

September 21, 2021
An All-Volunteer Deep Learning Army

(srgraphi/Shutterstock)
A team of researchers says their novel framework, called Distributed Deep Learning in Open Collaborations, or DeDLOC, brings the potential to train large deep learning models from scratch in a distributed, grid-like manner using volunteers’ disparate machines, potentially lowering the steep barrier-of-entry to large-scale AI.
The advent of deep learning gives companies close to human-like understanding in the fields of language processing and computer vision. But it typically requires a substantial investment in hardware and massive amounts of energy to train deep learning models from scratch, which puts the technology and its benefits out of reach for all but the largest companies and academic institutions.
One potential solution to this dilemma is to make pre-trained models available to academics and other interested parties via “model hubs.” However a lack of diversity in languages in linguistic models and limitations in the types of objects that vision models are trained to detect make this approach less useful than it otherwise could be.
In some cases, deep learning models simply need to be trained from scratch for them to be useful in a given field. That is what drove a group of researchers from the U.S., Canada, and Russia to create DeDLOC, which is based on a novel algorithm that distributes training workloads to disparate hardware.
Max Ryabinin, a research scientist from Moscow, Russia-based Yandex Research who helped develop DeDLOC, recently spoke with Datanami about the project.
“The idea is that some people are willing to contribute to your project,” Ryabinin says. “I personally might want to join the experiment with my own hardware resources, for instance, the GPUs that I have at home. Our goal was just to enable this technique, because honestly, there have been some developments in volunteer computing for deep learning, but we wanted to make it scalable and leverage this approach for high performance training of large neural networks.”
DeDLOC is capable of discovering the proper settings for deep learning models that consist of hundreds of millions of parameters, and potentially even higher, says Ryabinin, who’s also affiliated with HSE University in Russia.
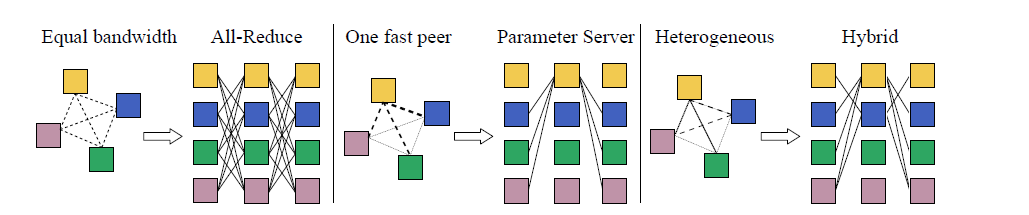
DeDLOC creators utilize different setups to optimize averaging of gradients when training a neural network (Source: DeDLOC paper)
The researchers described DeDLOC in a June paper, titled simply “Distributed Deep Learning In Open Collaborations.” While distributed, grid-style computing is a well-understood approach, there were three main obstacles that had to be overcome to make this work for training large models, according to the paper, which also included contributors from the company Hugging Face, the Moscow Institute of Physics and Technology, the University of Toronto, and the Vector Institute, also based in Toronto.
“First, devices that contribute to collaborative experiments can range from GPU servers and high-end workstations to consumer-grade computers and even smartphones,” the researchers wrote. “Second, most of these devices use household Internet connection with limited bandwidth and low reliability. Third, participants in such projects often donate their hardware part-time, joining and leaving the experiment at will.”
The heart of DeDLOC is an algorithm that enables users to adapt the distributed training workload to the diverse conditions of volunteer nodes. According to the pre-print, DeDLOC uses several well-known methods to discover the proper hyperparameter settings.
“Depending on the infrastructure, DeDLOC can recover parameter servers, All-Reduce SGD, decentralized SGD, BytePS, or an intermediate strategy that combines all of them,” they write in the paper. “Using this algorithm, we propose a system for collaborative training designed to accommodate a large number of heterogeneous devices with uneven compute, bandwidth, reliability, and network capabilities.”

Can grid computing democratize deep learning? (Cagkan-Sayin/Shutterstock)
DeDLOC ensures consistency when training in an inconsistent grid by implementing synchronous data-parallel training with fixed hyperparameters, regardless of the number of collaborators.
“In order to compensate for relatively slow communication, we adopt training with extremely large batches, which allows peers to communicate less frequently,” the researchers write in the paper “This strategy also provides a natural way to deal with heterogeneous hardware: each device accumulates gradients at its own pace until the collaboration reaches the target batch size.”
Once ready, the collaborators exchange their gradients and perform one optimizer step, the paper continues. “Using synchronous updates makes DeDLOC mathematically equivalent to large-batch training on a regular HPC cluster,” it says.
DeDLOC implements a “swarm” like architecture, replete with a distributed hash table, in order to deal with flakey volunteers, although a few rock-steady GPU-less “backbone” nodes are required for welcoming new collaborators and performing administrative duties, such as storing checkpoints and tracking learning curves, the paper says. The worker nodes are assigned to either compute gradients or aggregate gradients computed by others; sometimes they do both.
Getting all these disparate volunteer devices to work together in a distributed, grid-like environment is not simple, Ryabinin says.
“The innovation that we’re bringing is that averaging across all your GPUs when your GPUs are connected across the Internet and some of them might fail in the process,” he says. “It’s highly non-trivial. And we wanted to propose an algorithm for the entire training procedure that would actually be fault tolerant in that sense.”

Training of the sahajBERT model using the collaborative DeDLOC method took approximately the same amount of time (8 days) as the baseline using 8 Nvidia V100 GPUs (Source: DeDLOC paper)
To prove their approach, the researchers trained several deep learning models using their DeDLOC system, including SWaV ResNet-50 on an unlabeled ImageNet data set. They also trained ALBERT-large language model on the WikiText-103 dataset. Finally, they trained an ALBERT-large model on a corpus that consisted of words in the Bengali language. With 91 unique devices from 40 volunteers involved in training sahajBERT, the model converged after eight days of training. That was 1.8x faster than a cluster with eight Nvidia V100 GPUs, they said.
“The goal is to eventually enable training of very large neural networks, maybe the size of GPT-3 or maybe even larger, with this technology,” Ryabinin says. “We have been gradually trying to move to this target, and right now we can collaboratively train something that can rival the size of BERT.”
The current limitation on DeDLOC is probably about 1 billion parameters, says Ryabinin. Considering that GPT-3 consists of 175 billion parameters, DeDLOC has a ways to go (although Ryabinin notes that, due to parameter sharing, DeDLOC models can compete with neural networks 20 their size).
At the end of the day, thanks to the ability to make use of computer processing capacity that would otherwise sit idle, DeDLOC has the potential to unlock a massive amount of latent capacity, and that’s great news for smaller organizations without the wherewithal to buy or rent massive HPC systems.
Related Items:
Nvidia Inference Engine Keeps BERT Latency Within a Millisecond
Getting Hyped for Deep Learning Configs
The Chip Shortage Seems To Be Impacting AI Workloads in the Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States