in this milestone is the introduction of a multi-stage query engine that enables the database to take on workloads that it didn’t excel at before.
According to Ogievetsky, the new engine will help with queries such as running batch queries against massive amounts of data, as opposed to the fast response times the original query engine delivered.
“That’s really the kind of engine that you find in more traditional data warehouse,” he says. “It’s not optimized for interactivity or the things that are in the black box. It’s optimized just for being able to haul a whole a bunch data from one place to another place.”
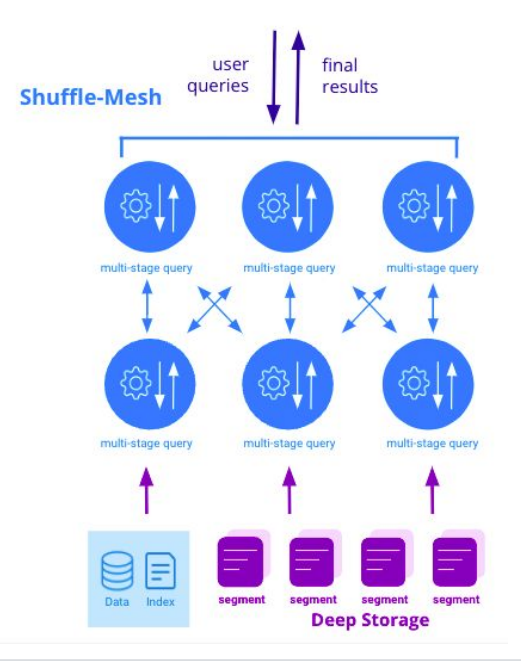
Druid 24 adds a new query engine with a shuffle-mesh architecture (Image courtesy Imply)
If the original engine was a Ferrari that was designed to return a small amount of data but do so very quickly, the new query engine is a semi-truck that’s designed to return a large amount of data but not in such a performant manner, Ogievetsky says. “The other engine is more like an 18-wheeler,” he says. “You can really haul whatever you want.”
The new query engine, which is based on a shuffle-mesh architecture (as opposed to the scatter/gather architecture of the original query engine) also gains support for schemaless ingestion to accommodate nested columns, which allows for arbitrary nesting of typed data like JSON or Avro, the company says. It also supports ingestion of DataSketches at high speeds “for faster subsecond approximate queries,” it says.
“Now you can point Druid at some data in S3, in whatever format you have–Parquet or JSON–and read it and load it into Druid with whatever transformation that you need to apply,” Ogievetsky says.
Druid 24.0 also brings more standardization on SQL, which will be useful for loading data instead of the “job spec” that was previously used. “Starting with Druid 24, it [SQL] will be the language that you use to interact with every aspect of Druid,” Ogievetsky says.
New in-database transformation capabilities are also being delivered with this release, including using INSERT INTO commands to roll data up from one Druid table and copy it to another. There is also the capability use the new SELECT with INSERT INTO with EXTERN and JOIN to combine and roll up data from Druid and external tables into a Druid table, the company says.
The new SQL-based ingestion and transformation routines will help Druid integrate with an array of other vendors in the big data ecosystem, including dbt, Informatica, FiveTran, Matillion, Nexla, Ascend.io, Great Expectations, Monte Carlo, and Bigeye, among others.
Imply is also enhancing Polaris, it’s database-as-a-service based on Druid. Many of the enhancements in Druid 24 will flow to Polaris. But the company has a few extras that it offers with its commercial service.
For example, with this release, Polaris will get new alerts that automate performance monitoring, as well as improved security via new access control methods and row-leve-security. There are also updates to Polaris’ visualization capabilities, which enables faster slicing and dicing, the company says.
The company also announced its “total value guarantee,” in which qualified participants will get a discount on the offering that effectively makes the service free, the company says. For more information, check out the company’s website at www.imply.io.
Related Items:
Apache Druid Gets Multi-Stage Reporting Engine, Cloud Service from Imply
Druid-Backer Imply Lands $70M to Drive Analytics in Motion
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States