

June 14, 2021
Open Data Hub: A Meta Project for AI/ML Work
Open source software is a critical resource in data science today, but integrating the various open source products together can be a complex task. This is what drove Red Hat to develop Open Data Hub, which brings over two dozen commonly used tools together into a single cohesive framework that simplifies access to AI and machine learning capabilities for data professionals.
Open Data Hub (ODH) originated about five years ago as an internal Red Hat project to simply store large amounts of data so that it was accessible for data scientists to build models, according to Will McGrath, a senior principal product marketing manager at Red Hat. In Red Hat’s case, the engineers chose Ceph, the S3-compatbile object storage system.
After getting a handle on the storage aspect of the data, Red Hat’s team then brought a handful of tools into the equation, starting with Jupyter, Apache Spark, and TensorFlow. The system supported internal Red Hat use cases, such as analyzing log files from customer complaints or for searching the internal knowledgebase, McGrath says.
Eventually, word of ODH’s existence leaked out to a handful of Red Hat customers, who expressed an interest in trying out the software, he says. In 2018, the company made the decision to turn ODH into a full-fledged open source project that could be downloaded and used by the general public, as well as contributed to from the open source community. You can see a short history of the product in this Red Hat video.
Today, Red Hat bills ODH as “a blueprint for building an AI as a service platform.” It follows a general workflow that will be familiar to data professionals, starting with data storage and data ingestion; leading to data analysis, model building; and model training; followed by model validation, deployment, and model serving; with ongoing monitoring and optimization.
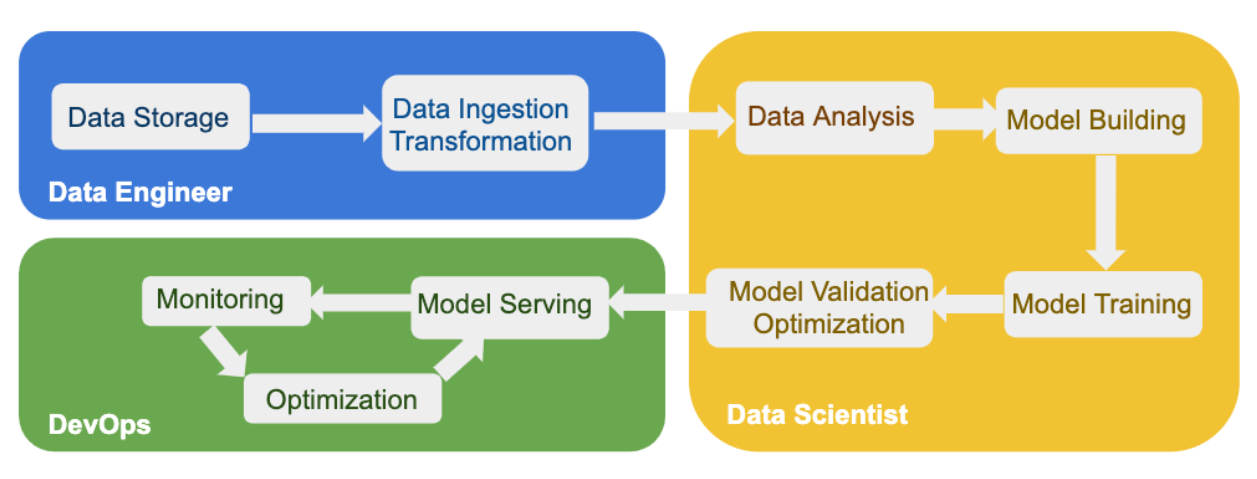
Open Data Hub brings together various software components used to automate tasks in a typical AI workflow
The ODH software runs atop OpenShift, which is Red Hat’s open source distribution of Kubernetes. Support for a version 4.x release of OpenShift is the only real underlying dependency for ODH. Red Hat recommends using Ceph Storage, its open source Ceph platform, but any S3-compatible object store should work.
Atop this Kubernetes and S3/Ceph foundation, ODH brings together many other open source projects that are used by data scientists, data analysts, and data engineers around the world. Depending on which specific data function the user is focused on, ODH can expose different capabilities.
For example, data scientists will find ODH supports Spark, TensorFlow, PyTorch, scikit-learn, Katlib, JupyterHub, Apache Superset, Elyra extensions to Jupyter, and Seldon. Data analysts will find support for Presto, Spark SQL, Elasticsearch, Kafka Streams, Hue, Grafana, and Kibana is built into the product. Data engineers benefit from access to underlying data sources and frameworks like Apache Kafka, Strimzi (a Kafka distribution atop Kubernetes), Kubeflow, Apache Airflow, the Hive metastore, Prometheus, relational databases, and others. There are also tools available for data stewards and DevOps engineers.
“There’s about 20 of these [projects] that we invested in the technology for, and then we stitch them together with a meta operator,” McGrath tells Datanami. “So you can go to a single user interface and download the different components that you want to use. A lot of work has been done to kind of operationalize it, to make it simpler for people to get started doing some data science in an open source way.”
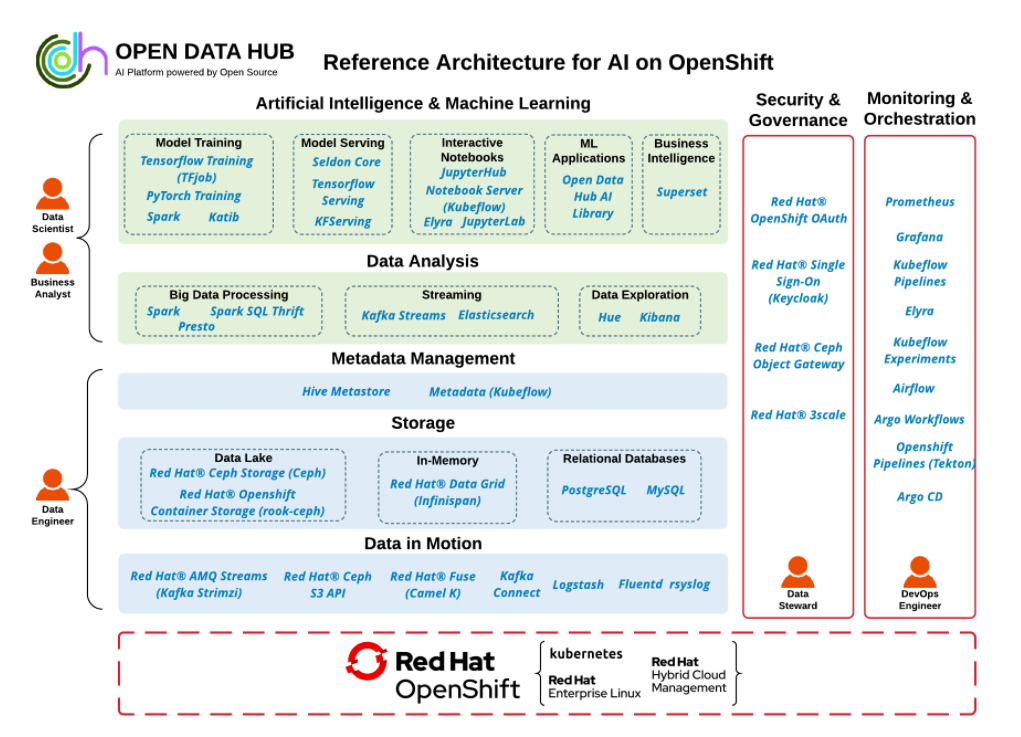
Open Data Hub offers different capabilities for different data personas
The meta operator is a piece of code developed by Red Hat engineers that allows the specific open source project to integrate with the ODH within a Kubernetes environment, McGrath says. These meta operators are built and maintained by Red Hat employees, and they also are designed to take some of the complexity out of upgrading to new releases of the open source projects as they’re released to the public.
“It’s a way to simplify the lifecycle management of the various tools that are part of it,” McGrath explains. “So we’ll have mini operators for things like Spark, on its own, but then the overall operator, the meta-operator, kind of links some of those tools together.”
ODH is maintained by a handful of engineers working out the Office of Red Hat’s CTO, Chris Wright. The project is managed at opendatahub.io, where users can download the software and get started.
Few people who have adopted ODH use every single sub-project, McGrath says. “Customers who have bought into this strategy will adopt certain pieces of it,” he says. “They might say, we like JupyterHub capabilities that you provided as part of it, but we’re going to do our fork on it from Kubeflow from the upstream project.”
As part of their work to support ODH, Red Hat engineers frequently find themselves contributing updates to upstream projects. For example, in February, the company contributed code to Kubeflow version 1.3 to help maintain isolation in multi-user environments. As part of that update, the ODH project is able to adopt the latest changes to Kubeflow faster, McGrath says.
As more organizations started using ODH, Red Hat started getting requests for technical support. The company was receptive to that, and in April, Red Hat unveiled a commercial version of ODH that is sold as a managed service running on AWS.
“People say, hey this is great, we want to buy it. You can’t buy it! It’s open source!” McGrath says. “We have heard…of the hesitancy to use this as a 100% open source project. That’s why we decided to add a commercially supported version of it as well.”![]()
The commercial version, called Red Hat OpenShift Data Science, includes a subset of the capabilities in the open source project, and is focused on Tensorflow, JupyterHub, and PyTorch. The commercial offering also includes integration with four data tool vendors, including IBM Watson, Starburst for Presto/Trino; Anaconda for integration into the Python and R data science community; Seldon for managing the DevOps lifecycle in a machine learning context; and Nvidia for GPU support.
“There’s a lot of great tools out there,” he says. “But [ODH] is for people who are trying to get the sense of what types of tools they want to use, and then if they want to go ahead and invest in some of these commercial offerings, they can do that as well, to give people a nice jumpstart to using open source.”
Backed by the open source community, ODH is continuing to expand. New open source projects, and new features of existing projects, are being added to the ODH project. Commercial open source tool vendors are also welcome to begin working with the ODH community to get their offerings integrated too.
Related Items:
Why You Need Data Transformation in Machine Learning
Machine Learning-Based Real-Time Threat Detection for Banks
What Does IBM’s Acquisition of Red Hat Mean for Open Source?
Applications:
Artificial Intelligence
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States