

July 12, 2022
Soda Envisions Data Reliability as Code with SodaCL

(Shutterstock/Chim)
Soda today announced the general availability of Soda Checks Language (SodaCL), a new domain specific language designed to enable data engineers to deliver data reliability checks as code within Soda Core, a new framework that it also announced. The two deliverables represent the company’s latest approach to solving the challenge of data observability at scale.
Every data-driven business needs high quality data if it’s going to automate decision-making through advanced analytics and AI, let alone scale traditional BI (which has always suffered from quality issues with data). But getting high quality data in sufficient volume to keep those automated decisions flowing is not a solved problem.
Today, data engineers typically fall back on manual methods to check for data errors and fix those errors when they invariably pop up in the data pipelines. While these manual data engineering techniques can work, they’re limited, insofar as they are mostly manual (or an accumulation of scripts).
That’s the general problem area that Soda and other data observability firms are hoping to tackle with their solutions. For Soda, the latest weapon in the war on poor data quality is SodaCL and Soda Core.
SodaCL is contained in Soda Core, a new open source framework designed to help data engineers with data quality, observability, and data monitoring. The framework features a command line interface (CLI) where engineers can read and write custom data quality checks in Soda CL. The framework also includes a library of pre-built checks for data quality, an anomaly detection engine, and data drift checks.
SodaCL and Soda Core are designed to allow engineeers and others to instrument data quality and error checks into data pipelines
Soda CL emerged out of an earlier effort by Soda to create another language, called Soda SQL, which was developed to help data engineers maintain reliable data pipelines by automating data profile, test, and monitoring functions.
The company went “all in” on SQL for three reasons, according to a February blog post by Soda co-founder and CTO Tom Baeyens: users could leave their data where it was; SQL was flexible; and SQL was popular. Soda SQL shipped in 2021.
“But we knew there was more that we could do to better serve the Data Engineering and Analysts of the world, who often find themselves firefighting data issues when reports, dashboards, or machine learning models break,” Baeyens says. Hence the company decided to build a DSL to tackle this specific problem.
While Bayens understood that a certain number of users would complain about having to learn another DSL, he was steadfast in the market need for such a thing.
“…[D]ata reliability needs its own language,” he wrote. “It needs a language that is specific enough to address the problems that data teams face, accessible enough for non-engineers to use, and flexible enough to dig into lots of different kinds of data to find, analyze, and resolve issues fast. In the long run, it will be worth the short-term capital outlay of time and effort.”
A video demonstrates how users can get started with Soda Core and SodaCL. Once the CLI is fired up, users can create a connection to a separate databases. The user then goes through the process of setting up the various checks that he or she wants to run.![]()
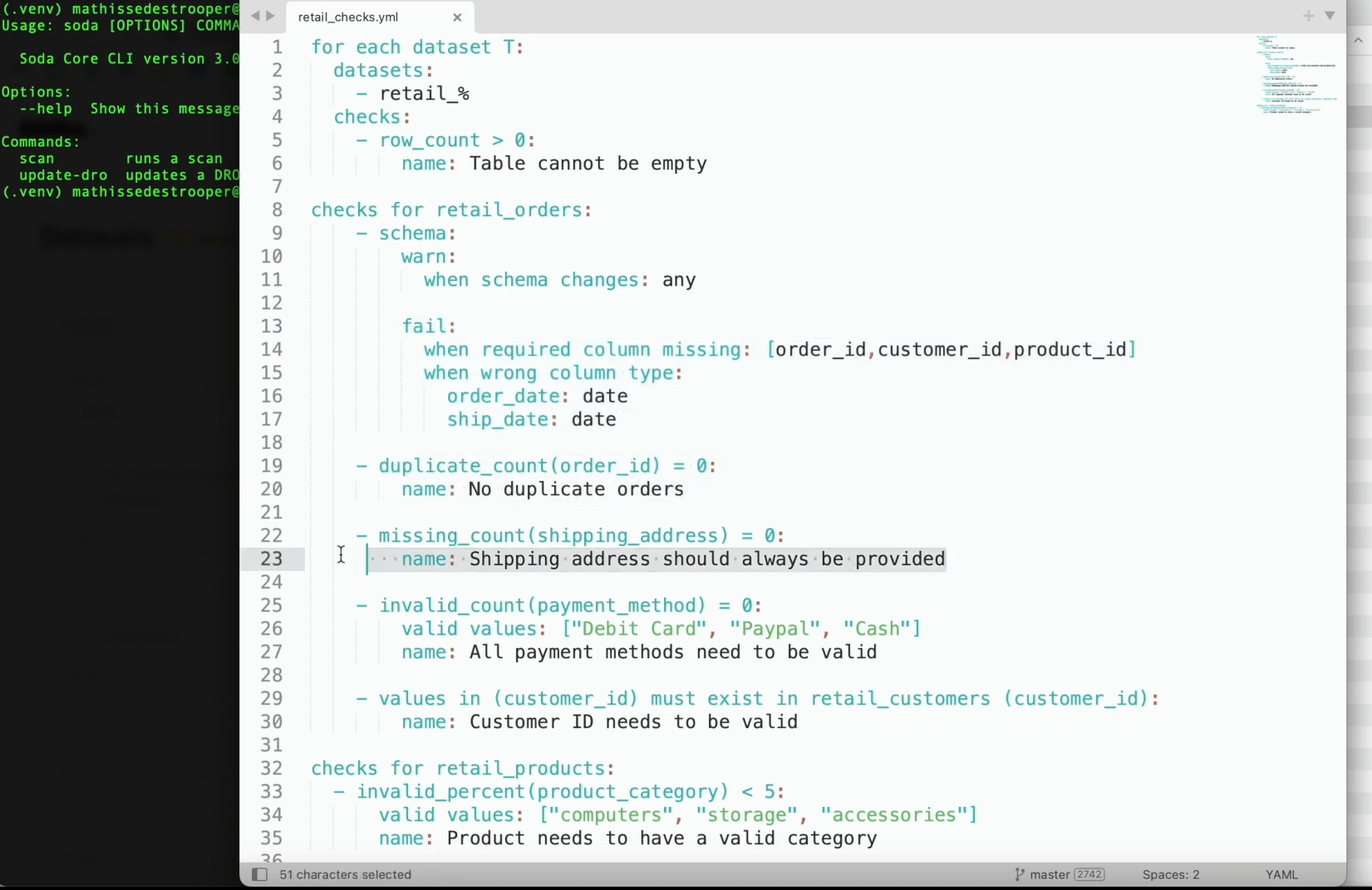
The software makes it relatively simple to implement a variety of checks. For example, it could flag a database if there are columns missing, or if the wrong column type is used. It can detect and alert on duplicate entries in the database. It can even sound the alarm when there are missing values in the database for shipping address or payment details.
There are about 30 or so metrics and check types in SodaCL today, but the company anticipates that number will grow over time to address specific business domains with specific data issues, such as asset management, supply chain, and customer data, the company says. SodaCL’s syntax is human readable, which will “allow everyone on the data team to define thresholds of what good data needs to look like,” the company says.
Soda Core allows user to set alerts either manually or dynamically. For example, the product may trigger when a certain percentage of tables have errors, such as 5% invalid entries, according to Soda’s video. To execute a scan, a user builds up the specific commands created with SodaCL, and executives it.
Alerts and notifications can also be created using the customers’ own ticketing system. Using Soda Core with Soda Cloud enables “notifications [to] be routed through to the right people, enabling less technical users to get involved by adjusting thresholds or adding new checks altogether,” the Brussels-based company says.
Baeyens says the first public release of Soda Core and SodaCL is one of the most important milestones in the company’s journey so far.
“We realized early on that when it comes to data quality, the needs of engineers are quite different when compared with the needs of the data team as a whole,” the CTO says in a press release. “A lot of people in a data team know what good data looks like, but only a few can code the checks. With our releases today, we are providing the tools to remove the bottlenecks that exist around coding data reliability, enabling Data Engineers to build data quality checks-as-code directly into their pipelines and fundamentally change how teams set up and maintain reliable, high-quality data products.”
Soda Core has designed to scan AWS‘ Amazon Athena; Amazon Redshift; Google Cloud Big Query; PostgreSQL; and Snowflake databases. For more info, see www.soda.io.
Related Items:
In Search of the Data Dream Team
VCs Open Up the Checkbook for Observability Startups
Soda Launches Open Data Monitoring
Applications:
Enterprise Analytics
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States