

April 22, 2022
Google’s Massive New Language Model Can Explain Jokes

(achinthamb/Shutterstock)
Nearly two years ago, OpenAI’s 175 billion-parameter GPT-3 language model opened the world’s eyes to what large language models (LLMs) could accomplish with relatively little input, sensibly answering questions, translating text, and even generating its own pieces of creative writing. GPT-3’s success in few-shot learning was itself succeeded by models like Google’s LaMDA (137 billion parameters) and Megatron-Turing NLG (530 billion parameters). Now, Google has introduced a new large language model: the Pathways Language Model (PaLM), a 540 billion-parameter Transformer model trained on Google’s new Pathways system.
Back in October, Jeff Dean—senior vice president of Google Research—introduced Pathways as “a next-generation AI architecture” that would enable developers to “train a single model to do thousands or millions of things,” versus just one thing.
“[We]d] like to train one model that can not only handle many separate tasks, but also draw upon and combine its existing skills to learn new tasks faster and more effectively,” Dean wrote in a blog. “That way what a model learns by training on one task—say, learning how aerial images can predict the elevation of a landscape—could help it learn another task—say, predicting how flood waters will flow through that terrain.”
Since then, Pathways has taken more concrete shape, and PaLM appears to be some of the earliest fruit of those labors. Google said that PaLM “demonstrates the first large-scale use of the Pathways system to scale training to … the largest TPU-based system configuration used for training to date.” That training, conducted across multiple Cloud TPU v4 Pods, scaled to 6,144 chips.
“This is a significant increase in scale compared to most previous LLMs,” Google Research wrote, “which were either trained on a single TPU v3 Pod (e.g., GLaM, LaMDA), used pipeline parallelism to scale to 2240 A100 GPUs across GPU clusters (Megatron-Turing NLG) or used multiple TPU v3 Pods (Gopher) with a maximum scale of 4096 TPU v3 chips.” Google said that PaLM achieved a training efficiency of 57.8% hardware flops utilization, which it says is the highest achieved by an LLM of this scale to date.
Google reported that PaLM—which was trained using a combination of English and multilingual datasets—showed “breakthrough capabilities on numerous very difficult tasks,” surpassing the performance of models like GPT-3, LaMDA, and Megatron-Turning NLG on 28 of 29 tasks that ranged from question-answering to sentence-completion.
Going into more detail, the company said that PaLM “can distinguish cause and effect, understand conceptual combinations in appropriate contexts, and even guess the movie from an emoji.” PaLM also showed proficiency in non-English languages, coding, and arithmetic tasks.
Google even showcased an astonishing example of PaLM explaining an original joke.
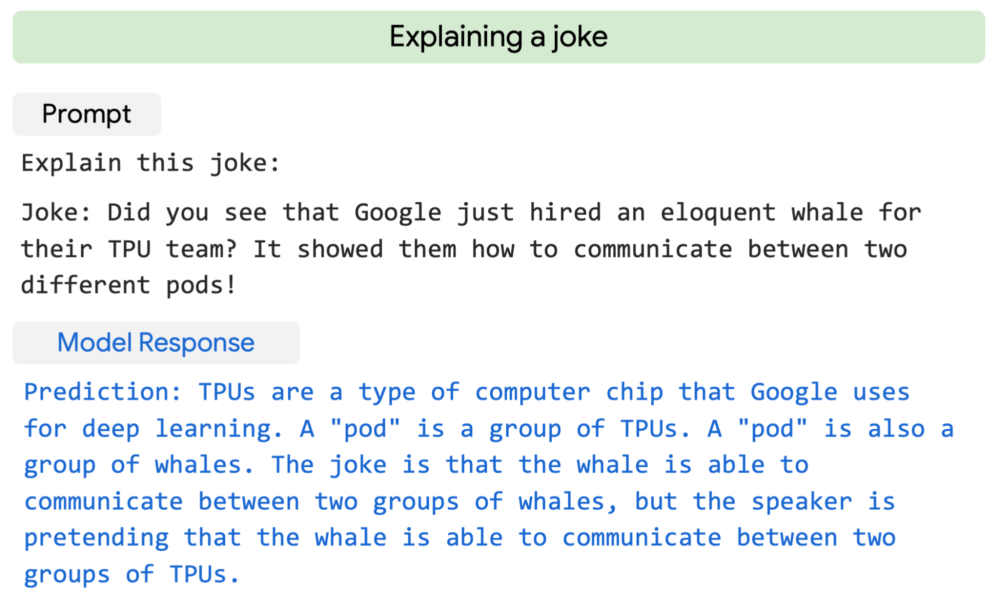
Google’s PaLM large language model explaining an original joke that is not otherwise found on the internet. Image courtesy of Google.
Given the capabilities of PaLM, Google includes a note on ethical considerations for large language models, which are a subject of great interest and concern among AI ethics researchers. “While the analysis helps outline some potential risks of the model, domain- and task-specific analysis is essential to truly calibrate, contextualize, and mitigate possible harms,” the researchers wrote. “Further understanding of risks and benefits of these models is a topic of ongoing research, together with developing scalable solutions that can put guardrails against malicious uses of language models.” (To read more about the ethical implications of large language models, read some prior coverage from Datanami here.)
Google closed by noting that PaLM’s development brings the company closer to the vision for the Pathways architecture: to enable a single AI system to generalize across thousands or millions of tasks, to understand different types of data, and to do so with remarkable efficiency.
Related Items
AI Experts Discuss Implications of GPT-3
Experts Disagree on the Utility of Large Language Models
Mantium Lowers the Barrier to Using Large Language Models
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States