

November 9, 2021
Confluent Ships ‘Cluster Linking’ in Kafka Platform Update

(Cagkan-Sayin/Shutterstock)
Companies that are pushing the envelope in terms of the scale of their real-time streaming data deployments will be happy to know they can now run a Kafka cluster that spans on-prem and cloud resources via cluster linking capability, the top-level item in Confluent Platform 7.0, which also includes capabilities for managing Confluent containers running atop Kubernetes and was announced today.
Confluent says cluster linking is a form of geo-replication technology on Confluent Platform 7.0 (which is based on Apache Kafka 3.0) designed to create “perfect copies” of Kafka topics and then keep the data in sync across clusters, no matter where they are located, including on-prem Kafka clusters and Confluent Platform running in AWS, Google Cloud, or Microsoft Azure.
Confluent says cluster linking can be used in any environment, including hybrid and multi-cloud setups. The new feature helps to tamp down on the need for additional layers of complex tooling across siloed data and architectures, says Ganesh Srinivasan, Confluent’s chief product officer, Confluent.
“With cluster linking, the data across all the parts of a company–from cloud, on-premises, and everything in between–can be quickly connected in real time to help modernize businesses and build stand-out applications,” Srinivasan says in a press release.
Cluster linking doesn’t create a single cluster out of multiple clusters. Instead, it allows data to flow among those multiple clusters more easily. The feature is controlled via commands or API calls. Once created, the link “acts as a persistent bridge between the two clusters,” the company says in its Confluent 7.0 announcement materials.
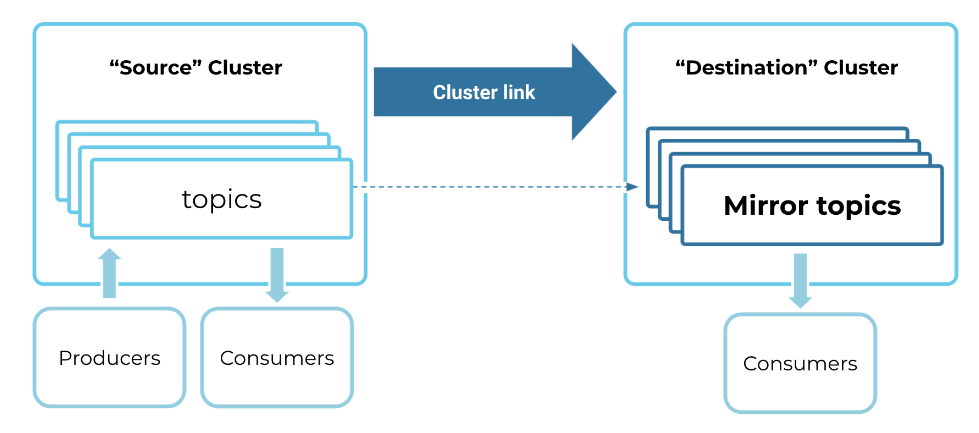
Cluster linking is a geographic replication feature now supported in Confluent Platform 7.0
Cluster linking also brings about a new type of topic in Kafka clusters called mirror topics. “Mirror topics are a special kind of topic,” the company says. “They are read-only copies of their source topic. Any messages produced to the source topic are mirrored to the mirror topic ‘byte-for-byte, meaning that the same messages go to the same partition and same offset on the mirror topic.”
Confluent envisions the new cluster linking capability to be used for global data sharing, data migration, and high availability and disaster recovery use cases. Considering that recent research from Ventana Research shows that 63% of companies today have multi-cloud or hybrid cloud deployments–a figure that’s expected to grow to 75% in 2023–anything that can reduce complexity of data movement will be welcomed.
Previously, cluster linking was in preview. With that release, the big limitation was that, while the source Kafka cluster could run atop Apache Kafka 2.4 or higher or Confluent Platform 5.4 or higher, the destination cluster must be running in Confluent Cloud. But now that the product is generally available, data can flow bi-directionally between Confluent Platform 7.0 running on prem and in Confluent Cloud.
One company that’s using cluster linking to help migrate from an on-prem Kafka cluster to Confluent Cloud is the analytics giant SAS. According to Justin Dempsey, SAS’s senior manager of software development, cloud, and information services, cluster linking played a “critical role” in its migration to Confluent for Kubernetes.
“Our transformation to a cloud-native, agile company required a large-scale migration from open source Apache Kafka, which was complex and challenging to self-manage,” Dempsey says in a press release. “With Confluent, we now support real-time data sharing across all of our environments, and see a clear path forward for our hybrid cloud roadmap.”![]()
Confluent Platform 7.0 also brings new cloud-native management capabilities and enhancements to its cloud-based monitoring for on-premises clusters.
Specifically, the company is launching Confluent for Kubernetes, a new offering that streamlines the provisioning and management of data connectors, schemas, and cluster links through an API, rather than requiring administrators to accomplish these tasks manually.
Enhancements have also been made to the Confluent Control Center, which allows operators to centrally managed and monitor key aspects of their Confluent Platform enjoinments. In previous releases, Control Center required the data for monitoring clusters to be stored locally, which could become expensive from a storage perspective.
With Confluent Platform 7.0, the company is addressing that concern by introducing Health+, a new monitoring system that does not require the data to be stored locally. Customers can save 70% of the costs they previously paid for storing data in Confluent Control Center. The company also launched what it’s calling a Reduced Infrastructure Mode for Control Center, which essentially turns Control Center into a management-only tool (with the monitoring portion now handled by Health+).
In other news, Confluent last week released its second earnings report since it went public back on June 24. The company announced total revenue of $103 million for the third quarter fiscal 2022, which was a 67% increase over third quarter 2021 figures. Revenue from Confluent Cloud amounted to $27 million, which was up 245% from the previous year. All told, the company now has 664 customers that are spending at least $100,000 annually with the company, a figure that’s up 48% from 12 months ago.
The company’s stock, which is traded on the NASDAQ under the ticker symbol CFLT, was up 18% on the news, and is now trading around $88 per share, a record high for the company, which has a market capitalization around $23 billion.
Related Items:
Confluent Raises More Than $800M in IPO
Intimidated by Kafka? Check Out Confluent’s New Developer Site
Three Takeaways from Jay Kreps’ Kafka Summit Keynote
Editor’s note: This article has been corrected. Data can now flow bi-directionally using the replication feature in cluster linking in Confluent Platform 7.0, not just to the Confluent Cloud.
Applications:
Complex Event Processing
Vendors:
Confluent
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States