

January 17, 2022
Data Silos Are Here to Stay. Now What?

(zentilia/Shutterstock)
Data Silos are not going away. In fact, the pandemic has accelerated the pace of digitization, and with more departments undertaking more digital initiatives of their own, we are creating more data silos. No company sets out to create silos. They form as departments begin to store and process data for their own use and as different storage architectures are used through the data lifecycle, each with its proprietary data management.
Silos have existed even from the mainframe days, to keep hot, active data on the expensive mainframes and cold, older data and backups on tape archives. As we have added more layers of price/performance with disk, Flash, object storage, and cloud–and as we have more vendors in the mix–data ends up in different places, sometimes for the same workflows and sometimes by different users, resulting in a proliferation of silos.
Silos were easier to manage when the options for data storage were just disk and tape; disk is inline while tape is offline, so it was okay to use a proprietary storage-vendor centric solution to bring data back from tape.
Managing silos is harder today and becoming more urgent for many reasons:
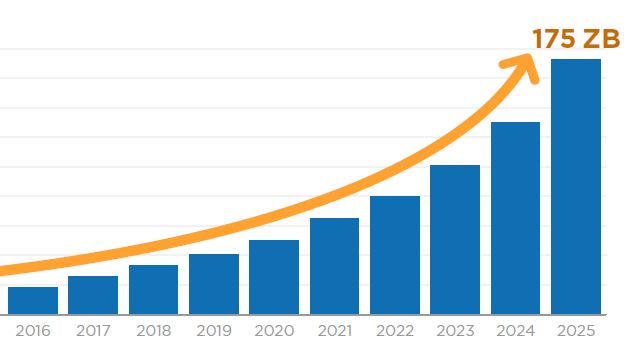
- Explosive data growth: Roughly 90% of the world’s data was created in the last two years, and 80% of it is unstructured, meaning it does not follow a specific schema. This growth is accelerating, which means organizations need more efficient ways to manage data.
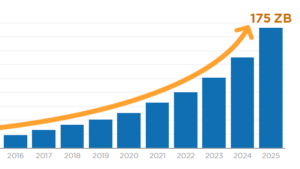
IDC says 175 ZB will be created by 2025 (Image courtesy IDC)
- The rise of edge to cloud: You may be thinking: “Isn’t everything going to the cloud and doesn’t that eliminate silos?” The answer is not that simple. First, while there is a massive generational shift to the cloud, the cloud is not a single monolithic silo. Rather, each cloud is a robust ecosystem of multiple data storage and data processing architectures, both from the cloud vendor and from third parties. Take AWS, for example – it currently has over 20 classes and tiers of file and object storage and a slew of data analytics services, plus services from third parties such as NetApp, Snowflake, and Databricks. The challenge for enterprises is to get visibility into data across the various buckets and datastores in the cloud, and then to mobilize data so the right data is living in the right class and tier at the right time. Meanwhile, we are just at the beginning of data at the edge. All the data generated by self-driving cars, autonomous systems, IoT, will lead to more data that needs to be processed and consolidated at the edge and then moved to a cloud. This leads to proliferation of silos by locality.
But Isn’t a Data Lake Unifying Data Silos?
Weren’t data lakes supposed to replace all silos? Data lakes are appealing because, unlike data warehouses, which have a strict schematic structure, a data lake can ingest any data in its native form. This means that enterprise can move data into a data lake without any preprocessing. On the downside, this capability means that data lakes easily turn into data swamps: unstructured data of varying types such as audio files, video files, genomics data, log data, and documents are dumped into the lake. It becomes impossible to find anything because there is no common structure.

Data lake’s risk becoming dumping grounds without proper governance
Also, there isn’t a single data lake. Even if you are on a single cloud like Azure, you probably have multiple Azure accounts, each with multiple buckets, perhaps in different classes and tiers of Azure Blob and Azure Data Lake Storage. The conceptual “data lake” is actually fragmented across hundreds of buckets, cloud accounts and it is incomplete because it does not have your file data stores or on-premises data.
It’s Time to Embrace Data Silos
Data silos are not going away – if anything, we are going to have more data silos. The answer isn’t to try and create a new single silo but to seek solutions that can optimize, mobilize and manage data across silos so that users can search and extract data from multiple data silos.
Imagine if you could easily curate just the data sets you need no matter where the data lives, if you could systematically move the right data to the right place at the right time and if you could continuously optimize and enrich the metadata as it flows through cognitive analytics systems?
This would enable data managers and data scientists to move files into new clouds or applications yet retain the tags needed for rapidly searching and segmenting data to feed data analytics pipelines. Storage IT is evolving to include data management and enable business outcomes rather than simply manage infrastructure or impose limitations on how and where data is stored. By embracing silos, enterprises can gain flexibility, cost and performance advantages and avoid vendor lock-in – all while still being able to monetize their vast stores of data. 
About the author: Krishna Subramanian is the President, COO, and co-founder of Komprise, a provider of unstructured data management solutions.
Related Items:
Big Growth Forecasted for Big Data
Unstructured Data Growth Wearing Holes in IT Budgets
Cloud Storage: A Brave New World
Applications:
Data Mining
Technologies:
Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States