

May 19, 2022
Data Centralization Is Necessary. So Why Is It Still So Hard?

(Shutterstock)
When it comes to big data analytics, there are some questions that can’t be answered without loading it all into one central location and running queries against it. There’s just no practical way around it, which is why data pipelines in the cloud continue to be major area of investment. But effectively managing all this data as it flows through pipelines continues to be extremely difficult, even for some of the most sophisticated tech firms on the planet.
Take Workday, for example. About 9,500 mid-to-large companies around the world rely on the Pleasanton, California company to provide HR and financial software as a service (SaaS). The company, which had more than $5 billion in revenues last year, is widely considered to be the enterprise leader in software for managing people and money.
Workday’s internal application and data controls are top notch, as you would expect when dealing with the private personnel and financial information of the world’s largest companies. When it comes to data, the company essentially takes a walled garden approach to maintaining security, quality, and integrity within its own systems. It’s a similar story with the application itself–customers are free to configure their applications using Workday’s metadata-based approach, but there are no source code modifications that would eventually cause compatibility issues and complications down the road.
This locked-down SaaS approach has worked very well for the past 16 years, says Workday Chief Technology Officer Jim Stratton.
“A core tenet of what we do is everybody is running on the same version of Workday everywhere globally. We update our applications every week for every customer everywhere,” Stratton says. “What that means is everybody globally for all of our 9,500 customers or so are all on the same structure of data.”
If Stratton had his druthers, customers would never extract their Workday data and move it out of the well-protected and managed environment. Instead, they would bring any external data they want to mix with their Workday data into the Workday environment for analysis. That would ensure the utmost freshness, integrity, and value of the Workday data, which after all is the company’s primary goal.

(Cienpies Design/Shutterstock)
While the walled garden approach will work in some situations, it’s a non-starter for most applications in the real world, and Workday knows it. Stratton realizes that very few customers would be willing to bring all of their relevant data and load it into Workday. The CTOs at other SaaS companies–the Salesforces, ServiceNows, NetSuites, and Zendesks of the world–probably have the same view.
“I do think there’s lot of value, if you’re talking about people and finance data, to keep it within the security confines of what you’re doing, because you have to do a lot of workarounds and extra work to try to maintain security of that data once you pull it out of those data systems,” Stratton says. “But the reality is, if you’re trying to do analytics across sales data and your people data and your manufacturing data, you’re going to have to move it into a centralized system. No one of those systems is going to do all of that.”
When it comes to Workday’s own HR and finance needs, the company eats its own dogfood. But when it comes to everything else outside of that core competency, the company is like any other firm: it contracts with SaaS vendors to provide reliable enterprise application functionality. And when it comes to data analytics that require those other data, Workday does what most other firms do: It extracts the relevant data and loads it into a data lake. In Workday’s case, the lake of choice is AWS and the analytic tool is Tableau.
Stratton, who also has responsibility for the back-office systems that help Workday run on a daily basis, is aware of the risks that comes with moving sensitive data out of its own Workday implementation, or its Salesforce or ServiceNow implementations, for that matter.

Jim Stratton is the CTO at Workday
“There is a lot of value to doing it natively locally,” he says. “We’re 100% consistent all the time of the data that lives within Workday. As soon as you go outside the walls of that, you’re no longer consistent with the source of truth for that. And that’s true for any of those. It’s true for Salesforce, it’s true for manufacturing or ServiceNow data. As soon as you make a copy of that and dump it into your data lake, it’s out of date and it’s not secure anymore.”
Workday gives its customers full unfettered access to their data, and ships a suite of APIs for accessing the internal data, and connectors for shipping it to external repositories, such as Snowflake, AWS, and Google Cloud. Enabling that external data access has been a focus of the company since it was founded, Stratton says.
For its own operations, keeping its own Workday data fresh and secure when it leaves the comfy confines and splashes into its AWS data lake is a constant challenge. Maintaining data security, provenance, quality, and access control is just hard, Stratton says. The company is currently in the process of changing its governance tool provider because its current vendor’s roadmap is diverging from Workday’s needs, the CTO says.
Despite the fact that we’ve all been living in the age of big data for the past decade, Stratton hasn’t seen much improvement in data integration as it occurs on the ground.
“The data pipeline problem, regardless of what it is, is always a thing, and I’m not sure it’s ever going away,” he says. “The quality of the data, the consistency of the data, the governance of it, the security controls around it–it’s a big lift, always. And I haven’t seen that get any better with all of the advances of technology. I’ve been at Workday for almost 10 years, and it’s not a lot better in terms of the quality of data flow and the amount of work it takes to make sure that the data is there, correct, and secure. It’s about the same as it was 10 years ago.”
The problem isn’t due to technological limitations, Stratton says, but rather the ownership of the data.
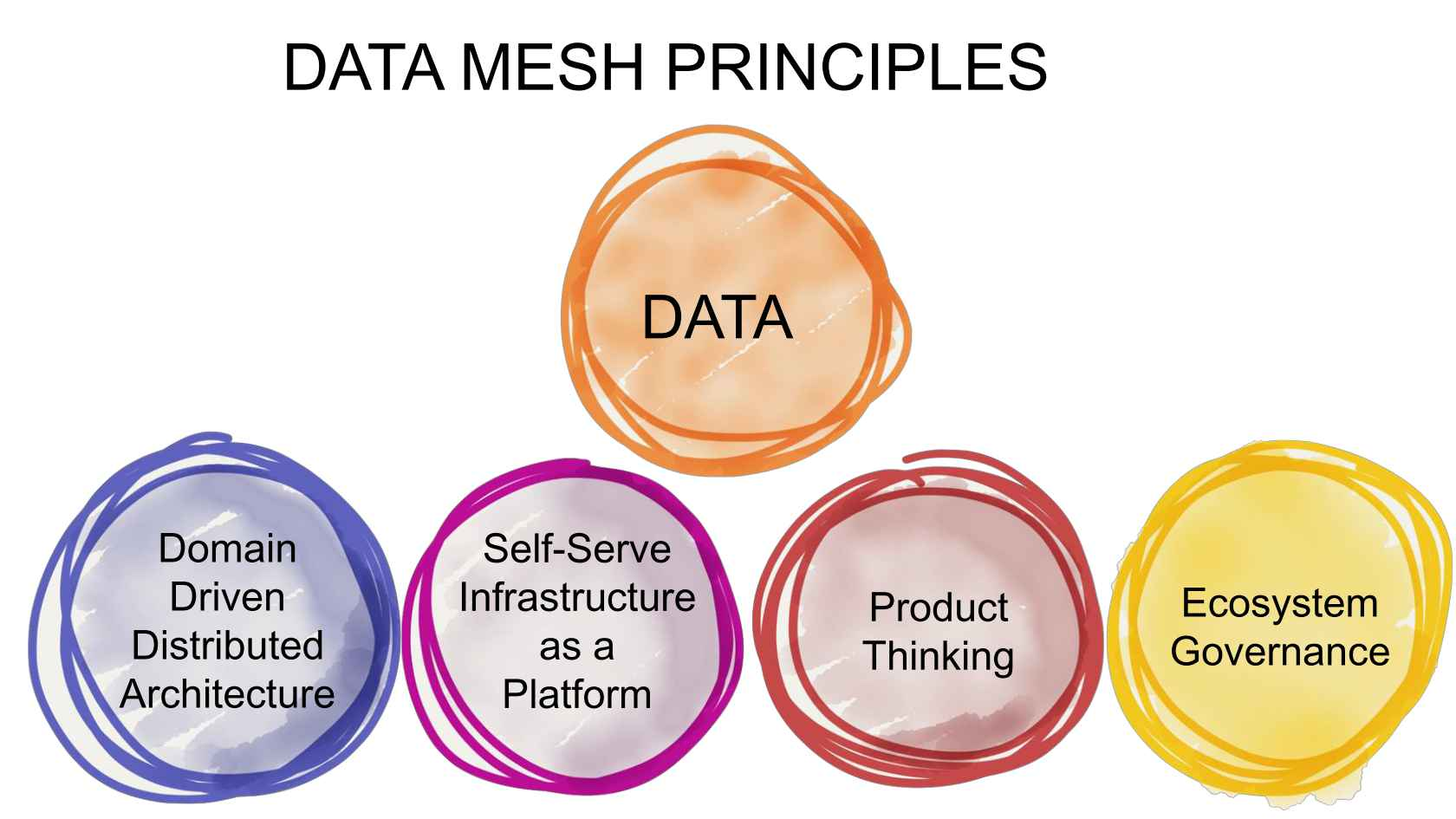
(Image courtesy Zhamak Dehghani)
“From customer data that we serve up to the customers, we’re very good at that. We’re very mature at that,” he says. “But it’s the internal systems data and our own analytics data that [requires] a change in mindset and a change in culture within the company to get good at that.”
Stratton sees a potential solution in data mesh. The data mesh concept, which was conceived by 2022 Datanami Person to Watch Zhamak Dehghani, provides a guide for decentralized management of data, with a heavy emphasis on empowering independent teams to take ownership of data against a federated data governance model.
“I think it comes down to that, data product ownership,” Stratton says. “It’s a culture and a mindset and staffing of, there’s somebody sitting on that data pipeline that understands what that data is, what the structure should be, what good data looks like and they’re watching to see if all the bits go from Point A to Point B and make it there.
“I think that’s the biggest part that’s broken,” he continues. “We kind of set up the pipes, and then assume that they’re always going to work. And we don’t realize until further downstream, further in time, that something is broke and we got to work our way back up.”
In a way, it may be heartening for a data manager at a mid-sized company to hear that an outfit as large and sophisticated as Workday also struggles to run its data pipelines. On the other hand, the fact that even a company as large and sophisticated as Workday hasn’t been able to solve the data pipeline conundrum up to this point could cause despair.
In any event, Stratton has hope that data mesh, if implemented correctly, could elevate his company and other large enterprises beyond the whack-a-mole game that data integration currently resembles. While Stratton hasn’t seen too many companies succeed with the new data mesh approach at this point, it’s a reason for optimism. We’ll take it.
Related Items:
Data Mesh Vs. Data Fabric: Understanding the Differences
To Centralize or Not to Centralize Your Data–That Is the Question
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States