

March 28, 2022
Can Streaming Graphs Clean Up the Data Pipeline Mess?

(Blue Planet Studio/Shutterstock)
The previously separate worlds of graph databases and streaming data are coming together in an open source project called Quine. According to its creator, the Akka-based distributed framework is capable of returning Cypher queries on flowing data at the rate of a million events per second, which he says could eliminate the need to build and maintain elaborate data pipelines.
You could say that Ryan Wright has a love-hate relationship with data pipelines. As the head of multiple data engineering and data science teams over the years, he has developed more than his share of them to enable his teams to query data on large amounts of real-time data.
“They’re technically possible to build,” says Wright, who is the CEO of thatDot, the Portland, Oregon-based company he founded to commercialize Quine. “A smart team of dozens of software engineers can build one of those pipelines in nine to 18 months. And that’s great. Then you can scale it, you can stream it. That’s the state of the art right now.”
But the thing about data pipelines is they’re typically custom entities. They are notoriously brittle and tough to maintain, which means you’re pretty much out of luck if the original data engineers who built it leave the organization. All that building and re-building of data pipelines can get old, and is what drove Wright to think of a new approach to getting answers from fast-moving data, and ultimately to create Quine.

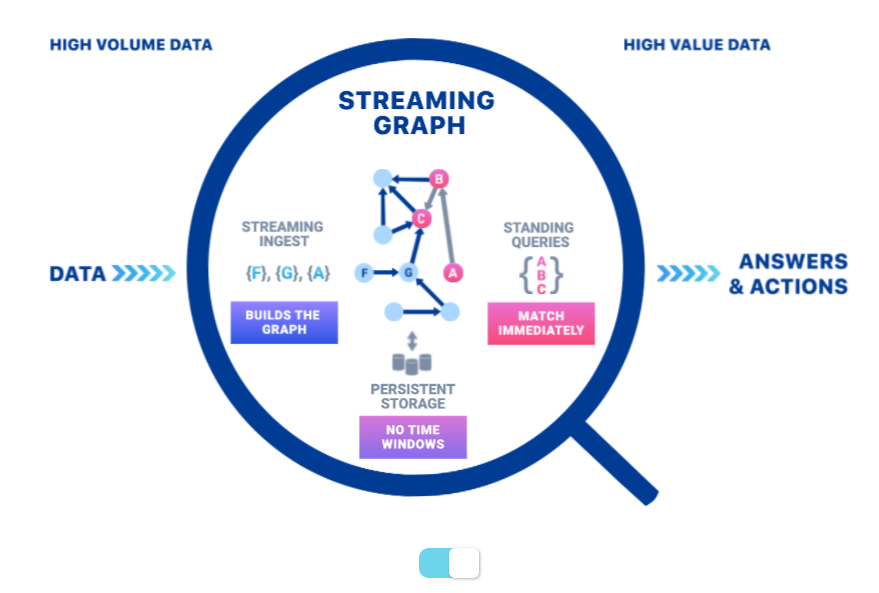
Quine’s novel architecture is designed to speed processing of connected data (Image source: Quine whitepaper “A Streaming Graph System For High-Volume Complex Event Processing“)
“The more data pipelines you build, the more they start looking like the same thing,” Wright says. “And you have to start wondering: How do we solve the higher-level question so we don’t have to keep rebuilding the same pipelines over and over again?”
Graphing Real-Time Connections
Wright looked at other real-time data processing frameworks, but they carried significant tradeoffs, especially when working with stateful data. For example, the capability to match one event from a data stream with another event from the same stream within an arbitrary time window sounds like it should be feasible, but modern frameworks bump up against hardware constraints, he says.
“Maybe you’ve got two streams that are coming together and that’s where you’re trying to join these two streams and process them there,” Wright says. “Or even if you’re just looking at one stream, and you need to plunk out an A early in the stream and a B a little later, so that you put A and B together. If you need to join that kind of data, then the modern state of the art is you are confined by how much RAM you have on the machine. That’s how many As you can hold onto while waiting for a B to arrive.
“And so that forces all these data engineers to set artificial time windows to say I’m going to join As and Bs together if the A and B arrived within 30 seconds of each other. But if they arrive 45 seconds from each other, then we just have to drop them. We can’t hold on to it,” he continues. “And so that’s the tradeoff that data engineers just accept, and say ‘Well, if my data is too far away from each other, I just lose it and that’s just the world we live in.’”
But in the world Wright inhabits, that answer just didn’t fly. So he set out to find a better way to process large amounts of real-time event data in a stateful manner. He looked to graph database, which are naturally designed to link similar data. But he discovered they had one fatal flaw: they are just too slow.
“The challenge has always been that graphs are slow,” Wright tells Datanami. “If you have kind of the typical streaming problem of a high write and read workload–so you’re not just writing it to disk, you’ve got to write it and read it back so you can use stream processing on it–then [a graph database] just slows to a crawl and goes from several thousands of events per second that they can usually reach down to like 1,000 a second.”
One of Wright’s prospects told him that his data problem starts at 250,000 events per second. If he could somehow push graph’s capability forward a couple orders of magnitude–if he could solve graph’s notoriously slow data writing time and enable graph queries to be processed on data as it flows by–then maybe they could talk.
But how would he do it? “That’s the million-dollar question,” he says.
Acting On a Hunch
To complete his vision of a streaming graph, Wright looked to the past. In fact, he went back 50 years to the genesis of something called the actor model of computing, which today forms the basis of Akka, a distributed computing framework created by Jonas Bonér in 2009.
“The actor model is this 50-year-old idea that turns out to be the perfect revolutionary new execution engine for a streaming graph,” Wright says. “And so that’s what novel about Quine is the graph data model combined with a graph computational model backed by actors.”
Quine can process 1 million real-time events per second, its founder says
In actor models like Akka, an actor is a small, lightweight computing engine that has its own CPU thread and which encapsulates one state of data, Wright says. Multiple actors can interact together in an asynchronous and highly scalable manner. This is the core concept that enabled Wright to design Quine as a graph engine.
“For us, that translates directly to one node in a graph,” he says. “So one node in a graph basically has its own thread, its own CPU. It can take arbitrary computation as needed.”
Wright developed Quine in Scala atop Akka, and paired the computational engine with Cypher, the open source graph query language developed by Neo4j, the company that’s credited with popularizing the property graph databases. There is also a swappable storage engine that supports RocksDB, Cassandra, and S3.
There’s a two-step process for using Quine, Wright says. The data starts out in a streaming source, such as Apache Kafka, Amazon Kinesis, or a similar product.
“So high-volume events coming in one event at a time, and each of those events gets fed to a user-written Cypher query,” he says. “A user writes a Cypher query to, say, take this event and create this graph structure from it. And so it creates a small tiny little sub-graph for every event that comes in. And then the second part of this is what’s especially novel about Quine, and just really changes the ball game. You can set what we call a standing query.”
A standing query is something that can live inside the graph, waiting for a matching event to occur, he says.
“It moves itself through the graph automatically,” Wright says. “And it does so at exactly the optimal time for when it’s fastest and most efficient, and every time there’s a new match–because the data streaming is still changing the graph–every time that there’s a new match for the query that you’re looking for, it gets assembled and streams out to the next system or triggers some other action, or can even call back into the graph and update what’s in there.”
The combination of graph the two technologies enabled Quine to get the scale for graph that his client needed.
“We showed him a million events per second of ingested data while simultaneously doing graph queries on it and the streaming results out,” Wright says. “So that was just a game changer, several orders of magnitude beyond the state of the art.”
Hunting APTs
DARPA caught wind of Wright’s project, and for several years provided him with funding to continue building it. The federal government’s advanced research agency was concerned about the difficulty in detecting advanced persistent threats (APTs) inside the Department of Defense.![]()
“If an attacker like that gets into an enterprise environment, the state of the art is you’re out luck,” says Wright, who has worked on several DARPA projects over the years. “There’s no way to find them. There’s no way to stop them. You’re just in trouble.”
The approach that Wright took with Quine is to essentially monitor the events occurring on every single machine, “and then do some analysis that stitches it back together into a graph and analyzes that, fast on the fly,” he says. “That’s exactly Quine’s sweet spot. And so Quine was developed before that DARPA program. But the DARPA program was a perfect application for the technology.”
Since then, the open source streaming graph product has been adopted by a number of other organizations. Many of them are in cybersecurity or fraud detection, which are common areas for traditional graph databases. It’s also found application in retail and ad tech. A small but growing community of users have started sharing “recipes” based on the open source streaming graph engine.
Quine is not for everyone. If the goal is to hold onto lots of historical data and occasionally query it to find connections, then traditional graph databases are probably a better bet. But if wherever there is a large amount of data flowing in real time and the goal is to know what that data means, then Quine has a potential solution.
Wright is using a traditional commercial open source model with thatDot, including providing technical support for Quine users. Companies that want to scale the system into the higher echelons of data (think hundreds of thousands of events per second) can also get assistance from thatDot.
Related Items:
Akka Cloud Platform Now on AWS
The Graph That Knows the World
Why Young Developers Don’t Get Knowledge Graphs
Applications:
Complex Event Processing
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States