

May 26, 2021
Databricks Unveils Data Sharing, ETL, and Governance Solutions

(Dennis Diatel/Shutterstock)
Databricks’ primary objective is to build the world’s first enterprise AI platform, which is a noble goal and a work in process. But first things being first, the data is a mess, and it needs some work. To that end, the company today made a slew of announcements at its annual Data + AI Summit, including the launch of Delta Sharing, Delta Live Tables, and the Unity Catalog.
“If you’re going to be successful with AI, then your data world has got to be tight, it’s got to be put together well,” Databricks Vice President of Marketing Joel Minnick said. “Because if your data is not good, there’s no amount of money that you can invest in AI that’s going to make you successful. That’s the core idea behind the lakehouse, [that] we need to find ways to unify data, analytics, and AI onto one single platform.”
It’s also the core idea behind the three announcements that Databricks made this morning at its show. Let’s start the data fun with Delta Sharing.
Delta Sharing
Databricks is billing Delta Sharing as the world’s first open protocol for sharing data in a secure manner. The software, which it has donated to the Linux Foundation, is based on the Delta Lake (also open source), and enables two or more participants to send and receive an arbitrary number of raw data files using Python and SQL.

(Inspiring/Shutterstock)
Minnick explains how it works:
“If you’re sharing Delta out, then you have a Delta Sharing server that’s managing those connections. I will then initiate a request that…I want to get a data set from you. You will give me back a token that says I have access to do that, and then we’ll be able to share data between each other across that protocol.”
The owner of the data retains “full control” over the data, including what is shared and who is allowed to access what parts of the data, Minnick says. The data can be anything, including structured and semi-structured data, like CSV or JSON, as well as unstructured data, like raw text and JPGS. Once the data is in a partners’ environment, it is up to the partner to govern and secure the data.
Databricks has recruited a slew of partners to participate in Delta Sharing, including data providers like S&P, Nasdaq, Pitney Bowes, Safegraph, and the AWS Data Exchange. BI tools like Tableau, Microsoft Power BI, Google Cloud BigQuery, and Starburstj are also queued up to support the new Delta Sharing protocol. On the governance side, Immuta, Privitar, and Collibra are supporting the new protocol on day one.
“The vision is that it will be able to handle all data sets,” Minnick tells Datanami. “Out of the gate what we’re looking at is data sets and files. We are already plotting on the roadmap the ability to be able to also share and govern things like machine learning models [and] things like dashboards. So that really is a solution for all data assets to share across organizations.”
Unity Catalog
Along the same lines as Delta Sharing is the new Unity Catalog, which Databricks says will give users a unified view of all their data assets, including those stored on your own servers and those data assets residing on other cloud repositories that you have access to. Or as Databricks puts it, “the world’s first multi-cloud data catalog for the lakehouse.”

via Shutterstock
A couple of observation drove Databricks to develop the Unity Catalog, Minnick says, the first being that data lakes have not traditionally offered fine-grained access control.
“I can reason at the file level and say, Alex can access this file or he can’t,” Minnick says. “If he can, he gets everything that’s in the file. The only way I can get around that is to copy the file with just the data that’s appropriate and then give you access to that file. But that proliferation of files is one of the big reasons why data lakes end up becoming data swamps.”
Instead of punting on the access control question to the downstream application, which leads to the aforementioned data proliferation problem, Databricks decided to incorporate that fine-grained access control onto the data lake. Unity Catalog provides attribute-level control for any Delta Lake tables, providing precise control over exactly what data users can access and what data they can’t.
“But it also solve a couple of other problems as well,” Minnick adds. “One is about 80% of our customers today are in more than one cloud. That means they have more than one data lake. So the Unity Catalog lets them have one view into all of their data sets across all of their data lakes that they have out there, and be able to put those data sets together in new ways that recognize that some of the data may be in one cloud and some of the data may be in another, but I can express it to you as one data set.”
The Unity Catalog supports the Delta Lake (which is open source) and Delta Sharing (also open source) but the product is not open source; it is part of the Databricks platform that customers must pay for.
And for customers that have already invested in a data catalog from the likes of Collibra or Alation, fear not: Minnick says the Unity Catalog will integrate with them.
Delta Live Tables
The final piece of today’s announcement is Delta Live Tables, which aims to address the fragility of extract, transform, and load (ETL) pipelines that big data customers have come to love (or loathe).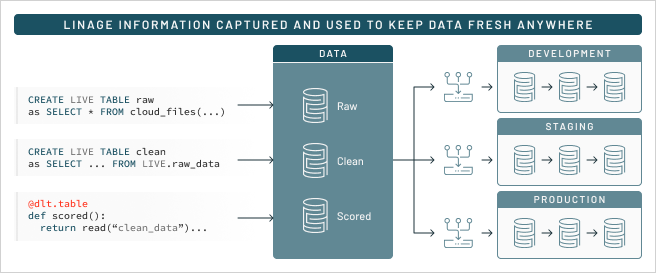
According to Minnick, ETL pipelines are critical for downstream analytics and machine learning applications, but they’re often hidden from users. Delta Lives Tables provides more visibility into the pipelines to ensure good data movement.
“The process of building data pipelines today is incredibly manual and incredibly fragile,” he says. “If the data pipeline fails, that’s annoying. Information is not updated downstream. But an even worse thing is, it’s really hard to test the data that’s flowing through the pipeline, so bad data is allowed to flow through the pipelines all the time.”
Databricks’ solution to that problem is Delta Live Tables, or DLT. The company says DLT provides a declarative development environment that simplifies the creation of data pipelines into Delta Lake. It does that by eliminating much of the engineering, which improves data quality and helps cloud-scale production operations.
“[We said] let’s move the experience of building data pipelines from being an imperative, highly manual process that it is today to make something that’s much more declarative and focus on the outcomes of what these ETL transformations and pipelines are supposed to achieve,” Minnick says.
Using SQL, a user can tell DLT what the data transformation should be, he says. “Using nothing but SQL, I can articulate what these pipelines are supposed to do–what good data looks like–and then what DLT will do is understand the data graph behind the transformations that it’s being asked to do, and traverse that [graph] and understand, what are all the dependencies. So if something changes upstream, I need to automatically make sure that I’m changing it downstream as well so nothing breaks from a dependency perspective.”
DLT gives data engineers a lot of control over the data pipeline, Minnick says. If the DLT pipeline is sending data that’s not expected, it will alert the engineer of the error, or even automatically shut down the pipeline before filling the Delta Lake with bad data. It can also automatically restart the pipeline, since most errors are minor and transient, and scale the underlying server resources up or down as needed.
When a pipeline is restarted, DLT will and automatically backfill the pipe, allowing the job to resume exactly where it left off. And testing DLT pipelines is easy, since the same code that an engineer writes on her laptop can be executed on the server, Minnick says.
“This is something we’ve seen tremendous customer feedback from in the early use here, really making the process of building reliable pipelines fast and easy, and therefore raising the bar on everything that happens downstream to be very simple and manageable,” Minnick says.
Data + AI Summit (formerly Spark + AI Summit) continues tomorrow.
Related Items:
Will Databricks Build the First Enterprise AI Platform?
Databricks Now on Google Cloud
Databricks Edges Closer to IPO with $1B Round
Vendors:
Databricks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States