

May 9, 2022
Ocient Emerges with NVMe-Powered Exascale Data Warehouse

(ALPAL-images/Shutterstock)
There’s only about 1,000 organizations in the world with exascale data analytics problems currently, but Chris Gladwin, the CEO and co-founder of Ocient, knows who most of them are. In the coming months, the tech entrepreneur and his team will be calling on many of them to gauge their interest in Ocient’s new data warehouse, which leverages the massive I/O throughput of NVMe drives to query gargantuan data sets approaching an exabyte in scale.
Gladwin founded Ocient in 2016 with the premise that the current generation of data warehouses were insufficient to query truly large datasets. As the founder of the storage company Cleversafe, which was sold to IBM in 2015 for $1.5 billion, Gladwin was familiar with big data storage challenges. But the architecture for system capable of querying 10s to 100s of petabytes at reasonable latencies would be very different than the S3-compatible object data stores like Cleversafe that form the basis for data lakes today.
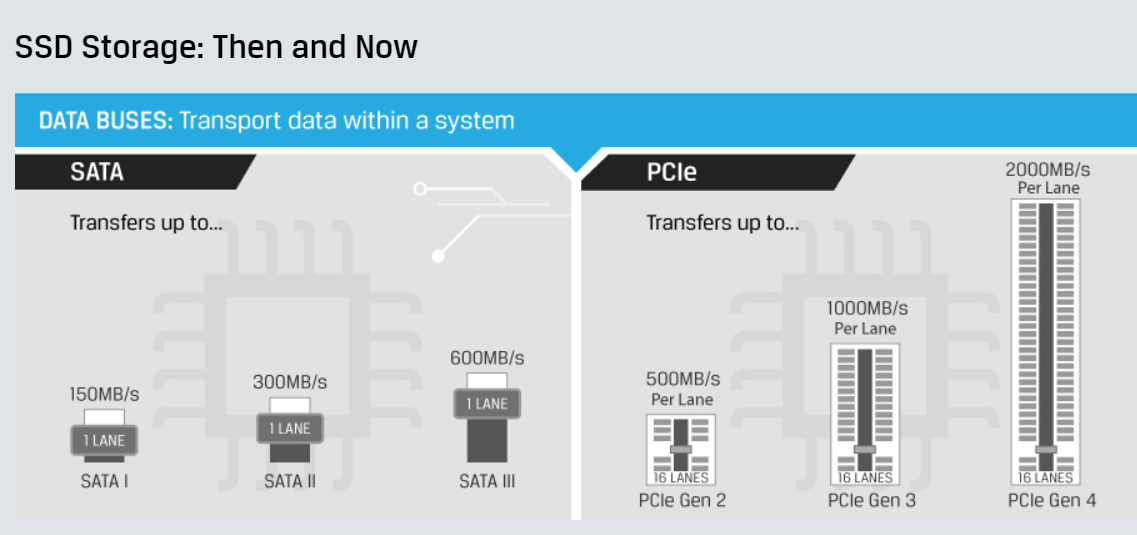
The big change enabling exa-scale analytics is the introduction of affordable NVMe drives, which is a game-changer for analytics at this scale, Gladwin says.
“The issue with spinning disk primarily is that their speed has not changed in decades,” he tells Datanami in an interview. “The speed at which you can do random reads or random writes…is at the end of the day what limits how fast your database is going to go for this kind of hyperscale analysis.”
Currently, spinning disks can yield about 500 random 4KB block reads per second, a number that hasn’t changed in decades, Gladwin says. Today’s NVMe solid state drives, on the other hand, can deliver 1 million random 4KB block reads per second, he says.
(Graphic courtesy Kingston)
“You can take an old database architecture and set it on it NVMe, and it’ll go maybe 10 times faster, maybe 50 times faster, which is amazing,” Gladwin says. “But divide 1 million by 500, it should go 2,000 times faster. So you’re leaving a couple orders of magnitude on the table. Even though it’s going 20 times faster, it should be going 100 times faster than that.”
In order to eek out that extra 200x performance boost, Gladwin had to build a new database from scratch. The key element was to parallelize as much of the database’s architecture as possible to take advantage of the massive parallelization inherent in the NVMe drives, which can not only move data at 1 million IOPS but also support up to 256 independent lanes per drive (with 512 lanes and 1,000+ lane drives on the horizon) on the PCIe Gen4 bus.
“If we do our job right as software architects and software developers, we’re going to go as fast as the hardware can go,” Gladwin says. “To get all that performance out of a solid state drive, one of the things you have to do is create this ability to put 256, going on 1,000, parallel tasks into these drives many thousand times a second, and that actually is not that easy.”
Ocient created a piece of software called Mega Lane that’s designed to pull data from the parallel PCIe lanes, get them into the NVMe drives, and get the results back as quickly as possible. Mega Lane required Ocient to tweak the firmware in the NVMe drives, as well as working in the L1, L2, and L3 caches on the motherboard, “and just make sure everything is flowing as fast as it can flow,” Gladwin says.
“A lot of times people think, oh, you know, giant data analyses — it’s all about the CPU crunching things. It’s really not,” he continues. “It’s about how fast you can flow things through the system. So it’s like a flow control. So that’s one of the things that we have to do with that Mega Lane architecture that enables us to realize this performance.”
While much of the advanced analytics world has settled on the separation of compute and storage as a core tenet of scalability, Gladwin is taking the opposite approach and consolidating as much of the stack as possible. It’s ironic, in a way, since Gladwin was one of the early promoters of object stores at Cleversafe, which today forms the basis of IBM’s cloud object storage system. In fact, as part of last week’s announcement, Ocient introduced its compute adjacent storage architecture (CASA), which brings storage and compute together.
Ocient relies on NVMe drives both for the storage and for database analysis. In other words, there is no secondary tier of data, such as an S3 store, that the database is pulling data from. Ocient does borrow from object storage systems by leveraging erasure coding to protect data without the heavy overhead (triple replication) typical in classical database architectures.![]()
The key advantage of combining primary and analytical storage, Gladwin says, is it eliminates the need to move data across the network, which simply adds too much latency for analytics at this scale.
“Instead of 1,500 microseconds [latency for 100 GbE], the latency in our case is 100 microseconds, so it’s one-fifteenth the latency,” he says. “And instead of 100 Gb per second connections, it’s terabits per second of data that we can flow between the two. So we generally get about 15 times the bandwidth at one-fifteenth the latency. It’s just going to go faster, right? Unless we screw it up.”
But unforeseen issues did crop up. For example, to enable customers to actually move tens of petabytes of data from a data source into the database at a reasonable speed, a new ETL system was necessary. Gladwin didn’t set out to write a new ETL service, but as the requirements came in for the new hyperscale database (the company is funded in part by In-Q-Tel), it became clear that it would be necessary.
“We initially said, we’re going to write a new data warehouse, full-stack, from the memory allocators all the way through the application layer where needed,” Gladwin says. “We also ended up writing a whole new hyperscale extract, transform, and load service. The main reason we did that is because we had to. There was nothing out there that that had the properties we needed, particularly at this scale, to deliver linear performance.”
If you want 10 times or 100 times the throughput, you need to have 10 times or 100 times the number of loaders, Gladwin says. “What that required was a stateless, distributed loading architecture that you could cluster, and it just didn’t exist,” he says.

Chris Gladwin is the co-founder and CEO of Ocient
The Ocient data warehouse is actually two databases in one. Upon ingest, data is stored in a row store, where it’s transformed and prepared for analysis in the column store (which is better suited for the types of aggregations common in data analytics).
Ocient has backers in the intelligence community, but other early adopters are ad tech firms that crunch data from the 10 million digital auctions occurring every second in the world. According to Gladwin, these customers need the capability to ingest and query 100,000 JSON documents per second.
“These are large, semi-structured, complex documents that are hitting the front door 100,000 times a second,” he says. “So we have to unwrap those, get them from this semi-structured slightly messy JSON format into a relational schema, get it indexed, get a secondary index, get it reliable, and get it showing up in queries, and we’re able to do that at that speed in seconds.
“We’re not aware of anybody else that can do that,” Gladwin continues. “And then to do that at the same time that on that system, while all this data is pouring in, at the same time these giant queries are executing with concurrency and trillions of things every second at the same time — I’m not aware of anybody else that can both of those.”
Telecommunication firms have also been the early adopters for Ocient, which provides ANSI SQL support on a variety of data types, with geospatial next on the to-do list. As telecoms invest trillions of dollars to build the 5G network, they’re finding a need for higher resolution detail about the current state of their 3G or 4G networks, which will keep demand high in that sector.
Organizations had few good options for hyperscale analytics before solid state NVMe drives became cost-effective, Gladwin says. In some cases, that means the analytics simply didn’t get done. In other cases, it meant dealing with longer latencies than ideal.
“Sometimes they’ll run it on Hadoop and they’ll just deal with the fact that it takes a couple hours or come back tomorrow,” Gladwin says. “You could buy an exabyte of DRAM and then wrap it inside a gigantically expensive supercomputer. Yeah, that’s possible, but not feasible.”
Some of Ocient’s customers would rather the company didn’t talk about what it’s done, which is perhaps why the company is releasing version 19 of its database but only recently hired somebody to do marketing. To be sure, Gladwin won’t be discussing some of his customers, particularly in the intelligence field. In any event, there are some customers today that are approaching data warehouses with an exabytes of data.
“Right now, we’re kind of in the petabytes to tens of petabyte scale in terms of active use, with plans and intentions to get into the hundreds of petabytes and exabyte range,” he says. “We are actively aware of some exabytes scale.”
Being at the uber high end does have its advantages, but having a broad total addressable market is not one of them.
“There’s just not that many companies that need hyperscale,” Gladwin says. “Humans don’t type that much stuff. So it’s either you got a bunch of routers, you got 100 million mobile phones, or you’ve got a million sensors. There’s only so many ways you can have this data, and we think we know them all. Sometimes we learn about new ones. But yeah, we’re focused on kind of a smaller number.”
Ocient is available on AWS and GCP, as a managed service, or on-prem. For more information, see www.ocient.com.
Related Items:
IBM Challenges Amazon S3 with Cloud Object Store
Peering Into Computing’s Exascale Future with the IEEE
How to Move 80PB Without Downtime
Applications:
Enterprise Analytics
Technologies:
Storage
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States