

June 30, 2022
Databricks Scores ACM SIGMOD Awards for Spark and Photon
Databricks announced it has won two awards at the ACM SIGMOD (Association of Computing Machinery’s Special Interest Group in the Management of Data) Conference in Philadelphia.
Apache Spark was awarded the SIGMOD Systems Award, and Databricks Photon was awarded the Best Industry Paper Award.
ACM SIGMOD describes its annual conference as a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools, and experiences in the field of data management.
Each year, the SIGMOD Systems Award is presented to a “system whose technical contributions have had significant impact on the theory or practice of large-scale data management systems.” The award includes a plaque and a $10,000 prize, and past recipients include Postgres, SQLite, BerkelyDB, and Aurora.
 In a blog post, Databricks Co-Founders Reynold Xin and Matei Zaharia tell of how Apache Spark was conceived in 2009 by PhD students from UC Berkely, including Zaharia. They were competing in a Netflix competition with a $1 million prize up for grabs for the best machine learning model for predicting how users would rate movies on the platform. After realizing they lacked the proper tools for working with the large amounts of unstructured data involved, the Berkeley team designed Spark, an entirely new parallel computing framework with a distributed data structure. Xin and Zaharia write that the new framework “enabled its users to run data parallel operations quickly and concisely” because “it’s fast to write code in and fast to run. ‘Fast to write’ is important because it makes the program more understandable and can be used to compose more complex algorithms easily. ‘Fast to run’ means users can get feedback faster and build their models using ever-growing data.”
In a blog post, Databricks Co-Founders Reynold Xin and Matei Zaharia tell of how Apache Spark was conceived in 2009 by PhD students from UC Berkely, including Zaharia. They were competing in a Netflix competition with a $1 million prize up for grabs for the best machine learning model for predicting how users would rate movies on the platform. After realizing they lacked the proper tools for working with the large amounts of unstructured data involved, the Berkeley team designed Spark, an entirely new parallel computing framework with a distributed data structure. Xin and Zaharia write that the new framework “enabled its users to run data parallel operations quickly and concisely” because “it’s fast to write code in and fast to run. ‘Fast to write’ is important because it makes the program more understandable and can be used to compose more complex algorithms easily. ‘Fast to run’ means users can get feedback faster and build their models using ever-growing data.”
Spark has now been downloaded 45 million times in the last month alone and is used in 204 countries and regions, and Databricks says its SIGMOD Systems Award is a validation of the project’s adoption and influence.
The Best Industry Paper Award is an annual award presented to one paper based on its real-world impact, innovation, and quality of presentation.
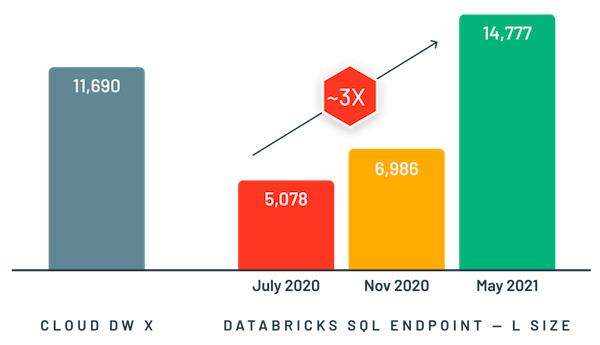
Photon’s benchmark results for 10 GB TPC-DS Queries/Hr at 32 Concurrent Streams (Higher is better). Source: Databricks
Photon is a C++ vectorized execution engine for Spark and SQL workloads that runs behind existing Spark programming interfaces. It was born from the desire Spark users had “to run traditional interactive data warehousing applications on the same datasets they were using elsewhere in their business, eliminating the need to manage multiple data systems. This led to the concept of lakehouse systems: a single data store that can do large-scale processing and interactive SQL queries, combining the benefits of data warehouse and data lake systems.” Photon was developed to support this lakehouse approach as it allows faster interactive queries and higher concurrency than Spark while supporting APIs like SQL, Python, and Java.
The winning paper, titled “Photon: A Fast Query Engine for Lakehouse Systems,” describes how Photon was designed, how it is integrated with SQL and Spark, and how it has accelerated some workloads by 10x or more to set a data warehousing performance record. The paper details the challenges the developers faced in their efforts to support a wide range of applications in a lakehouse environment while maintaining speed and performance.
Databricks recently announced a public preview of Photon focused on running SQL workloads faster and with less total cost. Users can preview Photon as the default query engine on Databricks SQL or as part of a new high performance runtime on Databricks clusters.
Related Items:
Data Lake or Warehouse? Databricks Offers a Third Way
Spark Gets Closer Hooks to Pandas, SQL with Version 3.2
Databricks Cranks Delta Lake Performance, Nabs Redash for SQL Viz
Technologies:
Frameworks
Sectors:
Academia
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States