

August 24, 2021
Hazelcast Platform to Bring Historical, Real-Time Data Together

(Peshkova/Shutterstock)
Hazelcast is best known as a developer of in-memory data grid (IMDB) technology, a RAM-loving layer for speeding up operational applications. But with the Hazelcast Platform launch currently slated for September, the San Mateo, California company is moving beyond the IMDG and into the realm of real-time applications that combine historical and real-time data for a range of use cases.
The Hazelcast Platform essentially is the combination of the Hazelcast IMDG with Hazelcast Jet, the real-time stream processing application that it introduced about four years ago, says Manish Devgan, Hazelcast’s new chief product officer. By combining the real-time and historical products together into a single offering, it will reduce integration headaches, minimize data movement, and streamline DevOps projects to unleash the power of data.
“The last thing you want to do in a distributed system is move data around,” Devgan tells Datanami. “So instead of the client saying, ‘Hey you’re pulling all that data into the client,’ you’re saying, I got this query or this compute function, and I’m going to send the compute to where the data is living. So that’s why we call it in situ data.”
This type of in-situ processing is very powerful because it enables customers to bring fresh, real-time data to bear on the historical and operational data they already are storing in the IMDB cluster. As Devgan sees it, that opens up a slew of new analytics use cases.
“You can now begin to see that the category of applications went from purely operational, transactional application to more applications which are now doing analytics as well,” Devgan says. “It’s a little bit of paradigm shift here where you have a lot of insights to be had in the operational data, which is going through your application, so why don’t I do analytics right there?”
Instead of building pipelines to move data from transactional systems to analytical systems–or to cloud data lakes like S3 or ADLS, which can then be queried using a variety of tools–Hazelcast is responding to customer demands for keeping the data movement to a minimum. That also helps to boost latency for time-critical decision making.
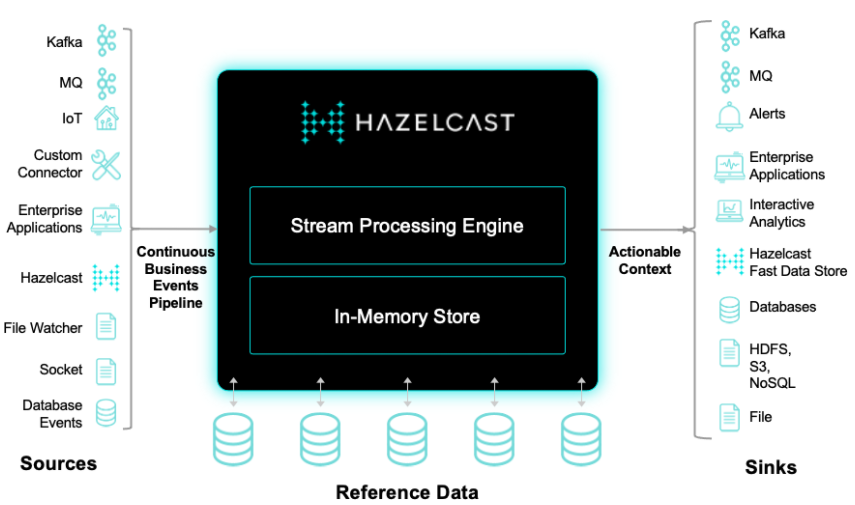
The new Hazelcast Platform (available next month) combines real-time and historical data processing (Source: Hazelcast)
“You see that a lot of operational data stores have data pipelines, where they move the data from this expensive operational store to maybe a workload on S3 or ADLS on Azure, and then you bring do the processing,” Devgan says. “But we have customers saying, we don’t want to do that.”
Large companies, like Netflix, have the engineering resources to build these types of real-time applications, Devgan says. But smaller firms largely have struggled to deliver the types of compelling, data-driven experiences that customers are increasingly asking for during the current bout of COVID-fueled digitization.
“We are trying to lower the bar, or democratize this concept of building real time applications on the data which is going through to your system,” Devgan says. “You now access data fast. Who cares? How are you moving the needle for the business? How are you able to create opportunity? How can you detect and respond to threats and opportunities on real-time data? I think that fundamentally changes the way how people build applications.”
With the platform approach, Hazelcast is aiming to consolidate the number of different runtimes that traditionally are necessary to build these types of systems. Last year at this time, the IMDG and Jet were separate products in Hazelcast’s lineup. But instead of separate products, they’re all part of the same cluster, which minimizes the number of things that can go wrong, Devgan says.
“So there’s one cluster. You get one product. You have one deployment, and that does both your data storage, your data processing, as well as inferencing, if you are going to interference from a trained machine learning model,” Devgan says. “It’s basically the simplification. That’s a big, big deal for us, because our vision is to democratize the building of these real-time apps.”
With an abundance of source (and sink) connectors for streaming systems like Kafka, Kinesis, Pulsar, and message queue systems (not to mention sockets, file watchers, and database event logs), relevant data can be streamed into the stream processing engine component of the Hazelcast Platform (also known as Jet). The real-time data can be blended with historical data stored in the in-memory store, and the resulting data can be queried to give customers the most up-to-date intelligence.![]()
Developers will create applications for Hazelcast Platform using the software development kits (SDKs) for Java, C#, Go, Node.js, Python and C++. They will also be able to leverage user-defined functions to reuse existing code, the company says. The Hazelcast Platform will also utilize directed acyclic graph (DAG) techniques for developing business logic atop the nodes in the cluster.
Hazelcast announced the Hazelcast Platform in July, and said at the time that it was planning to launch the product in August. That timetable has shifted somewhat, and now the plan is for Hazelcast Platform to become generally available in September, Devgan says.
As part of the Hazelcast Platform launch, the company also introduced an update to its core processing engine. In Hazelcast 5.0, the product gains two main functions: the ability to persist data to disk for the purposes of disaster recovery, as well as support for SQL processing on streaming data.
Regarding the SQL support, Hazelcast added:
“With the unification of the Hazelcast real-time stream processing engine and a high-performance data store, enterprises can now combine historical data, event data and file-based data with a single query with microsecond latency. In this approach, the streaming engine is able to pre-process data as it is ingested while the in-memory compute can analyze and act upon the insights in real-time. The unified data can also be fed by the streaming engine into machine learning code for real-time inference.”
This release also paves the way for Hazelcast’s upcoming serverless offering, which will provide auto-scaling capabilities that adapt to customer workloads, and which will further reduce the surface area that customers are responsible for managing.
Related Items:
Stream Processing Is a Great Addition to Data Grid, Hazelcast Finds
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States