

July 20, 2021
Nvidia Inference Engine Keeps BERT Latency Within a Millisecond

(metamorworks/Shutterstock)
It’s a shame when your data scientists dial in the accuracy on a deep learning model to a very high degree, only to be forced to gut the model for inference because of resource constraints. But that will seldom be the case with the latest release of Nvidia’s TensorRT inference engine, which can run the BERT-Large transformer model with less than a millisecond of latency, the AI systems maker announced today.
“Traditionally, training for AI is always done in the data center,” Siddharth Sharma, Nvidia’s head of product marketing for AI Software said in a briefing yesterday. “You start with petabytes of data, hundreds of thousands of hours of speech data. You train the model to the highest accuracy that you can. And then once you trained it, you actually throw it over for inference.”
While building the machine learning model arguably is the hardest part of the AI pipeline, the work isn’t done at that point. In fact, once you throw the model over the wall for the software engineers to hammer into a deployable piece of code, there are still some pretty tough choices to make. That’s because the actual inference workload will be running on systems much less powerful than what the model was trained on, including embedded systems, on cars, and other edge devices.
“You’re going to have to make these really hard choices across different parameters as you try to deploy,” Sharma said. “This is kind of one of the biggest challenges in deploying AI applications today: how do you maximize or retain the amount of accuracy that you created from your research teams that you trained with, and then offer it to your customers with the least amount of latency that you can run?”

TensorRT bridges the gap between deep learning development and deployment (image courtesy Nvidia)
TensorRT is Nvidia’s software offering for inference workloads. It supports all kinds of different models, including recurrent neural networks, concurrent neural networks, and the latest transformer models like BERT, developed across a range of languages, from PyTorch to TensorFlow. The product is five years old, and TensorRT version 7, the latest release, still owns several benchmark records for accuracy and efficiency.
Those benchmarks don’t appear to be long for this world, however, as Nvidia is gearing up to deliver TensorRT 8, which improves upon TensorRT 7 in several important ways, including a 2x across-the-board increase in raw performance, a 2x improvement in accuracy using eight-bit integers, and sparsity support on Ampere GPUs.
The enhancements will apply equally well to various AI use cases, including language understanding, computer vision, medical imaging, and recommendation systems, Sharma said. “TensorRT 8 is the most advanced inference solution that is available in the market today,” he said. “And with these achievements, we are very excited to see what developers will be able to do with it.”
The new sparsity support for Nvidia’s Ampere GPUs will provide a way to cut out parts of the model without hurting performance. “So not all parts of deep learning model are equally important,” Sharma said. “Some weights can be turned down to zero. What that means is that … you don’t need to perform computations on those particular weights. That’s interesting because that now leads to fewer computations, lesser memory, lesser bandwidth.”
The 2x boost in accuracy when using eight-bit integers (INT8) comes from something that Nvidia calls Quantization Aware Training (QAT). According to Sharma, Nvidia has figured out a way to squeeze the same level of accuracy when using single-precision, 32-bit numbers (FP32) when using INT8 data format.
“One of the techniques that is used in Tensor RT is to use quantization,” Sharma said. “Instead of using FP32, you try to use a quarter of the memory size for compute. What that means is that your now you’re using maybe a few bits to actually represent these massive numbers, so the discretization is very, very different.
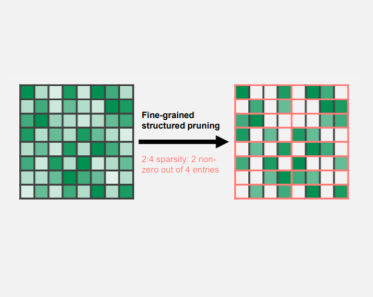
TensorRT brings support for running sparse models on Ampere GPUs
“Because you’re using such fewer numbers, you tend to lose accuracy,” he continued. “But using this technique, you can retain the same accuracy as you had with FP32. This is incredible because it is almost unheard of in the industry. So I would say that this really a remarkable achievement which allows us to keep the accuracy while offering really high performance with TensorRT8.”
The speed and accuracy improvements in TensorRT8 are so great that it will be able to deliver sub-millisecond latency for BERT, Sharma said. That can mean the difference between delivering a successful and satisfying inference experience for users of deep learning products, and settling for a second-rate experience that skimps on accuracy or speed.
“BERT-Large achieves accuracy that surpasses human accuracy baselines across a whole range of different applications,” Sharma said. “But, given it’s large, companies have to make really hard choices on what they’re going to deploy.”
For example, some companies had to shrink the size of their BERT-Large model by 50% or more to keep latency in a manageable range, say two or three milliseconds, Sharma said. So customers with a highly trained 12-layer deep learning model may had to lop off nine of the models, and go to market with a model with just three layers, in order to keep latency within range.
“You can imagine the amount of accuracy that they’re losing,” Sharma said. “Accuracy for search would mean your search systems are not able to understand what you’re saying. Your ad recommendations means that the recommendations that you get are a lot poorer because the descriptions of your objects doesn’t match the query that you ask for. Chat bots when you’re speaking to different applications, they don’t understand nuance. They don’t understand what you’re saying as well. And so it leads to a subpar experience across the board.”
But the capability to deploy an entire BERT-Large model, and keep response time within a millisecond, will have a big impact, he said.
“That is huge and I believe that that is going to lead to a completely new generation of conversationally AI applications, a level of smartness, a level of latency that was just unheard of before,” Sharma said.

Recomendesrs are exploding, according to Nvidia
Nvidia also announced that one of its data science teams has won a series of competitions, including the Booking.com Challenge and which uses millions of anonymized data points to predict the final city a vacationer in Europe would choose to visit, and the SIGIR eCommerce Data Challenge, which tries to detect buying signals in data gathered from customer’s e-commerce sessions.
In late June, Nvidia won its third competition in five months when it came out on top in the ACM RecSys Challenge. This competition involved predicting which tweets Twitter users would like or retweet, based on a training set that included four million data points per day for 28 days. The team had 20GB of memory, a single CPU, a 24-hour time limit. It used 23 hours and 40 minutes, and came up with the winning model.
“We were really on the edge,” said Benedikt Schifferer, one of the Nvidia data science team members.
“The email came in right under the buzzer — 20 minutes later and we would have timed out,” said Chris Deotte, another team member who is also a Kaggle Grand Master.
Later, the team ran the same model on a single Nvidia A100 GPU. It took just five-and-a-half minutes.
Related Items:
Cloudera, Nvidia Team to Speed Cloud AI via Spark
Nvidia’s Jarvis Offers Real-Time Machine Translation
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States