

February 11, 2022
The Data Is Not All Right

(The Offspring/The Kids Aren't Alright)
A funny thing happened on our quest to be data-driven and data-centered beings and organizations–we discovered how bad our data really is. And like a self-help program stuck in an endless Groundhog Day-like loop, we seemed doomed to repeat the exercise of acknowledging the problems and pledging to do data better. It never seems to work. Maybe this time is different?
The sorry state of data shouldn’t come as a surprise at this point in the game. But, alas, it still makes the news. It’s like the goose that laid the golden eggs, only the eggs are made of something else, and we can’t stop production. It’s not that we never find any good data. We stumble upon the gold every now and then. It’s just that there is so much bad data about that we may not even recognize the good stuff when we step in it. And the problem seems to be getting worse.
The latest example of our deficient data world comes from Validity, which this week unveiled its latest “State of CRM Data Health” report. As you may have already guessed, the state of CRM data health is not good.
“Too many CRM users blindly assume their data is clean and ready for meaningful use,” Validity states in its report, which can be downloaded here. “And in many cases, they’re wrong.”
People often are not aware how bad their data really is. Validity’s report, which is based on a survey of more than 1,200 CRM users in the US, the UK, and Australia, found that 76% of respondents rate the quality of the data in their CRM system as “good” or “very good,” while 62% say they have “high” or “very high” trust in their data.

(Image source: Validity State of CRM Data Health)
“CRM users painted a rosy picture of their CRM data quality,” Validity states in its report. “But when drilling deeper, a surprising trend emerged: User confidence in CRM data did not reflect reality.”
According to the report, 44% of respondents estimate their company loses more than 10% in annual revenue due to poor quality CRM data. Despite the obvious problems with the data, data quality is a high priority for leaders at only 19% of the organizations surveyed.
But wait–it gets worse. The report found that three-quarters of employees admit to fabricating data to tell the story they want decisions makers to hear. More than four out of five hunt for data that supports a specific narrative, rather than letting the data drive the ship. This is not the data-centered future that we were promised.
“This means that overwhelmingly, leaders are making important business decisions based on manipulated and inaccurate data,” Validity states in its report. “Low-quality data can be a silent killer for businesses–particularly when many industries are still reeling from the fallout of COVID-19, making it difficult to deliver strong, consistent performance.”
Staggering Costs
Gartner recently estimated that poor data quality costs organizations an average of $12.9 million per year, which is a staggering sum. To put this in perspective, the average cost of a data breach is $4.24 million, according to IBM’s “Cost of a Data Breach Report 2021.” You could fit three data breaches inside of the cost of just an average year’s worth of data quality problems. Plus, not every company suffers a data breach every year, but data quality is like the malicious goose that keeps on giving.
(Source: Gartner)
Not only does bad data quality hurt a company’s revenues in the short term, but it can also lead to poor decision making well into the future, according to Melody Chien, a senior director analyst at Gartner.
“Data quality is directly linked to the quality of decision making,” Chien says. “Good quality data provides better leads, better understanding of customers, and better customer relationships.”
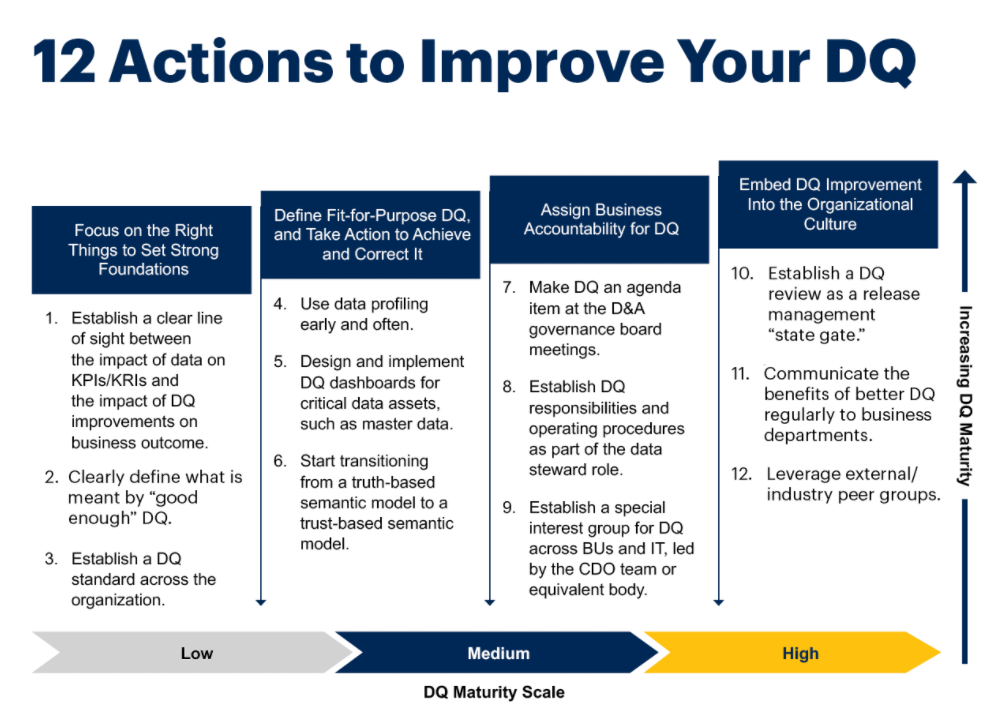
Gartner defined 12 actions that it recommends organizations take to make data quality a strategic asset for organizations. It starts with setting strong foundations around data quality definitions and the processes needed to enforce it, and gradually moves up into building accountability for data quality into the organization and the culture.
Greater Expectations
A 12-step program may be a good place to start with the data quality problem, but more investments must be made, particularly in automating the processes needed around building quality into data.
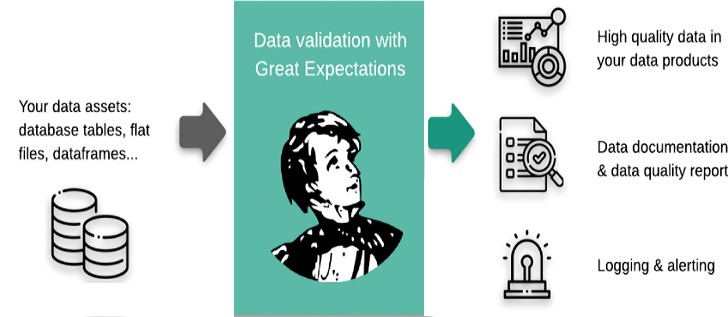
One company that’s making those investments is Superconductive, which is the commercial outfit behind an open source data quality tool with a fittingly Dickensian name: Great Expectations.
Great Expectations’ design mantra is to “help data teams eliminate pipeline debt through data testing, documentation, and profiling.” The product starts with a statements of expectations about the data, or assertions. This is the “workhorse abstraction in Great Expectations, covering all kinds of common data issues.” The tool also helps users create tests for data quality, built reports on those tests, conduct automated data profiling, and automatically validate data in the pipelines.
Superconductive yesterday announced that it raised $40 million in a Series B funding round led by Tiger Global, with support from Index, CRV, and Root Ventures. The Salt Lake City, Utah company is hoping to parlay the tremendous interest in Great Expectations into a cloud-based offering, which is in the works.
(Source: Great Expectations)
“Great Expectations is one of the fastest-growing open source communities in the data ecosystem,” said Abe Gong, CEO and co-founder of Superconductive. “It’s downloaded nearly 3 million times every month, and is rapidly becoming the de facto shared open standard for data quality.”
Along with improvements to the open source version, the company is working on development The funding will go to bolster the open source version of the tool, as well as to help develop the paid Great Expectations Cloud offering, which will be bring a suite of collaboration and orchestration tools for managing data quality.
Clearly, data quality is a problem that demands attention. The fact that Alteryx spent $400 million to acquire Trifacta in January shows that the smart money is at least aware of the problem. With the investment in Superconductive and the growing interest in data observability, it seems that we are increasingly aware of the problem. But a lot more work needs to be done if we are going to reach the best of data times.
Related Items:
Alteryx to Acquire Data Wrangler Trifacta for $400 Million
What We Can Learn From Famous Data Quality Disasters in Pop Culture
In Search of Data Observability
Applications:
Enterprise Analytics
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States