

November 18, 2021
Your Data Is Talking. Are You Listening?

(Igor Nikushin/Shutterstock)
Imagine you’re reading a murder mystery. The plot’s thickening, the game’s afoot, you’re pages away from knowing who’s done it and you’ve reduced your fingernails to a stub. Then, all of a sudden, a new character enters the scene and you’re thrown completely off-guard. In a mere moment, your eagerness to know the ‘who done it’ has given way to confusion.
A data anomaly is often like an unexpected intrusion or a plot twist that leads a good story astray.
From rainfall totals to monitoring a production line, data anomalies can have a profound impact on business outcomes. While sometimes anomalies are possibilities, more often they distract from the predictability and safety of consistent and reliable business data.
Why Do We Care About Data Anomalies?
Recently, a banking client had a problem: They had to restate several quarters of regulatory reporting because anomalies in their data caused their original reports to be inaccurate. The clients’ existing anomaly detection system had not identified these issues, which meant not only fines and penalties from the regulators, but also a significant amount of labor to identify and remediate their data.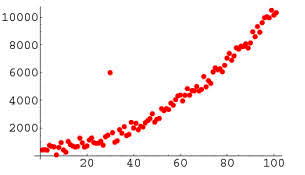
The client needed an AI based anomaly detection engine, to rapidly assess the data and provide reliable results. The system identified a range of issues which further lead to identifying issues in the underlying data systems – an unexpected outcome.
Deleting, ignoring (or remediating) anomalous data without investigating the cause could be catastrophic, not to mention expensive. A few examples of the importance of anomalies in your data:
- Used to detect network intrusions in security software
- Used as an early indicator of a machine or part failure
- Used as an early indicator of a medical event
- Used to foretell the beginning of a shift in your data
- Used to improve manufacturing processes
- Used in survey data to identify opportunities for oil and gas exploration
Finding the Needle in the Proverbial Haystack
Not all data will have anomalies and not all data types easily lend themselves to anomaly detection. Some data manipulation platforms have a basic level of anomaly detection built in. For more complex anomaly detection, a Machine Learning based anomaly detection engine is often necessary. Detection methods cover a range of options:
- Low complexity: A categorical data element is one value 99% of the time. The remaining 1% may be an anomaly.
- Medium complexity: Identifying a point anomaly in a less data type centric model using simple machine learning.
- Higher complexity: Utilize a machine learning model to forecast a value, then compare to the actual value and flag variances.
- Very complex: Use deep learning models to identify both contextual and collective anomalies.

(andromina/Shutterstock)
Your choice of detection algorithm should be based on a combination of the type of data to be reviewed, the amount of data, the relative speed of processing required (batch or API?) and your required accuracy. In general, the more features your data has (think columns in a spreadsheet), the more complex the algorithm will be and the more compute power you will need to train and test your algorithm.
I’ve found the Anomaly. What’s next?
Once anomalies are detected, your options depend on your understanding of the anomaly, the type of data and where the anomaly is identified. Your detection method is often the first step in understanding the anomaly.
Anomalies should be viewed both in the context of the data, and the context of how and why a data element has been flagged as anomalous. A point anomaly in a column of data may only require the definition of how far from the mean the data lies. Where a contextual anomaly will require a more horizontal view of the data in the record along with the descriptor of why, in context the data element is flagged. Collective anomalies may require an even more comprehensive view of the data over time to explain the flagging of one or more data elements.
Step 1: Addressing the “Why”
In all contexts, understanding the ‘Why’ is a required element before addressing the ‘how’. Is this a one-time thing (e.g.: a larger than normal credit card transaction?) Is this the harbinger of a shift in the data? Is there an upstream issue with my data ecosystem? Each of these questions could lead to a different approach to resolving the anomaly (or not) and data remediation techniques will vary. Maintaining the integrity of your data should remain paramount and should not be taken lightly.

(Syda Productions/Shutterstock)
Step 2: Deciding “If It Should Be Fixed”
For many clients, detecting a problem in the data results in remediation of upstream systems and re-executing processes. Sometimes the answer varies by industry. In financial services, the focus is often the root cause. The anomalous data often must be corrected at the source. In manufacturing, an anomaly could be a signal such as a heat or vibration change in a machine. In these cases, there is often no need to fix the data, instead there’s a need to fix the underlying problem. In healthcare, the “how and Why” can be central to the “should we fix it”. Here, an anomaly could be the result of a bad measurement or could be a signal. Each data scenario presents itself with a multitude of options. When there is a need for remediation, Data Governance processes define the remediation options including preserving data lineage and data integrity.
An anomaly may not need remediation, instead it simply needs to be understood. Anomalies are not inherently ‘bad’, but they can tell a story. You need to understand the story before acting.
Step 3: “Fixing” the Anomaly
When considering data remediation, care should be taken to avoid creating additional problems. This includes avoiding common database problems such as a modification and insertion anomalies.
Data remediation will be affected by the type of data and can be as complex as the anomaly detection process itself. Is the data part of a time-series, Categorical, Continuous, Discrete or something else entirely? Each data type must be approached with different remediation techniques. Remediating a singular anomaly could cascade into a contextual anomaly if done incorrectly.
Remediation can range from simple (use of a normalized value), to the complex (building a predictive model). There is no singular solution for remediation, just as there is no singular way to identify the anomaly.
Changing Your Business Outcome
Identifying and making decisions about anomalies in data is similar to the resolution of a crime novel. You have evaluated all the clues and identified the villain. As a result, justice can be done. You either acquit or convict the offending data elements, you can use them or exclude them. The decision is based on your knowledge of the business. Artificial Intelligence or Machine Learning technology are an aid to the decision-making process, not the decision maker.
About the author: Harry Goldman is Practice Lead for data science and analytics at NTT DATA Services. He is an experienced consultant with skills encompassing Data Science, Machine Learning, Big Data, Data Architecture and Data Governance. He is experienced in business transformation, decision sciences, analytics, strategy, governance and data modeling with a focus on the impact of data on the enterprise, information architecture and data strategy. He has served as a lead Data Scientist, working in a variety of consultative opportunities and has developed a BI platform for a major healthcare group. He is well known for his client centric advice, with a strong focus on Data Science, Data Analytics, Data Strategy and Governance.
Related Items:
Visualizations That Make You Go ‘Hmmm’
Four Key Attributes of Advanced Anomaly Detection
Big Data Outlier Detection, for Fun and Profit
Applications:
Artificial Intelligence
Vendors:
NTT Data Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States