

August 20, 2021
Consumer Analytics Using NLP and AI in the HPC Cloud
(Pixelliebe/Shutterstock)
Customers and shoppers have benefited greatly from advances in Internet connectivity in recent years. Rapidly growing e-commerce firms have yielded actual big data as a result of these developments. The enormous popularity of big data on social media allows buyers to express their opinions and views on a wide range of topics, such as the state of the economy, or to express their unhappiness with specific products or services, or to express their joy with their purchases.
A significant number of consumer comments and product evaluations provide a wealth of useful information and have recently emerged as important resource for both consumers and businesses. Consumers frequently seek quality information from online reviews before purchasing a product, and many businesses use online reviews as crucial input for their products, marketing, and customer relationship management.
Therefore, understanding the psychology behind online consumer behaviour became the key to compete in today’s markets which are characterized by ever-increasing competition and globalization.
Sentiment analysis and text analysis are applications of big data analysis, which aim to aggregate and extract emotions and feelings from many types of reviews. These big data which is growing exponentially are mainly available in an unstructured format, making it impossible for an interpretation with human efforts. As a result, employing natural language processing (NLP) machine learning, which focuses on gathering facts and opinions from the huge amount of information available on the internet, is crucial.
This article, based on a more extensive UberCloud case study, presents the application of an NLP – machine learning model to predict sentiments based on consumers’ product review evaluations retrieved from social media and e-commerce websites.
The NLP process consists of several steps:
- Data pre-processing and feature extraction, whereby your text is converted into a predictable and analysable format for your task. It can also help you extract features to understand the distribution of the review text. Tokenization, lower casing, stop words removal, stemming, lemmatization and parts-of-speech tagging are some of the stages involved in data pre-processing and feature extraction.
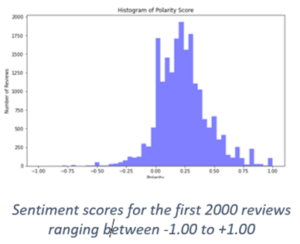
- Ssentiment analysis is performed on each review, categorizing it as excellent or poor, and then sentiments are generated. Sentiment score is a function of polarity and subjectivity. Both parameters are extracted from the review text using NLP algorithms in order to understand the overall sentiment.
The sign of the polarity score is commonly used to infer whether the overall sentiment is positive, neutral, or negative. Polarity is a float in the range [-1,1], where 1 represents a positive statement and -1 represents a negative statement. Subjective sentences generally refer to personal opinion, emotion, or judgement, whereas objective sentences refer to factual information.
- Topic Modelling is used to find themes of interest from a set of review data. These are aspects, and there could be multiple words for the same aspect. It allows search engines to focus on the most important topics in documents. The Latent Dirichlet Allocation (LDA) algorithm, a type of unsupervised learning that considers a document to be a bag of words, is used to analyse topics and generate the probability of occurrence of topics in a document based on the words.
From all the steps of the overall NLP process, topic modelling (the LDA algorithm) is by far the most compute intensive part of the process, and while the other steps (data cleansing and feature engineering, data visualization, sentiment analysis, and predictive analysis) are almost independent of the number of reviews, the effort for topic modelling increases exponentially with increasing number of reviews. Therefore, we were looking for a highly parallel version of the LDA algorithm that can run highly efficiently on HPC systems on premise or in the HPC Cloud (e.g., AWS, Azure, Google GCP, see below).
- Algorithm development, or creating a predictive model that can predict and classify any input review statement using machine learning techniques that leverage statistical methods to compute sentiment scores. They refine their own rules by repeated training based on the training data they are supplied. The model’s accuracy and validation become critical criteria for algorithm selection. The predictive model can be developed using both supervised and unsupervised learning methods.
This research addresses the fundamental challenge of customer behaviour by utilizing advanced machine learning algorithms that democratize and enable real-time access to key insights for your niche. It is a useful resource for assessing affective information in social platforms and ecommerce channels, as it relies not only on domain-specific keywords but also on common sense knowledge that allows for extrapolation of cognitive and affective information connected with natural language text.
Performance Benchmarking on Workstation and HPC Cloud
The NLP – machine learning algorithm for e-commerce is a very compute intensive technique, especially the LDA algorithm, as already mentioned above. Therefore, to complete the study, we have first run a performance analysis by using a high-performance desktop machine that has 16 CPU Cores and 32 GB RAM. The performance analysis was conducted to study the computing system requirement for running up to 20 million review data with the following benchmark results:
The effort for the topic modelling increases exponentially, due to the LDA algorithm. To overcome such a disadvantage, we found parallel LDA topic modeling methods e.g. based on MapReduce architecture using a distributed programming model, that is, the parallel implementation of the LDA topic model by utilizing the Hadoop parallel computing platform. The results show that, when dealing with large amounts of reviews, this parallel method can get near-linear speedup well-suited for on-premise HPC and HPC resources in the cloud.
The HPC environment features the Python-based Anaconda platform that aided in data analysis and the construction of predictive models. As we have shown, dealing with such large volumes of data is a real challenge for this NLP project and demands a significant amount of computing power. Therefore, we found that handling and speeding up the processing of such massive amounts of data is ideally made possible by scaling the algorithm on cloud HPC.
Further experiments conducted in the HPC cloud environment will demonstrate the ability to remotely set up and run big data analysis as well as build AI models in the cloud. Next, the AI-machine learning model setup requirements will be pre-installed in HPC application containers on the UberCloud Engineering Simulation Platform, allowing the user to access and run the NLP workflow without installing any kind of prior set up.
Acknowledgement: The authors would like to thank Praveen Bhat, HPC/Python technology consultant, for his support during the implementation and the benchmarking of the NLP application.
About the authors: Veena Mokal is a Data Science Expert with an MBA in Business Analytics from the Institute of Management Technology in India. Wolfgang Gentzsch is co-founder and president of UberCloud, which develops customized and automated Engineering Simulation Platforms for complex engineering multi-physics simulations, AI/Machine learning, digital twins, data analytics, personalized healthcare, and natural language processing.
Related Items:
Uber-Cloud Project Floats Massive Data
Movie Recommendations with Spark Collaborative Filtering
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States