

November 1, 2021
Cerebras Hits the Accelerator for Deep Learning Workloads

Cerebras is targeting AI workloads with its custom chip
When it comes to large neural networks like BERT or GPT-3, organizations often must wait weeks or even months for a training task to complete if they’re using traditional CPU and GPU clusters. But with its massive Wafer-Scale Engine (WSE) chip, Cerebras Systems says it can cut that training time down to days, enabling data scientists to iterate more quickly with the same tools.
Cerebras Systems is one of a handful of new chipmakers that are targeting the growth in neural network workloads, specifically the natural language processing (NLP) and computer vision models that are at the heart of today’s AI revolution. From intelligent chatbots and document analysis to drug discovery and oil well analysis, organizations are pressing the limits of what conventional hardware can do.
According to Andy Hock, vice president of product for Cerebras, conventional clusters built on small processors have gotten us this far. But at the current rate of growth, NLP and computer vision models will outstrip the capabilities of the traditional hardware apporach.
“What we’re seeing is that as models continue to grow exponentially, we’re running into the limits of brute-force scaling of compute,” Hock says. “We need a different approach to the computing that will allow researchers to iterate more quickly–that is, to train large models more quickly or large datasets, and then turn around and run those large models in production with high throughput and low latency.”
The fundamental problem, Hock says, is that conventional processor architecture are ill-suited to the demands of deep learning. While GPUs have proven to be well-suited for many machine learning tasks, they’re fundamentally optimized for dense matrix-matrix operations, whereas the math behind deep learning requires more matrix-vector or vector-vector operations, he says.
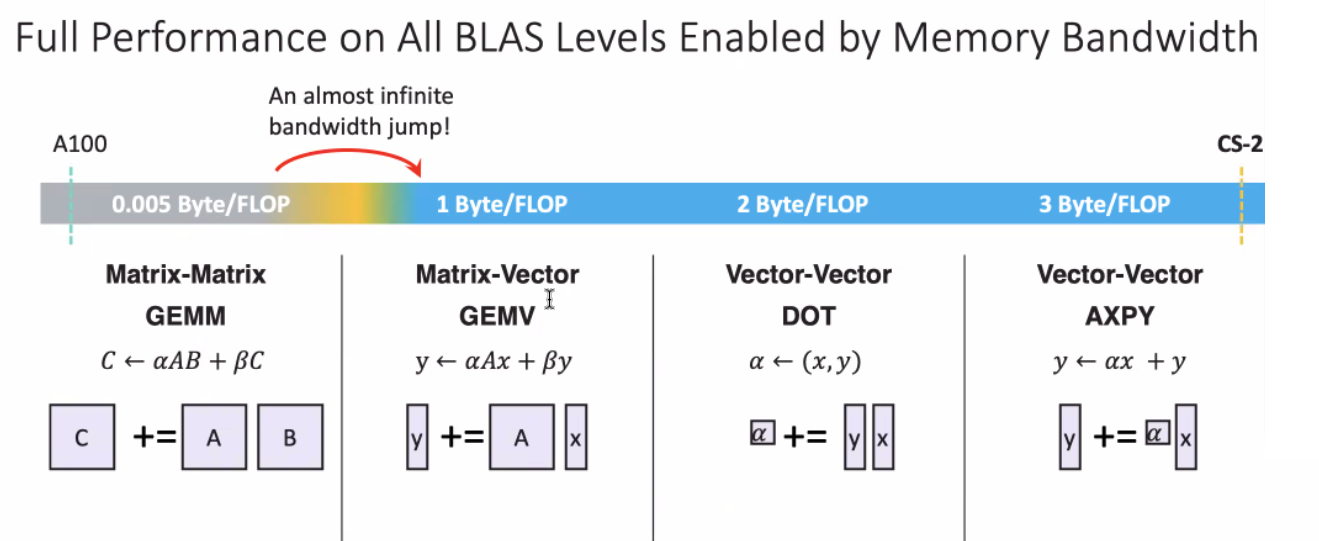
The WFE-2 chip delivers the additional memory bandwidth needed for the most common types of math used in deep learning workloads (Image source: Cerebras Systems)
“GPUs like Nvidia’s latest A100 are built for dense matrix-matrix operations,” he says. “That has a relatively low memory bandwidth requirement because you’re basically loading in a 2D array, doing matrix-matrix multiplication on a 2D array against another 2D array, and then writing output out.”
That approach ideal for image processing applications, but not for deep learning, he says. Traditional GPUs designed for matrix-matrix operations deliver memory bandwidth of about .005 bytes per FLOP of compute. When you move up to matrix-vector and vector-vector operations, however, the memory bandwidth demands grow exponentially.
“In order to approximate this mathematics, what a GPU does is it basically stacks up a bunch of vectors so they look like a matrix, and it turns it into a matrix-matrix operation,” Hock continues. “That’s really inefficient, and actually constrains what ML researchers and data scientists can really do, by for example incentivizing them to use larger batch sizes.”
In designing its chip, the WSE, Cerebras focused on ways to boost the available memory bandwidth. Instead of designing a small processor with the idea of linking many of them together, Cerebras went big, and literally designed a massive chip that could execute as many of the functions needed for deep learning directly on the chip, thereby eliminating the need to move data around a cluster.

The Cerebras CS-2 can replace a cluster composed of dozens to hundreds of GPU nodes, Cerebras says (Image source: Cerebras Systems)
With 2.6 trillion transistors and 850,000 cores spread across 46,225 square millimeters, the WSE-2 is 56 times larger than the biggest GPU chip. Owning the title of world’s largest chip, the WSE-2 offers 40GB of on-chip memory, memory bandwidth of 20PB per second, and 220Pb per second of interconnect bandwidth between the cores, which is 45,000 times as much bandwidth as available on a GPU processor, the company claims.
“By bringing together the memory and compute and communication resources all into a single device, we achieved massive advantage not just in size but also in the compute and memory and communication metrics that matter for deep learning,” Hock says.
Delivered in a single system called the CS-2, Cerebras’ server can fit into an industry standard rack. The Cerebras system uses up to 12 100Gb Ethernet ports to connects to a supporting X86 cluster, which functions as network attached storage and also does data pre-processing steps, such as image formatting.
While the company hasn’t published any benchmark tests yet, Hock says a single CS-2 system can do the same amount of deep learning as a cluster composed of dozens or hundreds of GPU nodes.
According to Hock, one of Cerebras’ partners took a couple of weeks to train an NLP model based on BERT Large on an eight-GPU system. The partner then took the same model and the same training data and trained it on the first-generation Cerebras system. The equivalent level of accuracy was reached after just over 23 hours.
Another customer that spent about 18 weeks training, debugging, and optimizing the performance of a model on a GPU cluster. When it ran on the Cerebras machine, that same process took them less than four weeks, Hock says.
Another challenge with using GPUs is that the performance doesn’t scale linearly, Hock says. “As you start to build a cluster from 16 GPUs up to over 300, you might expect that you would get something like 30X faster if this scaling and time to solution was linear,” he says. “But it turns out you only get about 5X faster by scaling from 16 to more than 300 GPUs.”
That starts to matter as the number of parameters in the deep learning model goes up. With a model with hundreds of billions of parameters, such as BERT Large, it will require a massive investment in GPUs to be able to shrink the training time from weeks down to days.
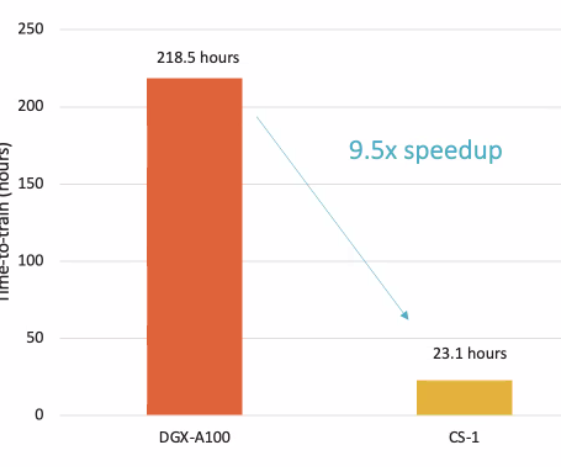
Training for a BERT system on a GPU-based system versus the CS-1 (Image source: Cerebras Systems)
“You’re building out clusters that has racks upon racks or GPU servers and the cost goes through the roof and the efficiency is not good,” Hock says. “Not are we delivering faster time to solution, but doing that in that package there’s far more space and power efficient, fundamentally, because we don’t have to drive all those bits of data between many systems across an aisle of data centers. We’re doing that over microns on a on a single wafer-scale device.”
While Cerebras ostensibly is a hardware company, it has invested in the software side of the stack too. Unlike some competitors that are developing novel AI chips, Cerebras is not tightly coupling the deep learning software to its machines. It’s vowing to remain Switzerland when it comes to software.
To that end, it’s supporting PyTorch and Tensorflow, which are two of the most popular frameworks for developing deep learning applications. It’s doing that by supporting a common intermediate layer called accelerated linear algebra (XLA), which is part of the Google’s Tensorflow library that is also to compile down to PyTorch, Hock says.
So far, most of Cerebras’ customers are supporting NLP workloads, including information retrieval, question answering, and named entity recognition, although there is a smattering of convolutional neural networks for images as well as graph based neural networks.
Customers include GlaxoSmithKline, which uses Cerebras’ gear to help with drug discovery via NLP methods, as well as Lawrence Livermore National Laboratory, which uses Cerebras to accelerate fusion simulations running on its Lassen supercomputer.
As the size of deep learning models grows, Cerebras intends to help customers cope with the added complexity by simplifying the infrastructure underlying those models. And along the way, it might help influence the trajectory of AI along the way.
“What we really want to do is open up this problem space and these kinds of computing opportunities to more researchers and more organizations,” Hock says, “and drive not just continued growth in AI models, but to develop smarter or more efficient models as well.”
Related Items:
Chip Shortage Hurts AI, But Hardware Just Part of the Story
The Perfect Storm: How the Chip Shortage Will Impact AI Development
A Wave of Purpose-Built AI Hardware Is Building
Applications:
Artificial Intelligence
Technologies:
Processors
Tags:
Andy Hock, BERT, computer vision, deep learning, GPT-3, neural network, NLP, wafe-scale engine, WSE-2
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States