

May 5, 2022
Galileo Emerges from Stealth with Collaborative MLOps Platform

There’s a new player in the hot MLOps market: Galileo. Founded by Google and Uber AI alumni, the company emerged from stealth this week with $5.1 million in seed funding.
Galileo is an intelligence platform for unstructured data, and the company claims it can help data scientists find and correct “critical ML data errors 10x faster across the entire ML lifecycle–from pre-training to post-training to post-production.”
A major obstruction in AI model training is the need for inspecting and fixing the data used for training, as much of it is unstructured (e.g., text, image or speech), and data scientists must use Python and spreadsheets to identify and amend errors in data. This process takes up valuable time, is less transparent, and could cause biased and erroneous production models.
“The motivation for Galileo came from our personal experiences at Apple, Google and Uber AI and from conversations with hundreds of ML teams working with unstructured data where we noticed that, while they have a long list of model-focused MLOps tools to choose from, the biggest bottleneck and time sink for high quality ML is always around fixing the data they work with. This is critical, but prohibitively manual, ad-hoc and slow, leading to poor model predictions and avoidable model biases creeping into production for the business,” said Vikram Chatterji, co-founder and CEO of Galileo. “With unstructured data across the enterprise being generated at an unprecedented scale and now rapidly leveraged for ML, we are building Galileo with the goal of being the intelligent data bench for data scientists to systematically and quickly inspect, fix and track their ML data in one place.”
![]() Chatterji, formerly a product management lead at Google AI, co-founded Galileo with Atindriyo Sanyal, a senior software engineer formerly at Apple and Uber AI, and Yash Sheth, a former Google software engineer. All three had experience with ML using unstructured data. At Google AI, Chatterji experienced the slow and expensive process of model training while spending weeks analyzing data across his ML workflow. Sanyal was a co-architect of Uber’s feature store and was also an early member of Apple’s Siri team, and in both cases was instrumental in building ML data quality tools and infrastructure. Sheth ran Google’s speech recognition platform and gained experience with unstructured speech data to build and promote its cloud speech API.
Chatterji, formerly a product management lead at Google AI, co-founded Galileo with Atindriyo Sanyal, a senior software engineer formerly at Apple and Uber AI, and Yash Sheth, a former Google software engineer. All three had experience with ML using unstructured data. At Google AI, Chatterji experienced the slow and expensive process of model training while spending weeks analyzing data across his ML workflow. Sanyal was a co-architect of Uber’s feature store and was also an early member of Apple’s Siri team, and in both cases was instrumental in building ML data quality tools and infrastructure. Sheth ran Google’s speech recognition platform and gained experience with unstructured speech data to build and promote its cloud speech API.
Galileo says its approach is unique, and “with just a few lines of code added by the data scientist while training a model, Galileo auto-logs the data, leverages some advanced statistical algorithms the team has created and then intelligently surfaces the model’s failure points with actions and integrations to immediately fix them, all within one platform. This short circuits the time taken to proactively find critical errors in ML data across training and production models from weeks today to minutes with Galileo.”
Calling its platform “a collaborative system of record,” for model training, Galileo says it brings transparency to the process through its ability to show how specific data and model parameter changes impact overall performance.
“It is common knowledge that we often get larger gains in our model performance by improving the quality of data rather than by tuning the model. Data errors can creep into your datasets to cause catastrophic repercussions in many ways,” said the founders in a company blog post.
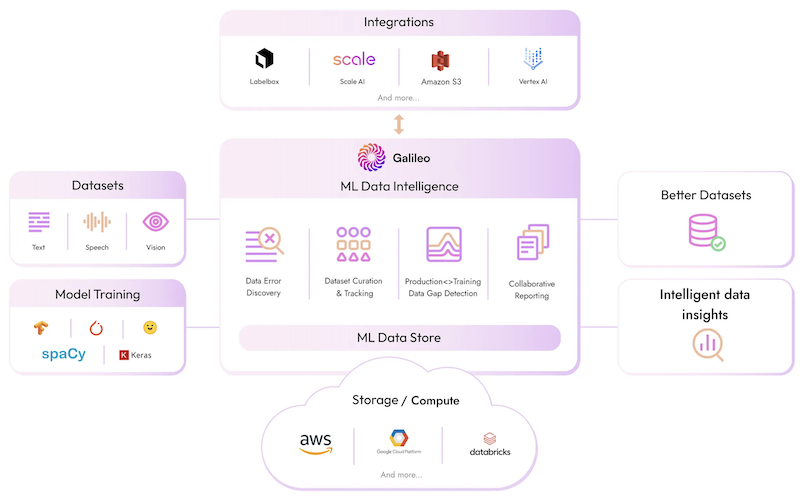
A graphic showing how Galileo fits into the ML workflow. Source: Galileo
These errors occur in several forms. Sampling errors can arise from ineffective data curation, and blind spots can occur in modeling if data scientists overlook important aspects of their data, which the Galileo founders say are “looking at the right data sources, [having] a good feature-mix, avoiding garbage samples, ensuring data generalizability and much more.”
Labeling errors of human or synthetic origin are also common, and since labeled datasets are often reused for long periods of time due to the high cost of labeling, models launched with labeling errors are seldom retrained with fresh, correctly labeled data. “This leads to the model serving new/unseen traffic in production, causing ML teams to be reactive to customer complaints due to model mispredictions, caused by data staleness and the inability to proactively train with the right training data,” said Galileo’s founders.
The founders want the collaborative nature of Galileo’s platform to empower each person in the ML workflow, from sales engineers having to manually fix a customer’s data dump, to data scientists fixing training model data, and from subject matter experts looking at data errors to provide expert opinions on next steps, to PM and engineering leaders keeping track of ROI on data procurement and annotation costs.
This week’s $5.1 million in seed funding was led by The Factory with participation from other investors including Anthony Goldbloom, the founder and CEO of ML and data science coding community Kaggle. Included in the company advisors is Pete Warden, co-creator of Tensorflow.
“Finding and fixing data errors is one of the biggest impediments for effective ML across the enterprise. The founders of Galileo felt this pain themselves while leading ML products at Apple, Google and Uber,” said Andy Jacques, investor at The Factory and Galileo board member. “Galileo has built an incredible team, made product innovations across the stack, and created a first of its kind ML data intelligence platform. It has been exciting to see rapid market adoption and positive reactions with one of the customers even calling the product ‘magic’!”
Related Items:
Birds Aren’t Real. And Neither Is MLOps
A ‘Glut’ of Innovation Spotted in Data Science and ML Platforms
A ‘Breakout Year’ for ModelOps, Forrester Says
Vendors:
Galileo
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States