

August 23, 2022
Anyscale Branches Beyond ML Training with Ray 2.0 and AI Runtime

(kwarkot/Shutterstock)
Anyscale today came one step closer to fulfilling its goal of enabling any Python application to scale to an arbitrarily large degree with the launch of Ray 2.0 and the Ray AI Runtime (Ray AIR). The company also announced another $99 million in funding today at Ray Summit, its annual user conference.
Ray is an open source library that emerged from UC Berkeley’s RISELab to help Python developers run their applications in a distributed manner. The software’s users initially have focused on the training component of machine learning workloads, which usually demands the biggest computational boost. To that end, the integration between Ray and development frameworks like TensorFlow and PyTorch has enabled users to focus on the data science aspects of their application instead of the gory technical details associated with developing and running distributed systems, which Ray automates to a high degree.
However, ML training isn’t the only important step in developing AI applications. Other critical parts of the AI puzzle include data ingestion, pre-processing, feature engineering, hyperparameter tuning, and serving. To that end, Ray 2.0 and Ray AIR bring enhancements designed to enable these steps to run in a distributed manner.
“Today the problem is that you can scale each of these stages, but you need different systems,” says Ion Stoica, Anyscale co-founder and President. “So now you’re in a situation [where] you need to need to develop your application for different systems, for different APIs. You need to deploy and manage different distributed systems, which is absolutely a mess.”
Ray AIR will serve as the “common substrate” to enable all of these AI application components to scale out and work in a unified manner, Stoica says. “That’s where the real simplicity comes from,” he adds.
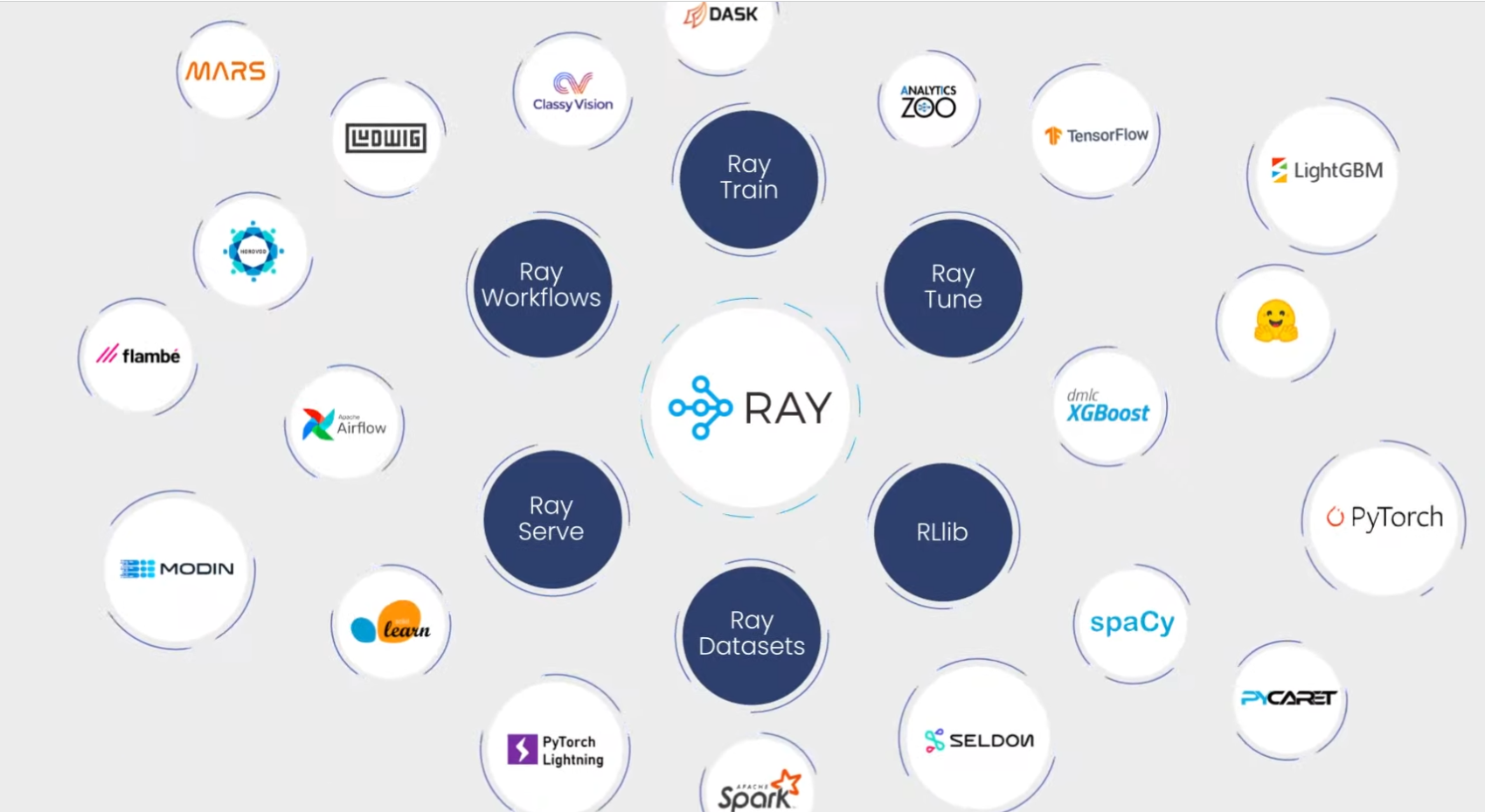
Ray is pre-integrated with many ML frameworks (image source: Anyscale)
Ray AIR and Ray 2.0 are the result of work Anyscale has done with big tech firms over the past couple of years, says Anyscale CEO and co-founder Robert Nishihara, who is the co-creator of Ray.
“We’ve been working with Uber, Shopify, Ant Group, OpenAi and so on, that have been trying to build their next-gen machine learning infrastructure We’ve really seen a lot of pain points they’ve run into, and shortcomings of Ray, for building and scaling these workloads,” Nishihara says. “We’ve just distilled all the lessons from that, and all the pain points they ran into, into building this Ray AI Runtime to make it easy for the rest of the companies to scale the same kind workloads and to do machine learning.”
Ray was originally designed as a general-purpose system for running Python applications in a distributed manner. To that end, it wasn’t specifically developed to help with the training component of machine learning workloads. But because ML training is the most computationally demanding stage of the AI cycle, Ray users gravitated towards the training component for their AI systems, such as NLP, computer vision, time-series forecasting, and other predictive analytics systems.
Representatives from Uber will be speaking at Ray Summit this week to share how they used Ray to scale Horovod, the name of the distributed deep learning framework that it uses to build AI systems. When Uber used Ray to enable Horovod to handle training at scale, it exposed bottlenecks at other steps in Uber’s data program, which limited the effectiveness of an important part of its ride-sharing application.
“As they scaled the deep learning training, data ingest and pre-processing became a bottleneck,” Nishihara says. “Horvod doesn’t do data pre-processing, so they were basically limited in the amount of data they could train on, so only one to two weeks. They wanted to get more data to get more accurate ETA [estimated time of arrival] predictions.”
Uber was an early adopter of Ray AIR, which enabled the company to scale other aspects of its data pipeline to get closer to parity with the amount of data going through DL training.

Ray co-creator Robert Nishihara is the co-founder and CEO of Anyscale
“They were able to use Ray for scaling the data ingest and pre-processing on CPU nodes and CPU machines, and then feed that into the GPU training with Horvod, and actually pipeline these things together,” Nishihara tells Datanami. “That allowed them to basically train on much more data and get much more accurate ETA predictions.”
While there’s a lot of hype around AI, building AI applications in the real world is difficult. A recent Gartner study found that only about half of all AI models ever make it out of production and into the real world. The failure rates of AI applications have historically been high, and it doesn’t appear that they are coming down very quickly.
“First and foremost, we’re about the compute,” Stoica says. “This is the next big challenge we identified. Basically, the demands of all these applications are skyrocketing. So this is very hard to garner all these compute resources to run your applications.”
The folks at Anyscale believe that targeting the computational and scale aspects of AI applications will have a positive impact on the poor success rate for AI. That’s true for the big tech firms of the world all the way down to the mid-size companies with AI ambitions.
“A lot of AI projects fail,” Nishihara says. “We work with Uber and Shopify. They’re fairly sophisticated. Even they are struggling with managing and scaling the compute. I think if AI is really going to transform all these industries, everybody is going to have to solve these problems. It’s going to be a big challenge.”
Ray 2.0 also brings closer integration with Kubernetes for container management. KubeRay gives users the ability to run Ray on top of Kubernetes, Nishihara says. “Kubernetes native support is super important,” he says. “You can run Ray anywhere, on a cloud provider, even your laptop. That portability is important.”![]()
Anyscale also introduced its enterprise-ready Ray platform. This new offering brings a new ML Workspace that’s designed to simplify AI application development. Stoica says the new Workspace “is going to make it easy for you to go from development to productions much easier, to collaborate and share your application with other developers.” He also says it will bring features like cost management (important for running in the public cloud), secure connectivity , and support for private clouds.
The ultimate goal is to prevent developers from even thinking about hardware and infrastructure. In the old days, programmers wrote in Assembler and were concerned about low-level tasks, like memory optimization. Those are things of the past, and if Anyscale has its way, perhaps worrying about how a distributed application will run will be a thing of the past, too.
“If we’re successful, the whole point of all of this is really get to the point where developers never think about infrastructure–never think about scaling, never think about Kubernetes or fault tolerance or any of those things,” Nishihara says. “We really want any company or developer to really be able to get the same benefits that Google or Meta can get from AI and really succeed at AI, but never think about infrastructure.”
Last but not least, the San Francisco company also announced some additional funding. The company today announced $99 million in Series C funding, which adds to the existing $100 million Series C that it announced in December 2021. The second Series C round was co-led by existing investors Addition and Intel Capital with participation from Foundation Capital.
Ray Summit 2022 runs today and tomorrow. The conference is hosted in San Francisco and also has a virtual component. More information on Ray Summit is available at www.anyscale.com/ray-summit-2022.
Related Items:
Half of AI Models Never Make It To Production: Gartner
Anyscale Nabs $100M, Unleashes Parallel, Serverless Computing in the Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States