

April 13, 2021
Cloudera, Nvidia Team to Speed Cloud AI via Spark
Cloud access to GPUs for AI development will expand under a partnership between Cloudera and Nvidia that calls for the data cloud provider to integrate Nvidia’s accelerated Apache Spark 3.0 platform as a way to scale data science workflows.
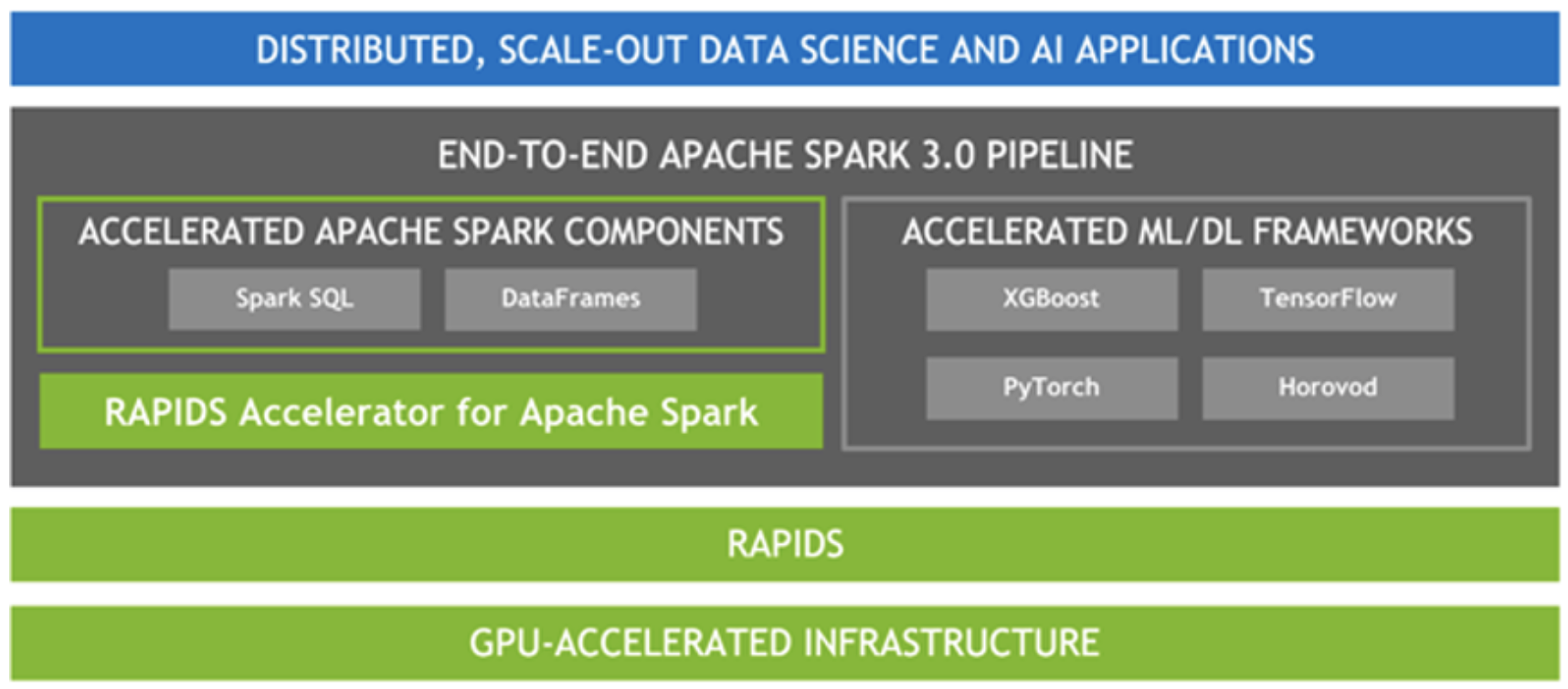
RAPIDS data science libraries running on Nvidia GPUs are designed to help speed emerging AI pipelines to boost the performance of data analytics and machine learning workflows, the partners said Monday (April 12). The partnership was among many announced during this week’s Nvidia GPU Technology Conference.
Cloudera (NYSE: CLDR), Palo Alto, Calif., has been working with Nvidia (NASDAQ: NVDA) since last year to deploy GPU-accelerated AI applications via the RAPIDS accelerator across hybrid and multi-cloud deployments. Spark 3.0 is the first release offering GPU acceleration for analytics and AI workloads.
The RAPIDS ecosystem includes Spark creator Databricks’ web-based platform for big data processing and Anaconda, an open source distribution of the Python and R programming languages for data science and machine learning.
The integration of RAPIDS with the cloud data platform “enables accelerated and scalable big data pre-processing, and workflows without code changes,” Scott McClellan, Nvidia’s senior director of product management, noted in a blog post detailing the AI and data analytics collaboration.
The cloud integration is aimed at enterprise data engineers and data scientists looking to overcome bottlenecks created by torrents of increasingly unstructured data. GPU-accelerated Spark processing accessible via the cloud would help break logjams that slow the training and deployment of machine leaning models, the partners said.
“Apache Spark is a cornerstone of the machine learning and data analytics pipelines enterprises rely on to remain competitive,” McClellan said.
Cloudera said the RAPIDS accelerator for Apache Spark will initially be available this summer on its private data cloud service. The partners plan to roll out other acceleration tools on the Cloudera data cloud, starting in May with accelerated deep learning and machine learning tools.
Source: Nvidia
Built on the CUDA API model, Nvidia’s RAPIDS software libraries allow data science and analytics pipelines to be executed on GPUs via familiar interfaces such a Pandas.
The partners noted that accelerating machine learning workflows has previously been problematic. Accessing GPUs via the Apache Spark accelerator running on the Cloudera’s data platform provides data scientists with native access in the cloud or on-premise to the workflow accelerator through Cloudera’s private cloud infrastructure.
Nvidia said the integration of RAPIDS with machine learning frameworks and the scheduling of GPU jobs via Spark 3.0 GPU enables the acceleration of model training and tuning. “This allows data scientists and [machine learning] engineers to have a unified, GPU-accelerated pipeline for ETL and analytics,” the GPU leader added.
The RAPIDS library coupled with the Apache Spark distributed computing framework is also promoted as accelerating Spark SQL and DataFrame processing via GPUs without code changes.
Recent items:
RAPIDS Momentum Builds with Analytics, Cloud Backing
Cloudera Delivers Private Cloud Amid Public Speculation of Sale
Nvidia Destroys TPCx-BB Benchmark with GPUs
Vendors:
Cloudera
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States