

October 5, 2021
TigerGraph Bolsters Scalability with Graph Database Update

TigerGraph today announced that the latest release of its parallel graph database can be fully controlled with Kubernetes. With version 3.2, the company also added the ability to scale the database up and down as needed, bolstered support for cross-region replication of database clusters, and doubled number of graph algorithms for data science use cases. It also reported a results for new business intelligence benchmark.
Ever since it emerged four years ago with a graph database that scales out natively on clusters of up to 1,000 nodes, TigerGraph has been pushing the boundaries of what a property graph database can do. With its “graph 3.0” approach, which combined the benefits of native graph storage along with the ability to continuously refresh the database with new data (a common bottleneck afflicting other graph database players), founder and CEO Yu Xu aimed to tackle the biggest graph challenges.
Today, the company is hoping to take that scale-out story up a notch with the launch of TigerGraph version 3.2. Chief among that story is its support for Kubernetes. With a prior release of the product, only a single node of the database could run atop Kubernetes, which obviously limited its usefulness. With the new version, the company is delivering “full clustering support,” says Jay Yu, the company’s vice president of product and innovation. “You can use Kubernetes to manage a cluster of TigerGraph,” he says.
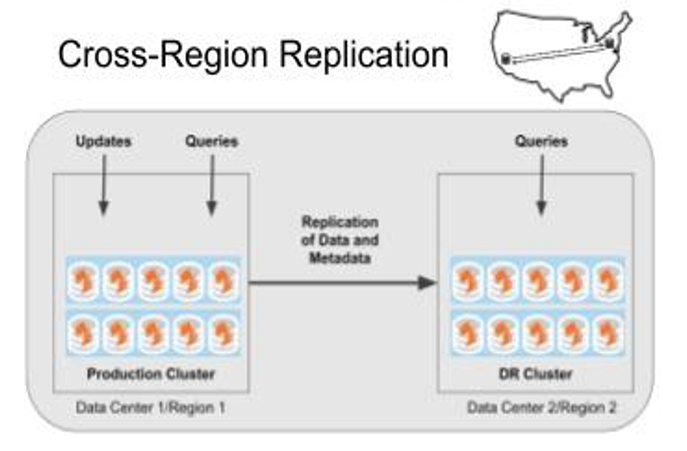
TigerGraph delivers cross-region database replication with version 3.2
Other operational improvements include the capability to resize the cluster with a single command, which is not related to the Kubernetes support. It also is delivering cross-region replication, which will enable a customer to mirror a cluster to another cluster in geographically remote location. Users also gain the ability to directly control resource allocation for big queries.
“We supported multi-zone high availability within a region before, not cross-region read replication,” Yu says. “Now with [this] configuration, you can set up a full read-replica of the main cluster in another region. Updates are replicated in real-time (bounded by physical network speed) to the remote region. The replica in the remote region is active, and can take on read-only queries.”
To demonstrate TigerGraph’s scalability, the company ran its database against the Linked Data Benchmark Council’s Social Network Benchmark (LDBC-SNB) 30TB BI SF-30K benchmark. TigerGraph says it satisfied the benchmark’s demanding business intelligence requirement with a graph encompassing more than 70 billion nodes and more than 500 billion edges.
The LDBC-SNB BI benchmark, which focuses on “aggregation and join-heavy complex queries touching a large portion of the graph with microbatches of insert/delete operations,” is not yet finalized, and the LNBC website shows no official results have been submitted by any vendors. Yu says LDBC is in the process of certifying TigerGraph’s submission, which he expects will take a couple of months.

TigerGraph says its the only organization to complete the LDBC NSM-SF30K BI benchmark at 36TB; results have yet to be verified (Image from TigerGraph)
“There is no other vendor in the world that has completed this new BI benchmark (version 0.4.0) at this scale,” Yu says. “Note, this BI benchmark has a micro-batch update, which simulates a real-production environment, where the graph will be mutated by daily incremental updates at night.”
TigerGraph worked closely with the LDBC SNB taskforce to get this scale data set generated, Yu said. The groups started with scale-factor 10k and then worked up to 30k, he said. TigerGraph reported bugs along the way and worked with the LDBC SNB taskforce to fix them, Yu said. “As far as we know, we do not hear anybody trying this scale yet,” he added.
The company also doubled the number of data science algorithms that it ships with the platform to more than 50. That includes algorithms like Node2Vec, a algorithmic framework out of Stanford for representational learning on graphs; and FastRP, a node-embedding algorithm that its creators claim is 4,000 times faster than Node2Vec.
Yu said there is a marked increase in interest in data science use cases among TigerGraph customers. “Nearly every customer is now asking about some form of graph data science: traditional algorithms like centrality or community detection, or graph machine learning algorithms such as graph embeddings or graph neural networks,” he said. “They see use cases for improved fraud detection, improved recommendations in complex situations or when there is limited profile information, and to model and make predictions about their critical business operations.
The company claims there are benefits to its in-database approach. By running data science algorithms directly in the graph database, it eliminates the need to move the data out of the database to run the algorithms, TigerGraph says. The parallel nature of TigerGraph also benefits users by enabling algorithms to run as a unit on up to hundreds of terabytes at a time, the company says. And since the open source algorithms in Tigergraphs’s In-Database Graph Data Science Library all use Graph SQL (GSQL), they speak the same language as user-authored algorithms on TigerGraph’s database.
In other news, TigerGraph version 3.2 also brings 30 more bult-in functions to the query language, along with support for variable definitions, flexible query function parameter assignment, flexible query function return, and query function overloading, the company says.
Related Items:
TigerGraph Roars with $105 Million Round
TigerGraph Offers Free Graph Database for On-Prem Analysis
TigerGraph Emerges with Native Parallel Graph Database
Applications:
Enterprise Analytics
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
TigerGraph
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States